
前言
jvm 作为 a model of a whole computer,便与os 有许多相似的地方,包括并不限于:
- 针对os 编程的可执行文件,主要指其背后代表的文件格式、编译、链接、加载 等机制
- 可执行文件 的如何被执行,主要指 指令系统及之上的 方法调用等
- 指令执行依存 的内存模型
这三者是三个不同的部分,又相互关联,比如jvm基于栈的解释器与jvm 内存模型 相互依存。
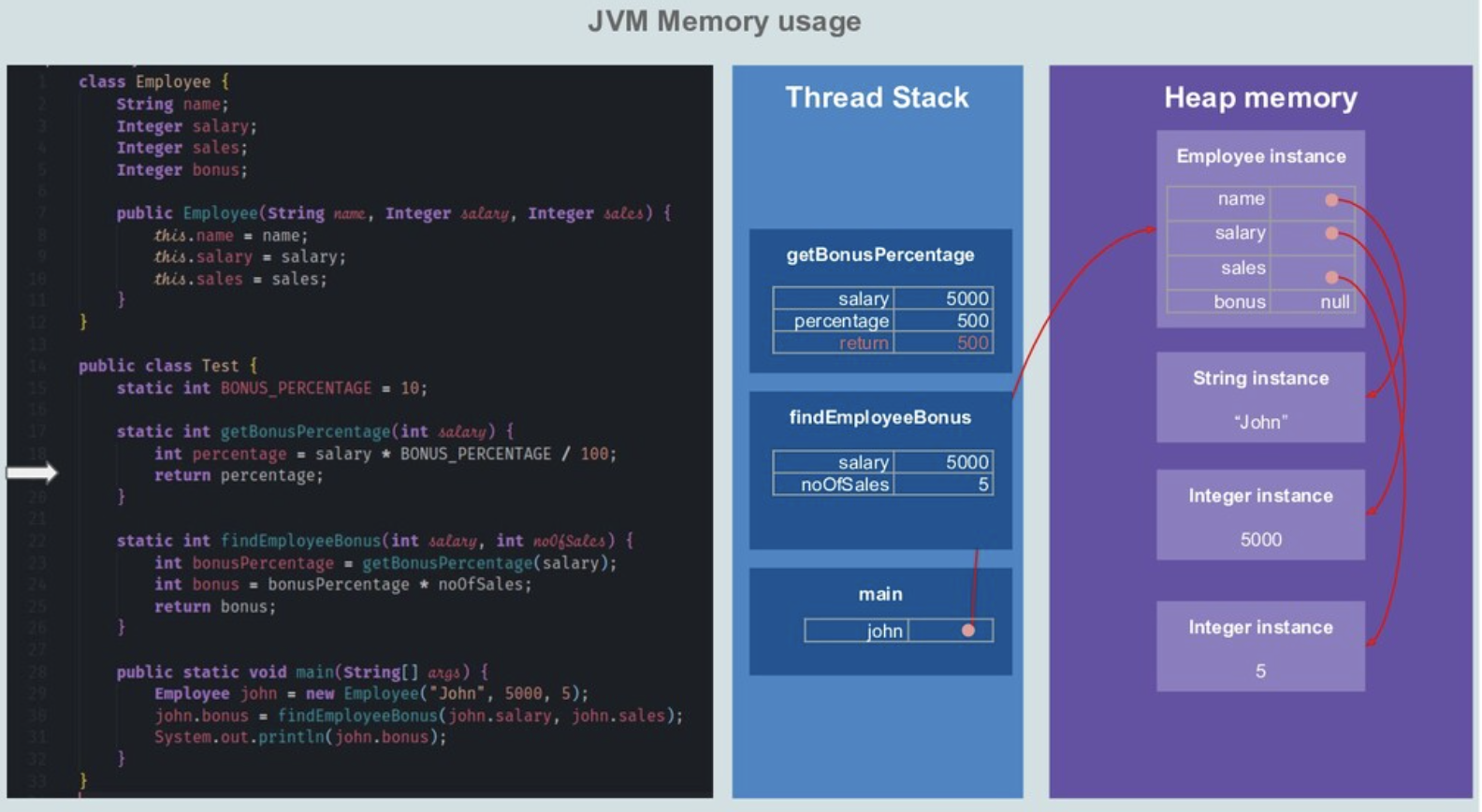
进程内存布局
Linux内核基础知识进程内存布局
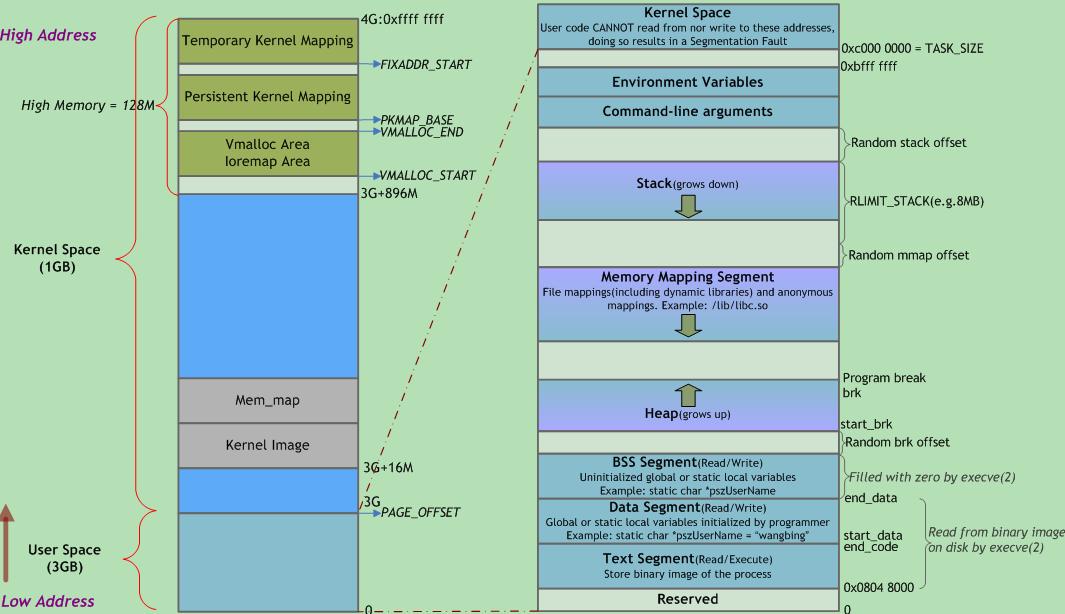
左右两侧均表示虚拟地址空间,左侧以描述内核空间为主,右侧以描述用户空间为主。右侧底部有一块区域“read from binary image on disk by execve(2)”,即来自可执行文件加载,jvm的方法区来自class文件加载,那么 方法区、堆、栈 便可以一一对上号了。
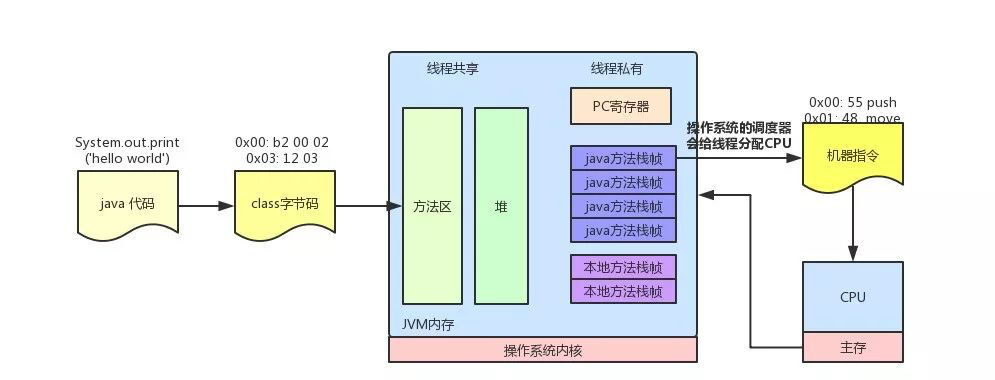
JVM内存区域新画法
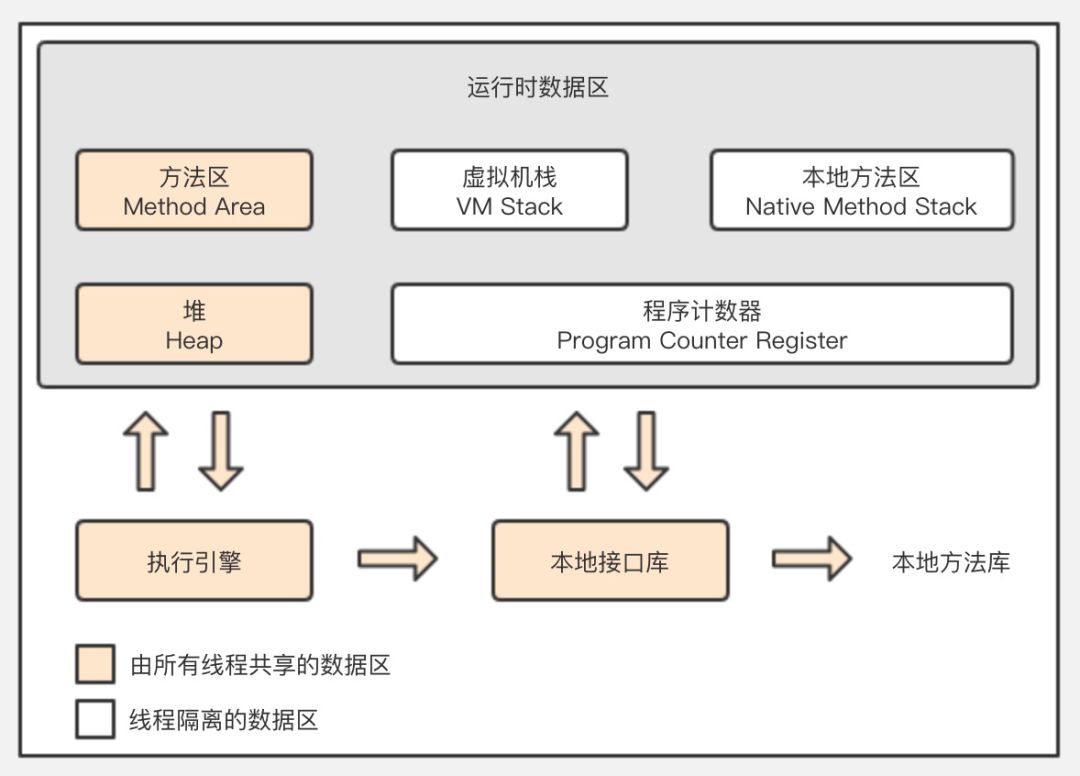
一个cpu对应一个线程,一个线程一个栈,或者反过来说,一个栈对应一个线程,所有栈组成栈区。我们从cpu的根据pc指向的指令的一次执行开始:
- cpu执行pc指向方法区的指令
- 指令=操作码+操作数,jvm的指令执行是基于栈的,所以需要从栈帧中的“栈”区域获取操作数,栈的操作数从栈帧中的“局部变量表”和堆中的对象实例数据得到。
- 当在一个方法中调用新的方法时,根据栈帧中的对象引用找到对象在堆中的实例数据,进而根据对象实例数据中的方法表部分找到方法在方法区中的地址。根据方法区中的数据在当前线程私有区域创建新的栈帧,切换PC,开始新的执行。
PermGen ==> Metaspace
Permgen vs Metaspace in JavaPermGen (Permanent Generation) is a special heap space separated from the main memory heap.
- The JVM keeps track of loaded class metadata in the PermGen.
- all the static content: static methods,primitive variables,references to the static objects
- bytecode,names,JIT information
- before java7,the String Pool
With its limited memory size, PermGen is involved in generating the famous OutOfMemoryError. What is a PermGen leak?
Metaspace is a new memory space – starting from the Java 8 version; it has replaced the older PermGen memory space. The garbage collector now automatically triggers cleaning of the dead classes once the class metadata usage reaches its maximum metaspace size.with this improvement, JVM reduces the chance to get the OutOfMemory error.
class文件的执行——虚拟机
java ==> class ==> c++ ==> 机器码
Java 并发——基石篇(中)https://www.infoq.cn/article/BpWRQGe-TUUbMmZ5rqtCJava 程序编译之后,会产生很多字节码指令,每一个字节码指令在 JVM 底层执行的时候又会变成一堆 C 代码,这一堆 C 代码在编译之后又会变成很多的机器指令,这样一来,我们的 java 代码最终到机器指令一层,所产生的机器指令将是指数级的,因此就导致了 Java 执行效率非常低下。
// HOTSPOT/src/share/vm/intercepter/bytecodeintercepter.cpp
BytecodeInterpreter::run(interpreterState istate){
...
switch (opcode){
...
CASE(_istore):
CASE(_fstore):
// 实际上便是C++代码
SET_LOCALS_SLOT(STACK_SLOT(-1), pc[1]);
UPDATE_PC_AND_TOS_AND_CONTINUE(2, -1);
...
}
...
}
怎么优化这个问题呢?字节码是肯定不能动的,因为 JVM 的一处编写,到处运行的梦想就是靠它完成的。其实,我们会发现,问题的根本就在于 Java 和机器指令之间隔了一层 C/C++,而例如 GCC 之类的编译器又不能做到绝对的智能编译,所产生的机器码效率仍然不是非常高。因此,我们会想,能不能跳过 C/C++ 这个层次能,直接将 java 字节码和本地机器码进行一个对应呢?是的!可以的!HotSpot 工程师们早就想到了,因此早期的解释执行器很快就被废弃了,转而采用模版执行器。什么是模版执行器,顾名思义,模版就是将一个 java 字节码通过「人工手动」的方式编写为固定模式的机器指令,这部分不在需要 GCC 的帮助,这样就可以大大减少最终需要执行的机器指令,所以才能提高效率。
基于栈的虚拟机
虚拟机的设计有两种技术:一是基于栈的虚拟机;二是基于寄存器的虚拟机。
java是一种跨平台的编程语言,为了跨平台,jvm抽象出了一套内存模型和基于栈的解释器,进而创建一套在该模型基础上运行的字节码指令。为了跨平台,不能假定平台特性,因此抽象出一个新的层次来屏蔽平台特性,因此推出了基于栈的解释器,与以往基于寄存器的cpu执行有所区别。
Virtual Machine Showdown: Stack Versus Registers
虚拟机随谈(一):解释器,树遍历解释器,基于栈与基于寄存器,大杂烩
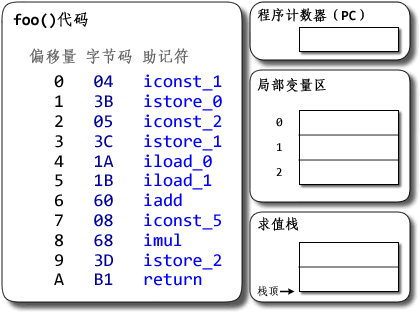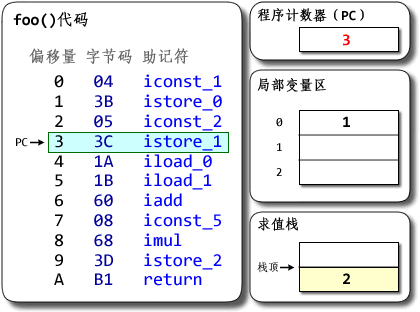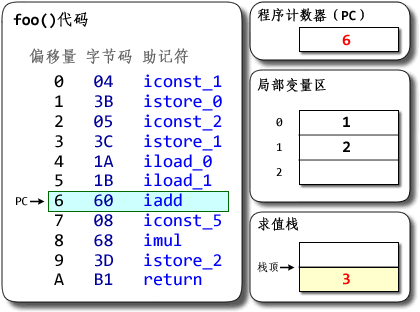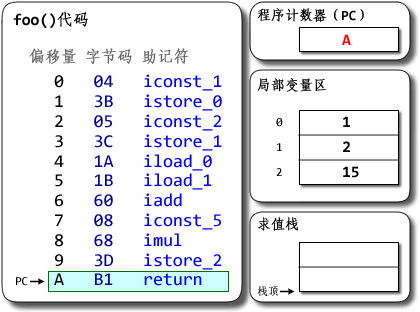
public class MyClass {
public int foo(int a){
return a + 3;
}
}
翻译后的部分字节码
public int foo(int);
Code:
0: iload_1 //把下标为1的本地变量入栈
1: iconst_3 //把常数3入栈
2: iadd //执行加法操作
3: ireturn //返回
| 基于栈的虚拟机 | 基于寄存器的虚拟机 | |
|---|---|---|
| 操作数 | 指令的操作数是由栈确定的,我们不需要为每个操作数显式地指定存储位置 | 基于寄存器的虚拟机的运行机制跟机器码的运行机制是差不多的,它的指令要显式地指出操作数的位置(寄存器或内存地址) |
| 优点 | 指令可以比较短,指令生成也比较容易 | 可以更充分地利用寄存器来保存中间值,从而可以进行更多的优化 |
| 典型代表 | jvm | Google 公司为 Android 开发的 Dalvik 虚拟机和 Lua 语言的虚拟机 |
栈机并不是不用寄存器,实际上,操作数栈是可以基于寄存器实现的,寄存器放不下的再溢出到内存里。只不过栈机的每条指令,只能操作栈顶部的几个操作数,所以也就没有办法访问其它寄存器,实现更多的优化。
虚拟机的一个通用优势:栈/寄存器 可以每个线程一份,一直存在内存中。对于传统cpu执行,线程之间共用的寄存器,在线程切换时,借助了pcb(进程控制块或线程控制块,存储在线程数据所在内存页中),pcb保存了现场环境,比如寄存器数据。轮到某个线程执行时,恢复现场环境,为寄存器赋上pcb对应的值,cpu按照pc指向的指令的执行。而在jvm体系中,每个线程的栈空间是私有的,栈一直在内存中(无论其对应的线程是否正在执行),轮到某个线程执行时,线程对应的栈(确切的说是栈顶的栈帧)成为“当前栈”(无需重新初始化),执行pc指向的方法区中的指令。
字节码生成——ASM
从编译原理的层面看,生成 LLVM 的 IR 时,可以得到 LLVM 的 API 的帮助。字节码就是另一种 IR,而且比 LLVM 的 IR 简单多了,有ASM/Apache BCEL/Javassist 这个工具为我们生成字节码。ASM是一个开源的字节码生成工具/字节码操纵框架。Grovvy 语言就是用它来生成字节码的,它还能解析 Java 编译后生成的字节码,从而进行修改。
ASM 解析字节码的过程,有点像 XML 的解析器解析 XML 的过程:先解析类,再解析类的成员,比如类的成员变量(Field)、类的方法(Mothod)。在方法里,又可以解析出一行行的指令。
部分生成的字节码
Spring 采用的代理技术有两个:一个是 Java 的动态代理(dynamic proxy)技术;一个是采用 cglib 自动生成代理,cglib 采用了 asm 来生成字节码。Java 的动态代理技术,只支持某个类所实现的接口中的方法。如果一个类不是某个接口的实现,那么 Spring 就必须用到 cglib,从而用到字节码生成技术来生成代理对象的字节码。
系统的根据编程语言代码AST生成字节码
基于 AST 生成 JVM 的字节码的逻辑还是比较简单的,比生成针对物理机器的目标代码要简单得多,为什么这么说呢?主要有以下几个原因:
- 不用太关心指令选择的问题。针对 AST 中的每个运算,基本上都有唯一的字节码指令对应,直白地翻译就可以了,不需要用到树覆盖这样的算法。
- 不需要关心寄存器的分配,因为 JVM 是使用操作数栈的;
- 指令重排序也不用考虑,因为指令的顺序是确定的,按照逆波兰表达式的顺序就可以了;
- 优化算法,暂时也不用考虑。
重排序
为什么会出现重排序
重排序的影响
主要体现在两个方面,详见Java内存访问重排序的研究
-
对代码执行的影响
常见的是,一段未经保护的代码,因为多线程的影响可能会乱序输出。少见的是,重排序也会导致乱序输出。
-
对编译器、runtime的影响,这体现在两个方面:
- 运行期的重排序是完全不可控的,jvm经过封装,要保证某些场景不可重排序(比如数据依赖场景下)。提炼成理论就是:happens-before规则(参见《Java并发编程实践》章节16.1),Happens-before的前后两个操作不会被重排序且后者对前者的内存可见。
- 提供一些关键字(主要是加锁、解锁),也就是允许用户介入某段代码是否可以重排序。这也是“which are intended to help the programmer describe a program’s concurrency requirements to the compiler” 的部分含义所在。
Java内存访问重排序的研究文中提到,内存可见性问题也可以视为重排序的一种。比如,在时刻a,cpu将数据写入到memory bank,在时刻b,同步到内存。cpu认为指令在时刻a执行完毕,我们呢,则认为代码在时刻b执行完毕。