简介
Kubernetes Autoscaling in Production: Best Practices for Cluster Autoscaler, HPA and VPA 未读
自动扩缩容 其实并不复杂,对外暴露一个 设置replicas 的接口即可。 但hpa 提供一个 平台化的能力来 做这件事,是很值得思考的一个点。
Horizontal Pod AutoscalerThe Horizontal Pod Autoscaler automatically scales the number of Pods in a replication controller, deployment, replica set or stateful set based on observed CPU utilization (or, with custom metrics support, on some other application-provided metrics). Note that Horizontal Pod Autoscaling does not apply to objects that can’t be scaled, for example, DaemonSets.
The Horizontal Pod Autoscaler is implemented as a Kubernetes API resource and a controller. The resource determines the behavior of the controller. The controller periodically adjusts the number of replicas in a replication controller or deployment to match the observed average CPU utilization to the target specified by user. PS: 理想状态从一个确定的replicas 变成了 规则
- 面向的k8s object :deployment, replicaset or statefulset
- 扩缩容依据:CPU utilization 和 custom metrics
- 实现:定义了一个hpa resource ,以及对应的 controller; 与一般controller 略微不同的是 周期性执行(默认15s)
hpa 的两个基本要素
- minReplicas/maxRepicas 定义扩缩容的上下限
- Target metrics/ targetValue threshold,选一个或多个指标,定一个阈值,来评估当前的负载,If the metric readings are above this value, and (currentReplicas < maxReplicas), HPA will scale up.
示例
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
scaleTargetRef: # HPA的伸缩对象描述,HPA会动态修改该对象的pod数量
apiVersion: apps/v1
kind: Deployment
name: php-apache
# HPA的最小pod数量和最大pod数量
minReplicas: 1
maxReplicas: 10
# 监控的指标数组,支持多种类型的指标共存
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
获取metric 数据
target共有3种类型:Utilization、Value、AverageValue。Utilization表示平均使用率;Value表示裸值;AverageValue表示平均值。
| api | metric | 已有实现 | |
|---|---|---|---|
| Resource | metrics.k8s.io | cpu/mem | metric-server |
| object/pods | custom.metrics.k8s.io | Prometheus Adapter/ Microsoft Azure Adapter/Google Stackdriver | |
| external | external.metrics.k8s.io |
默认情况下,HorizontalPodAutoscaler控制器从一系列API中检索指标。为了使其能够访问这些API,集群管理员必须确保:
- 该API汇聚层启用
- 相应的API已注册
需要给kube-controller-manager服务增加三个参数:
--horizontal-pod-autoscaler-sync-period=30s \
--horizontal-pod-autoscaler-downscale-delay=3m0s \
--horizontal-pod-autoscaler-upscale-delay=3m0s
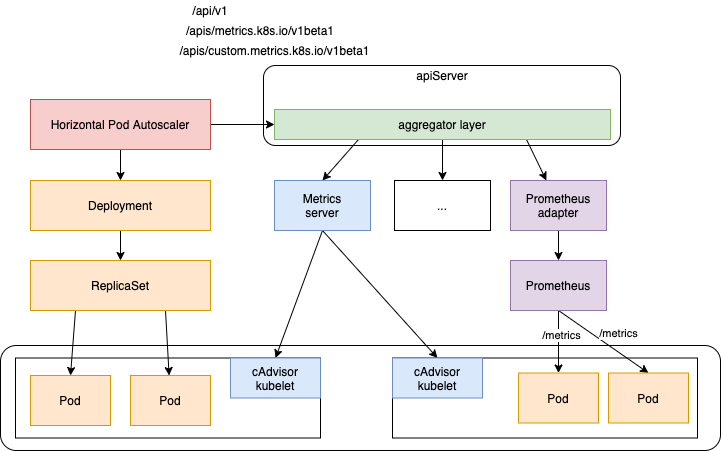
Kubernetes pod autoscaler using custom metrics The Kubernetes HPA is able to retrieve metrics from several APIs out of the box: metrics.k8s.io, custom.metrics.k8s.io , and external.metrics.k8s.io。配置了hpa 之后,HPAController 根据 hpa resource 通过 k8s.io/metrics 库的MetricClient 获取metric 数据
- client-go 是k8s 提供了 访问k8s 核心资源的api库, metric 也自定义了metric 资源(比如PodMetrics/NodeMetrics),并提供
k8s.io/metrics库 来简化访问 - MetricClient 会根据 hpa 中的resource 配置将其转换为 http url(对应上面3个域名)请求 来访问apiserver 获取metric。比如上述示例 type=Object 对应url
https://<apiserver_ip>/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/ingresses/main-route/requests-per-second(可能不对,大概这意思),apiserver 收到该请求后,将其转发到 main-route 对应的 Ingress - MetricClient 与 apiserver 之间,apiserver 与 main-route Ingress 或其它 metric 提供者(一般以pod 运行,以Ingress 或者 Service 对外提供服务)之间 有一些格式约定(请求参数是啥,返回字段是啥等)。规则参照 Resource Metrics API定义了NodeMetrics/PodMetrics/ContainerMetrics Custom Metrics API定义了 MetricValue/MetricValueList External Metrics API 定义了 ExternalMetricValue/ExternalMetricValueList。hpa 做扩缩容决策 需要metric ,任何能提供 metric 的web 组件都可以接入 apiserver
- Resource Metrics API 实现方 Metrics Server
- Custom Metrics API 实现方 Prometheus Adapter , 其本身也可以替代 Metrics Server。 k8s 还提供了一个实现 辅助实现 Custom Metrics API web 服务的库 kubernetes-sigs/custom-metrics-apiserver
- apiserver 可以将 http 请求转发给任何web 服务,除了内嵌的核心资源(及path)由apiserver 自身提供,To register an API, you add an APIService object, which “claims” the URL path in the Kubernetes API. At that point, the aggregation layer will proxy anything sent to that API path to the registered APIService. 具体的说,apiserver 将
custom.metrics.k8s.io和external.metrics.k8s.io的请求 查询APIObject 配置 确定 转到 哪个pod(即其对应的Service或Ingress) 上。
自定义metric 集成
Horizontally autoscale Kubernetes deployments on custom metrics未读
kubernetes-sigs/custom-metrics-apiserver 有一个示例 metric adapter 实现 test-adapter-container
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: custom-metrics-apiserver
name: custom-metrics-apiserver
namespace: custom-metrics
spec:
replicas: 1
selector:
matchLabels:
app: custom-metrics-apiserver
template:
metadata:
labels:
app: custom-metrics-apiserver
name: custom-metrics-apiserver
spec:
serviceAccountName: custom-metrics-apiserver
containers:
- name: custom-metrics-apiserver
image: REGISTRY/k8s-test-metrics-adapter-amd64:latest
imagePullPolicy: IfNotPresent
args:
- /adapter
- --secure-port=6443
- --logtostderr=true
- --v=10
ports:
- containerPort: 6443
name: https
- containerPort: 8080
name: http
volumeMounts:
- mountPath: /tmp
name: temp-vol
volumes:
- name: temp-vol
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
name: custom-metrics-apiserver
namespace: custom-metrics
spec:
ports:
- name: https
port: 443
targetPort: 6443
- name: http
port: 80
targetPort: 8080
selector:
app: custom-metrics-apiserver
部署了deployment 之后,就可以 http://serviceIP:servicePort/api/v1/namespaces/custom-metrics/services/custom-metrics-apiserver/requests-per-second 获取 metric = requests-per-second 数据
apiVersion: apiregistration.k8s.io/v1beta1
kind: APIService
metadata:
name: v1beta1.custom.metrics.k8s.io
spec:
service:
name: custom-metrics-apiserver
namespace: custom-metrics
group: custom.metrics.k8s.io
version: v1beta1
insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100
配置了APIService,就可以 http://api_server/apis/custom.metrics.k8s.io/v1beta1/namespaces/custom-metrics/services/custom-metrics-apiserver/requests-per-second 获取 metric = requests-per-second 数据
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-deployment
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
minReplicas: 1
maxReplicas: 10
metrics:
- type: Object
object:
metric:
name: test-metric
describedObject:
apiVersion: v1
kind: Service
name: kubernetes
target:
type: Value
value: 300m
源码分析
启动与初始化
// k8s.io/kubernetes/cmd/kube-controller-manager/app/controllermanager.go
func NewControllerInitializers(loopMode ControllerLoopMode) map[string]InitFunc {
controllers["horizontalpodautoscaling"] = startHPAController
...
}
// k8s.io/kubernetes/cmd/kube-controller-manager/app/autoscaling.go
func startHPAController(ctx ControllerContext) (http.Handler, bool, error) {
...
return startHPAControllerWithRESTClient(ctx)
}
func startHPAControllerWithRESTClient(ctx ControllerContext) (http.Handler, bool, error) {
clientConfig := ctx.ClientBuilder.ConfigOrDie("horizontal-pod-autoscaler")
hpaClient := ctx.ClientBuilder.ClientOrDie("horizontal-pod-autoscaler")
metricsClient := metrics.NewRESTMetricsClient(
resourceclient.NewForConfigOrDie(clientConfig),
custom_metrics.NewForConfig(clientConfig, ctx.RESTMapper, apiVersionsGetter),
external_metrics.NewForConfigOrDie(clientConfig),
)
return startHPAControllerWithMetricsClient(ctx, metricsClient)
}
func startHPAControllerWithMetricsClient(ctx ControllerContext, metricsClient metrics.MetricsClient) (http.Handler, bool, error) {
hpaClient := ctx.ClientBuilder.ClientOrDie("horizontal-pod-autoscaler")
hpaClientConfig := ctx.ClientBuilder.ConfigOrDie("horizontal-pod-autoscaler")
scaleKindResolver := scale.NewDiscoveryScaleKindResolver(hpaClient.Discovery())
scaleClient, err := scale.NewForConfig(hpaClientConfig, ctx.RESTMapper, dynamic.LegacyAPIPathResolverFunc, scaleKindResolver)
go podautoscaler.NewHorizontalController(
hpaClient.CoreV1(),
scaleClient,
hpaClient.AutoscalingV1(),
ctx.RESTMapper,
metricsClient,
ctx.InformerFactory.Autoscaling().V1().HorizontalPodAutoscalers(),
ctx.InformerFactory.Core().V1().Pods(),
// 扩缩容计算周期,默认15s
ctx.ComponentConfig.HPAController.HorizontalPodAutoscalerSyncPeriod.Duration,
// 两次缩容之间的间隔,防止抖动 默认5m
ctx.ComponentConfig.HPAController.HorizontalPodAutoscalerDownscaleStabilizationWindow.Duration,
// 如果 ratio 比较接近1,则忽略扩缩容,描述ratio 与1 接近的程度,默认0.1
ctx.ComponentConfig.HPAController.HorizontalPodAutoscalerTolerance,
// 用于设置 Pod 的初始化时间, 在此时间内的 Pod,CPU 资源度量值将不会被采纳。默认5m
ctx.ComponentConfig.HPAController.HorizontalPodAutoscalerCPUInitializationPeriod.Duration,
// 设置pod 的准备时间,在此时间内的 Pod 统统被认为未就绪,默认30s
ctx.ComponentConfig.HPAController.HorizontalPodAutoscalerInitialReadinessDelay.Duration,
).Run(ctx.Stop)
return nil, true, nil
}
// k8s.io/kubernetes/pkg/controller/podautoscaler/horizontal.go
func NewHorizontalController(
evtNamespacer v1core.EventsGetter,
scaleNamespacer scaleclient.ScalesGetter,...
) *HorizontalController {
hpaController := &HorizontalController{...}
hpaInformer.Informer().AddEventHandlerWithResyncPeriod(
// 将hpa resource 加入到 queue 中
cache.ResourceEventHandlerFuncs{
AddFunc: hpaController.enqueueHPA,
UpdateFunc: hpaController.updateHPA,
DeleteFunc: hpaController.deleteHPA,
},
resyncPeriod,
)
hpaController.hpaLister = hpaInformer.Lister()
hpaController.podLister = podInformer.Lister()
replicaCalc := NewReplicaCalculator(...)
hpaController.replicaCalc = replicaCalc
}
从HorizontalController到ReplicaCalculator
// k8s.io/kubernetes/pkg/controller/podautoscaler/horizontal.go
func (a *HorizontalController) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer a.queue.ShutDown()
if !cache.WaitForNamedCacheSync("HPA", stopCh, a.hpaListerSynced, a.podListerSynced) {
return
}
// start a single worker (we may wish to start more in the future)
go wait.Until(a.worker, time.Second, stopCh)
<-stopCh
}
func (a *HorizontalController) worker() {
for a.processNextWorkItem() {
}
}
func (a *HorizontalController) processNextWorkItem() bool {
...
deleted, err := a.reconcileKey(key.(string))
...
}
func (a *HorizontalController) reconcileKey(key string) (deleted bool, err error) {
namespace, name, err := cache.SplitMetaNamespaceKey(key)
hpa, err := a.hpaLister.HorizontalPodAutoscalers(namespace).Get(name)
return false, a.reconcileAutoscaler(hpa, key)
}
func (a *HorizontalController) reconcileAutoscaler(hpav1Shared *autoscalingv1.HorizontalPodAutoscaler, key string) error {
// hpa 对象
hpa := hpaRaw.(*autoscalingv2.HorizontalPodAutoscaler)
// 待扩缩容的对象
scale, targetGR, err := a.scaleForResourceMappings(hpa.Namespace, hpa.Spec.ScaleTargetRef.Name, mappings)
currentReplicas := scale.Spec.Replicas
// 计算 desiredReplicas
desiredReplicas := int32(0)
minReplicas = *hpa.Spec.MinReplicas
rescale := true
if scale.Spec.Replicas == 0 && minReplicas != 0 {
// Autoscaling is disabled for this resource
} else if currentReplicas > hpa.Spec.MaxReplicas {
rescaleReason = "Current number of replicas above Spec.MaxReplicas"
desiredReplicas = hpa.Spec.MaxReplicas
} else if currentReplicas < minReplicas {
rescaleReason = "Current number of replicas below Spec.MinReplicas"
desiredReplicas = minReplicas
} else {
metricDesiredReplicas, metricName, metricStatuses, metricTimestamp, err = a.computeReplicasForMetrics(hpa, scale, hpa.Spec.Metrics)
rescaleMetric := ""
if metricDesiredReplicas > desiredReplicas {
desiredReplicas = metricDesiredReplicas
rescaleMetric = metricName
}
if desiredReplicas > currentReplicas { rescaleReason = fmt.Sprintf("%s above target", rescaleMetric) }
if desiredReplicas < currentReplicas { rescaleReason = "All metrics below target" }
if hpa.Spec.Behavior == nil {
desiredReplicas = a.normalizeDesiredReplicas(hpa, key, currentReplicas, desiredReplicas, minReplicas)
} else {
desiredReplicas = a.normalizeDesiredReplicasWithBehaviors(hpa, key, currentReplicas, desiredReplicas, minReplicas)
}
rescale = desiredReplicas != currentReplicas
}
// 如果需要扩缩容
if rescale {
scale.Spec.Replicas = desiredReplicas
_, err = a.scaleNamespacer.Scales(hpa.Namespace).Update(context.TODO(), targetGR, scale, metav1.UpdateOptions{})
} else { desiredReplicas = currentReplicas }
return a.updateStatusIfNeeded(hpaStatusOriginal, hpa)
}
上述代码 描述了宏观逻辑:从queue 中取出 hpa resource,计算是否 rescale 以及 desiredReplicas,并实施。
// k8s.io/kubernetes/pkg/controller/podautoscaler/horizontal.go
// computeReplicasForMetrics computes the desired number of replicas for the metric specifications listed in the HPA,
// returning the maximum of the computed replica counts, a description of the associated metric, and the statuses of
// all metrics computed.
func (a *HorizontalController) computeReplicasForMetrics(hpa *autoscalingv2.HorizontalPodAutoscaler, scale *autoscalingv1.Scale,metricSpecs []autoscalingv2.MetricSpec) (replicas int32, metric string, ...) {
selector, err := labels.Parse(scale.Status.Selector)
specReplicas := scale.Spec.Replicas
statusReplicas := scale.Status.Replicas
statuses = make([]autoscalingv2.MetricStatus, len(metricSpecs))
invalidMetricsCount := 0
for i, metricSpec := range metricSpecs {
replicaCountProposal, metricNameProposal, timestampProposal, condition, err := a.computeReplicasForMetric(hpa, metricSpec, specReplicas, statusReplicas, selector, &statuses[i])
// 每个metric 计算一个 需要扩缩容的数量,去最大值 作为最终的扩缩容的replicas
if err == nil && (replicas == 0 || replicaCountProposal > replicas) {
timestamp = timestampProposal
replicas = replicaCountProposal
metric = metricNameProposal
}
}
// If all metrics are invalid return error and set condition on hpa based on first invalid metric.
if invalidMetricsCount >= len(metricSpecs) {
return 0, "", statuses, ...)
}
return replicas, metric, statuses, timestamp, nil
}
// Computes the desired number of replicas for a specific hpa and metric specification,
// returning the metric status and a proposed condition to be set on the HPA object.
func (a *HorizontalController) computeReplicasForMetric(hpa *autoscalingv2.HorizontalPodAutoscaler, spec autoscalingv2.MetricSpec,specReplicas, statusReplicas int32, selector labels.Selector, ...) (replicaCountProposal int32, metricNameProposal string,...) {
switch spec.Type {
case autoscalingv2.ObjectMetricSourceType:
metricSelector, err := metav1.LabelSelectorAsSelector(spec.Object.Metric.Selector)
replicaCountProposal, timestampProposal, metricNameProposal, condition, err = a.computeStatusForObjectMetric(specReplicas, statusReplicas, spec, hpa, selector, status, metricSelector)
case autoscalingv2.PodsMetricSourceType:
metricSelector, err := metav1.LabelSelectorAsSelector(spec.Pods.Metric.Selector)
replicaCountProposal, timestampProposal, metricNameProposal, condition, err = a.computeStatusForPodsMetric(specReplicas, spec, hpa, selector, status, metricSelector)
case autoscalingv2.ResourceMetricSourceType:
replicaCountProposal, timestampProposal, metricNameProposal, condition, err = a.computeStatusForResourceMetric(specReplicas, spec, hpa, selector, status)
case autoscalingv2.ExternalMetricSourceType:
replicaCountProposal, timestampProposal, metricNameProposal, condition, err = a.computeStatusForExternalMetric(specReplicas, statusReplicas, spec, hpa, selector, status)
default:
...
return 0, "", time.Time{}, condition, err
}
return replicaCountProposal, metricNameProposal, ...
}
// computeStatusForPodsMetric computes the desired number of replicas for the specified metric of type PodsMetricSourceType.
func (a *HorizontalController) computeStatusForPodsMetric(currentReplicas int32, metricSpec autoscalingv2.MetricSpec, hpa *autoscalingv2.HorizontalPodAutoscaler, selector labels.Selector, status *autoscalingv2.MetricStatus, metricSelector labels.Selector) (replicaCountProposal int32, ...) {
replicaCountProposal, utilizationProposal, timestampProposal, err := a.replicaCalc.GetMetricReplicas(currentReplicas, metricSpec.Pods.Target.AverageValue.MilliValue(), metricSpec.Pods.Metric.Name, hpa.Namespace, selector, metricSelector)
*status = autoscalingv2.MetricStatus{...}
return replicaCountProposal, timestampProposal, fmt.Sprintf("pods metric %s", metricSpec.Pods.Metric.Name), autoscalingv2.HorizontalPodAutoscalerCondition{}, nil
}
上述代码负责将计算逻辑转移到 ReplicaCalculator 进行
计算规则
整体的计算规则如下
// ratio 在一定范围内会被忽略(即认为波动太小)
ratio = currentMetricValue / desiredMetricValue
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
// k8s.io/kubernetes/pkg/controller/podautoscaler/replica_calculator.go
func (c *ReplicaCalculator) GetMetricReplicas(currentReplicas int32, targetUtilization int64, metricName string, namespace string, selector labels.Selector, metricSelector labels.Selector) (replicaCount int32, utilization int64, ...) {
metrics, timestamp, err := c.metricsClient.GetRawMetric(metricName, namespace, selector, metricSelector)
replicaCount, utilization, err = c.calcPlainMetricReplicas(metrics, currentReplicas, targetUtilization, namespace, selector, v1.ResourceName(""))
return replicaCount, utilization, timestamp, err
}
// calcPlainMetricReplicas calculates the desired replicas for plain (i.e. non-utilization percentage) metrics.
func (c *ReplicaCalculator) calcPlainMetricReplicas(metrics metricsclient.PodMetricsInfo, currentReplicas int32, targetUtilization int64, namespace string, selector labels.Selector, resource v1.ResourceName) (replicaCount int32, utilization int64, err error) {
podList, err := c.podLister.Pods(namespace).List(selector)
if len(podList) == 0 {
return 0, 0, fmt.Errorf("no pods returned by selector while calculating replica count")
}
// PodPending/Unready/HorizontalPodAutoscalerCPUInitializationPeriod/HorizontalPodAutoscalerInitialReadinessDelay 的pod 加入到ignoredPods(即这些pod的metric 即便有也不能采信),找不到metric 数据的pod 加入到 missingPods,没有上述问题的pod 由 readyPodCount 计数
readyPodCount, ignoredPods, missingPods := groupPods(podList, metrics, resource, c.cpuInitializationPeriod, c.delayOfInitialReadinessStatus)
// ignoredPods 不参与 第一轮使用率计算
removeMetricsForPods(metrics, ignoredPods)
if len(metrics) == 0 {
return 0, 0, fmt.Errorf("did not receive metrics for any ready pods")
}
// 先根据 包含可以采信的metric 数据的pod 计算一次使用率
usageRatio, utilization := metricsclient.GetMetricUtilizationRatio(metrics, targetUtilization)
rebalanceIgnored := len(ignoredPods) > 0 && usageRatio > 1.0 // 扩容 且有pod 的metric 数据无法采信
/*
等同于
if len(missingPods) == 0 { // 所有的pod 都有metric 数据
// 如果 所有的pod metric 都可以采信 或者 处于缩容状态
if len(ignoredPods) <= 0 || usageRatio <= 1.0{}
}
*/
if !rebalanceIgnored && len(missingPods) == 0 {
if math.Abs(1.0-usageRatio) <= c.tolerance {
// return the current replicas if the change would be too small
return currentReplicas, utilization, nil
}
// if we don't have any unready or missing pods, we can calculate the new replica count now
return int32(math.Ceil(usageRatio * float64(readyPodCount))), utilization, nil
}
// 补全 missingPods 数据
if len(missingPods) > 0 {
if usageRatio < 1.0 { // 使用率小于1 缩容场景
// on a scale-down, treat missing pods as using 100% of the resource request
for podName := range missingPods {
metrics[podName] = metricsclient.PodMetric{Value: targetUtilization}
}
} else { // 使用率大于 1 扩容场景
// on a scale-up, treat missing pods as using 0% of the resource request
for podName := range missingPods {
metrics[podName] = metricsclient.PodMetric{Value: 0}
}
}
}
// 等同于 if len(ignoredPods) > 0 && usageRatio > 1.0
if rebalanceIgnored { // 扩容 且有pod 无法参与判断, 补全ignoredPods 数据
// on a scale-up, treat unready pods as using 0% of the resource request
for podName := range ignoredPods {
metrics[podName] = metricsclient.PodMetric{Value: 0}
}
}
// re-run the utilization calculation with our new numbers
newUsageRatio, _ := metricsclient.GetMetricUtilizationRatio(metrics, targetUtilization)
// 在 tolerance 范围内,usageRatio 和 newUsageRatio 扩缩容偏好 矛盾,则放弃扩缩容
if math.Abs(1.0-newUsageRatio) <= c.tolerance || (usageRatio < 1.0 && newUsageRatio > 1.0) || (usageRatio > 1.0 && newUsageRatio < 1.0) {
// return the current replicas if the change would be too small,
// or if the new usage ratio would cause a change in scale direction
return currentReplicas, utilization, nil
}
// return the result, where the number of replicas considered is
// however many replicas factored into our calculation
return int32(math.Ceil(newUsageRatio * float64(len(metrics)))), utilization, nil
}
整体思路
- 将 pod 分组为 ignoredPods(pod metric 不能采信)/missingPods(pod 没有metric)/readyPods(有可信metric 的pod)
- 先根据 包含可以采信的metric 数据的pod(readyPods) 计算一次使用率
- 如果pod metric 都可以采信,或基于已有的 可采信metric 数据已经确定缩容了,则直接 按公式计算 扩缩容 replicas即可。否则根据 扩缩容场景 来补全 ignoredPods/missingPods 的metric 数据
- 根据扩缩容场景 补全missingPods 的metric 数据,扩容场景下 补全ignoredPods metric 数据
- 此时所有的pod 都有了 真实的或补全的metric 数据,重新计算一次 使用率
- 如果两次计算的使用率 扩缩容偏好 不矛盾 且 扩缩容Ratio 超过 tolerance ,则计算 扩缩容的replicas 并返回
计算的原料——metric
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes/<node-name> 可以拿到一个示例的node metric数据
{
"kind": "NodeMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "192.168.xx.xx",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/192.168.60.96",
"creationTimestamp": "2020-10-13T06:39:03Z"
},
"timestamp": "2020-10-13T06:37:46Z",
"window": "30s",
"usage": {
"cpu": "1792787098n",
"memory": "48306672Ki"
}
}
// k8s.io/kubernetes/pkg/controller/podautoscaler/metrics/interfaces.go
type PodMetric struct {
Timestamp time.Time
Window time.Duration
Value int64
}
type PodMetricsInfo map[string]PodMetric
type MetricsClient interface {
// allows consumers to access resource metrics (CPU and memory) for pods and nodes.
GetResourceMetric(resource v1.ResourceName, namespace string, selector labels.Selector) (PodMetricsInfo, time.Time, error)
GetRawMetric(metricName string, namespace string, selector labels.Selector, metricSelector labels.Selector) (PodMetricsInfo, time.Time, error)
GetObjectMetric(metricName string, namespace string, objectRef *autoscaling.CrossVersionObjectReference, metricSelector labels.Selector) (int64, time.Time, error)
GetExternalMetric(metricName string, namespace string, selector labels.Selector) ([]int64, time.Time, error)
}
// k8s.io/kubernetes/pkg/controller/podautoscaler/metrics/rest_metrics_client.go
type restMetricsClient struct {
*resourceMetricsClient
*customMetricsClient
*externalMetricsClient
}
func (c *resourceMetricsClient) GetResourceMetric(resource v1.ResourceName, namespace string, selector labels.Selector) (PodMetricsInfo, time.Time, error) {
metrics, err := c.client.PodMetricses(namespace).List(context.TODO(), metav1.ListOptions{LabelSelector: selector.String()})
res := make(PodMetricsInfo, len(metrics.Items))
for _, m := range metrics.Items {
podSum := int64(0)
missing := len(m.Containers) == 0
for _, c := range m.Containers {
resValue, found := c.Usage[v1.ResourceName(resource)]
if !found {
missing = true
klog.V(2).Infof("missing resource metric %v for container %s in pod %s/%s", resource, c.Name, namespace, m.Name)
break // containers loop
}
podSum += resValue.MilliValue()
}
if !missing {
res[m.Name] = PodMetric{
Timestamp: m.Timestamp.Time,
Window: m.Window.Duration,
Value: int64(podSum),
}
}
}
timestamp := metrics.Items[0].Timestamp.Time
return res, timestamp, nil
}
解决响应速度问题
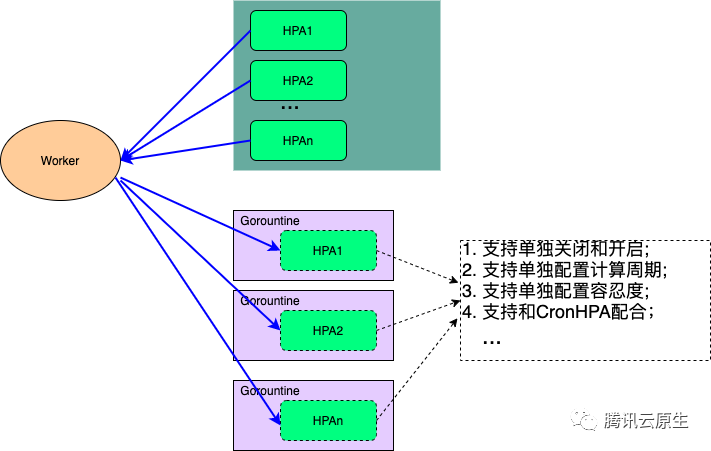
官方的这个HPA Controller在实现的时候用的是一个Gorountine来处理整个集群的所有HPA的计算和同步问题,在集群配置的HPA比较多的时候可能会导致业务扩容不及时的问题,其次官方HPA Controller不支持为每个HPA进行单独的个性化配置。
为了优化HPA Controller的性能和个性化配置问题,我们把HPA Controller单独抽离出来单独部署。同时为每一个HPA单独配置一个Gorountine,并且每一个HPA多可以根据业务的需要进行单独的配置。
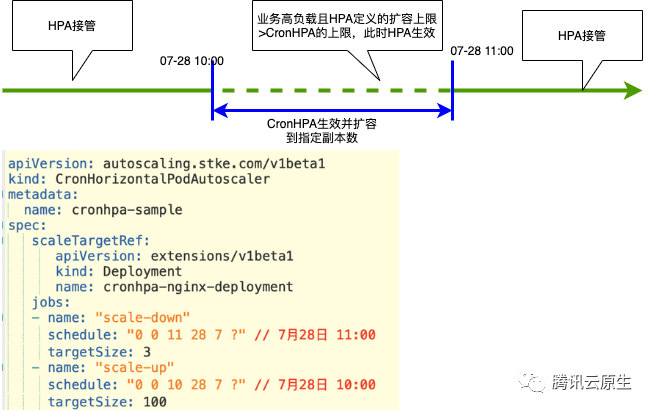
其实仅仅优化HPA Controller还是不能满足一些业务在业务高峰时候的一些需求,比如在业务做活动的时候,希望在流量高峰期之前就能够把业务扩容好。这个时候我们就需要一个定时HPA的功能,为此我们定义了一个CronHPA的CRD和CronHPA Operator。CronHPA会在业务定义的时间进行扩容和缩容,同时还能和HPA一起配合工作。