
简介
代码分发:在物理机时代, springboot项目普遍都带了一个run.sh文件,不论项目本身的特点如何,开发和运维约定run.sh start/stop来启停应用
- 这说明只有一个jar是运行不起来的
- 如果我们不是一个java系为主的公司,这么做够么? 到后面,你就发现,run.sh 里可能什么都有,包括依赖库(比如转码程序会安装ffmpeg)、下载文件等,run.sh做到极致:一个应用一个操作系统环境(依赖库、env等),但整个文件岂不是很大?Docker最大的贡献就是提出了分层镜像的概念。
2013 年,Docker 出现了,工程师可以第一次到软件生产环境中定义,通过 Docker image 完成单机软件的交付和分发。
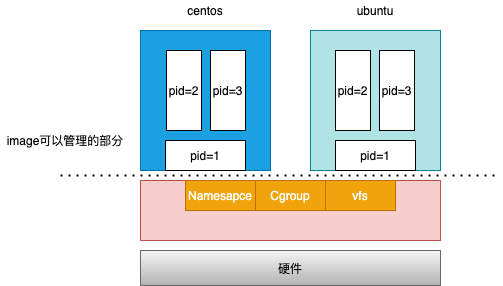
并非每个容器内部都能包含一个操作系统docker镜像不仅能够打包应用,还能打包整个操作系统的文件和目录,记住是操作系统的文件和目录。通过这种方式docker就把一个应用所有的依赖库包括操作系统中的文件和目录都被打包到镜像中。docker正是通过打包操作系统级别的方式,解决了开发到线上环境的一致性。宿主机操作系统只有一个内核,也就是说,所有的容器都依赖这一个内核了?比如我现在有一个需求,我的两个容器运行在同一台宿主机上,但是依赖的内核版本不一样,或者需要配置的内核参数不一样,怎么解决呢?解决不了,这也是容器化技术相比于虚拟机的主要缺陷之一。
内核,操作系统和发行版之间的区别:
- Linux内核是Linux操作系统的核心部分。这就是Linus最初写的。
- Linux操作系统是内核和用户域(库,GNU实用程序,配置文件等)的组合。
- Linux发行版是Linux操作系统的特定版本,例如Debian,CentOS或Alpine。
其实linux操作系统中代码包含两部分,一部分是文件目录和配置,另外一部分是内核,这两部分是分开存放的,系统只有在宿主机开机启动时才会加载内核模块。说白了,即使镜像中包含了内核也不会被加载。说到最后,原来镜像只是包含了操作系统的躯干(文件系统),并没有包含操作系统的灵魂(内核)。 容器中的根文件系统,其实就是我们做的镜像。
制作镜像
cid=$(docker run -v /foo/bar debian:jessie)
image_id=$(docker commit $cid)
cid=$(docker run $image_id touch /foo/bar/baz)
docker commit $(cid) my_debian
image的build过程,粗略的说,就是以容器执行命令(docker run)和提交更改(docker commit)的过程
build 时使用http代理
2019.4.3 补充
docker build --build-arg HTTPS_PROXY='http://userName:password@proxyAddress:port' \
--build-arg HTTP_PROXY='http://userName:password@proxyAddress:port' \
-t $IMAGE_NAGE .
当你在公司负责维护docker 镜像时,不同镜像的Dockerfile 为了支持协作及版本跟踪 一般会保存在git 库中。制作镜像 通常需要安装类似jdk/tomcat 等可执行文件,这些文件建议使用远程下载的方式(因为git 保存二进制文件 不太优雅),以安装tomcat 为例
RUN \
DIR=/tmp/tomcat && mkdir -p ${DIR} && cd ${DIR} && \
curl -sLO http://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-8/v8.5.40/bin/apache-tomcat-8.5.40.tar.gz &&\
tar -zxvf apache-tomcat-8.5.40.tar.gz -C /usr/local/ && \
mv /usr/local/apache-tomcat-8.5.40 /usr/local/tomcat && \
rm -rf ${DIR}
多阶段构建
Use multi-stage builds multi-stage builds 的重点不是multi-stage 而是 builds
先使用docker 将go文件编译为可执行文件
FROM golang:1.7.3
WORKDIR /go/src/github.com/alexellis/href-counter/
COPY app.go .
RUN go get -d -v golang.org/x/net/html \
&& CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
因为笔者一直是直接做镜像,所以没这种感觉。不过这么做倒有一点好处:可执行文件的实际运行环境 可以不用跟 开发机相同。学名叫同构/异构镜像构建。
然后将可执行文件 做成镜像
FROM alpine:latest
RUN apk --no-cache add ca-certificates
WORKDIR /root/
COPY app .
CMD ["./app"]
镜像规范
基础镜像选型的教训
公司实践时,做docker 镜像的时候为了精简,用了alpine, 但是alpine的一些表现跟ubuntu 这些大家常见的OS不一样,几百号开发,光天天回答为啥不能xxx(参见jar冲突),就把人搞死了。
很多公司比如个推镜像体系 猪八戒网DevOps容器云与流水线均采用Centos 为base 镜像
所以,技术极客跟推广使用还是有很大区别的。
tag
假设tomcat镜像有两个tag
- tomcat:7
- tomcat:6
当你docker push tomcat,不明确指定tag时,docker会将tomcat:7和tomcat:6都push到registry上。
所以,当你打算让docker image name携带版本信息时,版本信息加在name还是tag上,要慎重。
镜像下载
镜像一般会包括两部分内容,一个是 manifests 文件,这个文件定义了镜像的 元数据,另一个是镜像层,是实际的镜像分层文件。
docker login
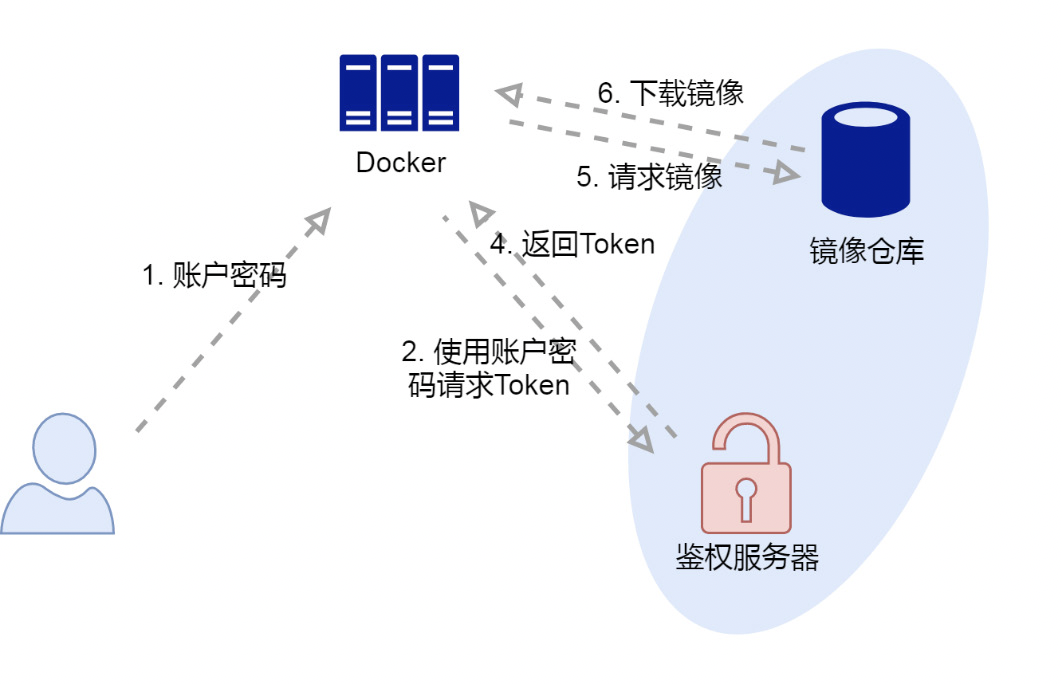
我们在拉取私有镜像之前,要使用 docker login 命令来登录镜像仓库。登录主要就做了三件 事情:
- 向用户要账户密码
- docker 访问镜像仓库的 https 地址,并通过挑战 v2 接口来确 认,接口是否会返回 Docker-Distribution-Api-Version 头字段。它的作用跟 ping 差不多,只是确认下 v2 镜像仓库是否在线,以及版本是否匹配。
- docker 使用用户提供的账户密码,访问 Www-Authenticate 头字段返回的鉴权服务器的地址 Bearer realm。如果这个访问成功,则鉴权服务器会返回 jwt 格式的 token 给 docker,然后 docker 会把账户密码编码并保存在用户目录的 .docker/docker.json 文件里。这个文件作为 docker 登录仓库的 唯一证据,在后续镜像仓库操作中,会被不断的读取并使用。
docker 镜像下载加速
两种方案
- 使用private registry
- 使用registry mirror,以使用daocloud的registry mirror为例,假设你的daocloud的用户名问
lisi,则DOCKER_OPTS=--registry-mirror=http://lisi.m.daocloud.io
本地存储
Where are Docker images stored?
local storage/docker镜像与容器存储目录
以virtualbox ubuntu 14.04为例
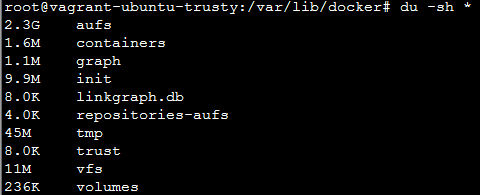
repositories-aufs这个文件输出的内容,跟”docker images”输出的是“一样的”。
graph中,有很多文件夹,名字是image/container的id。文件夹包括两个子文件:
- json 该镜像层的描述,有的还有“parent”表明上一层镜像的id
- layersize 该镜像层内部文件的总大小
aufs和vfs,一个是文件系统,一个是文件系统接口,从上图每个文件(夹)的大小可以看到,这两个文件夹是实际存储数据的地方。
不论image 的registry storage 还是 local storage 都在表述一个事儿:layer存储以及 layer 如何组装成一个image
警惕镜像占用的空间
假设公司项目数有2k+,则使用docker后,一台物理机上可能跑过所有服务, 自然可能有2k+个镜像,庞大的镜像带来以下问题
- 占满物理机磁盘,笔者在jenkins + docker 打包机器上碰到过这种现象
- 虽未占满磁盘,但大量的镜像目录文件严重拖慢了docker pull 镜像的速度,进而导致调度系统(比如mesos+marathon)认为无法调度而将任务转移到别的机器上,导致某个主机空有资源但就是“接收”不了任务分派。
为此,我们要周期性的清理 docker 占用的磁盘空间。如何清理Docker占用的磁盘空间?
docker 的磁盘使用 包括:images/containers/volumnes,可以用docker system df 查看。
清理命令有两种选择:
- docker system prune命令可以用于清理磁盘,删除关闭的容器、无用的数据卷和网络,以及dangling镜像(即无tag的镜像)。
- docker system prune -a命令清理得更加彻底,可以将没有容器使用Docker镜像都删掉。