
简介
服务治理的核心目标是考虑如何确保这些软件能够真正做到 24 小时不间断的服务。服务治理没有简洁的抽象问题模型,我们需要面对的是现实世界的复杂性。但是,它们的确已经在被解决的边缘。相关领域的探索与发展,日新月异。
本文主要以框架实现的角度 来阐述微服务治理,主要包括两个方面:“业务层面”(微服务应该有什么)和工程层面(如何code实现)。此外,篇幅有限,多从客户端(即业务使用方)角度来阐述问题。
服务治理在猫眼的演进之路-Service Mesh服务治理的包含了非常多的能力,比如服务通讯、服务注册发现、负载均衡、路由、失败重试等等
2019.12.13补充:What is Istio?The term service mesh is used to describe the network of microservices that make up such applications and the interactions between them. As a service mesh grows in size and complexity, it can become harder to understand and manage. Its requirements can include discovery, load balancing, failure recovery, metrics, and monitoring. A service mesh also often has more complex operational requirements, like A/B testing, canary rollouts, rate limiting, access control, and end-to-end authentication. 理解: service mesh 可以理解为 the network of microservices, 随着service mesh 规模的扩大, 会产生 discovery, load balancing, failure recovery, metrics, monitoring, A/B testing, canary rollouts, rate limiting, access control, and end-to-end authentication 等一系列问题。
- 服务注册发现
- 路由,流量转移。 红绿灯是一种流量控制;黑白名单也是一种流量控制
- 弹性能力(熔断、超时、重试)
- 安全
- 可观察性(指标、日志、追踪)。四个基本的服务监控需求:延迟、流量、错误、 饱和
整体架构
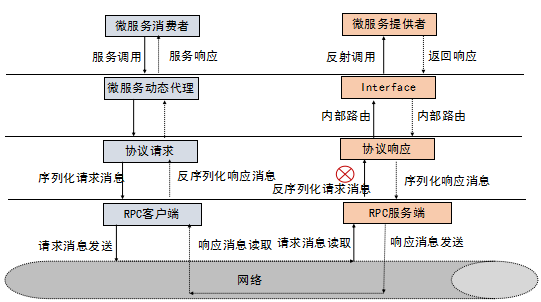
三大基本套路
微服务架构是什么
- rpc、调用信息序列化 等基本能力
- 服务发现、路由、监控报警 等旁路系统
- 分拆业务 的一种方式
服务发现、路由、监控报警 等事情 谁去干呢?
- 以框架为中心
- 以PaaS 平台为中心,将 公共的 技术能力沉淀到 PaaS层,运维不再只是提供 物理机/jvm 虚拟机,而是提供一个服务,服务的访问形式是ip:port/http url。PaaS 内部负责服务发现、负载均衡等能力等
- service mesh
从0 到 1 实现一个服务治理框架
基本能力
包括且不限于以下问题:
- io通信
- 序列化协议
io 通信包括同步模型和异步模型。
同步模型的调用流程为:请求 ==> 线程 ==> 获取一个连接 ==> 阻塞。此时一个请求将占用一个线程、一个连接。阻塞分为两种情况
- io阻塞,比如connect、read 等
- 业务阻塞,服务端bug或负载很大,无法及时返回响应,会表现为客户端read 一直阻塞
异步模型的调用流程为:请求 ==> 线程 ==> 获取一个连接 ==> 发请求 ==> 接口调用结束。 异步的问题在于,通过队列缓冲了请求,若是客户端请求的速度远超服务端响应的速度, 队列会增长,会oom
rpc 就好像函数调用一样,有数据有状态的往来。也就是需要有请求数据、返回数据、服务里面还可能需要保存调用的状态。
qiankunli/pigeon 笔者基于netty 实现了一个具备基本能力的rpc 框架,推荐用来熟悉上述过程。
旁路系统
-
客户端,从上到下依次是:
- 熔断
- 自己有问题,阻断别人调用自己
- 别人有问题 放弃调用别人
- 服务发现
- 路由
- 负载均衡
- 调用策略
- 熔断
-
服务端
- 服务注册
- 线程隔离
- 限流
每一个点都有一系列的策略实现,比如调用策略,假设一个服务有3个实例ABC,称为集群cluster,客户端去调用A
- failfast,A 实例故障,则调用失败
- failover,A 实例故障,则重试BC
- failsafe,A 实例故障,返回实现配置的默认值
额外提一个问题:框架实现的哪些功能部分适合下放到PaaS 层去做?
2018.12.15 补充:个推基于Docker和Kubernetes的微服务实践服务发现的几种实现方式
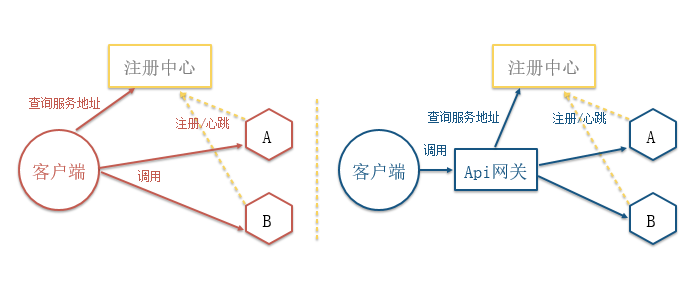
第一种是客户端通过向服务的注册中心查询微服务的地址与其通信,第二种是增加统一的API网关来查询。前者会增加客户端的复杂度,开发成本高,后者操作会更加简洁,但网关可能会成为瓶颈。
工程实现
实现基本能力
假设存在一个web服务,接收请求,调用rpc 服务处理请求,则按照传统controller-service-dao 的方式,会如何组织代码?
controller
service
CircuitBreaker
route
loadbalance
serialize/codec
socket
很明显service 层以下,是框架应该解决的部分,不应该直接暴露在业务代码中,因此类似于传统访问db 的方式:
controller
service
micro service
自然的,service 与 micro service 之间会定义一个接口(下文称为Iface),客户端调用该接口,服务端则提供接口实现。
我们先只考虑基础能力的实现,则对于客户端来说,Iface 实现(下文称为Impl)的实现逻辑大体是
- 将参数序列化
- 使用socket 发送调用数据,包括但不限于类名、方法名、方法参数及其它信息,比如为分析调用链路 而设置的链路id
- 读取服务端返回,并将返回结果反序列化
在实际的实现中,这一步骤通常是自动生成的,比如thrift
如何聚合旁路系统
基于上节的基本实现,很直观的,我们可以将聚合旁路系统的问题 抽象为一个 如何在已有代码上 “加私货” 的问题。很自然的,会想到使用java 代理 拦截Iface 方法执行,然后加入旁路系统的相关代码。
每一个旁路子系统都有一系列的配置,在聚合的过程中,还需拉取这些配置。配置有以下来源
- xml 文件
- 后端管理界面 及其存储数据的 db
- zk node
- 用户代码中的注解
进阶篇——三高设计
- 单单解决有无问题很简单,解决好用不好用很难
- 这里充分体现了 基础知识多么的重要,比如linux io、tcp 流控等
高性能设计
使用netty
- 框架启动时,预热内存。netty 的 pooledThreadcache比如arena获取内存有个锁,项目启动时大量请求突然打过来,会等着arena 分配内存,等待锁。千军万马在这个地方过了独木桥,排到后面的线程 便会处理超时。
- FixedChannelPool 在io线程里干 申请连接 以及 borrow、return 的活儿,效率低(是这个思维方向,细节待确认)
- WriteBufferWaterMark 含义重新理解。WriteBufferWaterMark 是从内存大小角度控制发送速度,netty还有一个 任务队列的长度限制,通常配置一个就行了,两者有一个很tricky的关系。(细节待确认)
- ioloop 里不能阻塞,甚至连写日志的逻辑都不能有,log4j 存在性能问题
- 快慢线程池,一个客户端可能依赖多个下游服务端,一开始无差别的处理各种服务端调用,但这些调用有快有慢,彼此影响。因此根据阈值,将比较慢的服务端调用放入慢线程池中。理由,netty 的 eventloop 会根据io和cpu 时间占比 来调整每次select 的阻塞时间。 这类似于 jvm heap 根据对象的有效期 将内存划分为 年轻代 和老年代。
- 根据监控,按照4个9的响应时间来设置超时时间,甚至可以考虑支持自动设置超时时间
对异步的支持
- 微服务框架 一般要在调用链路中传递 链路信息traceId等,并且这类信息通常以threadlocal 方式隐含传递。对于service A 调用service B 场景,异步情况下,service A 内部分为 业务调用线程 和 io线程,service A threadlocal 持有的traceId 要先 传递给 service a 的io 线程,再发送给 service B
扩展性设计
分层设计,每一层留有自定义实现的余地
可靠性设计
-
通信层可靠性设计。
- 链路有效性检测——心跳机制。
- 客户端断连重连——为了保证服务端能够有充足的时间释放句柄资源,在首次断连时客户端需要等待 INTERVAL 时间之后再发起重连,而不是失败后就立即重连。无论什么场景下的重连失败,客户端都必须保证自身的资源被及时释放。
- 缓存重发
- 客户端超时保护
- 针对客户端的并发连接数流控
- 内存保护
-
rpc 层可靠性设计
- rpc调用异常,服务路由失败;服务端超时;服务端调用失败
-
第三方服务依赖故障隔离
- 依赖隔离
- 异步化
对公司内rpc的观察:
- 熔断,熔断时99.99% 流量返回默认值,剩余的继续调用,作为探测
- 熔断恢复,慢恢复,探测成功后,每隔10s恢复10%的流量
- mainstay client server 是否可以像tcp 一样流控一下,部分解决client发送速率 和 server 消费能力不一致的问题。
- 发生熔断时(失败率、超时超过一定量级),(client 包括业务线程和io线程),业务线程走降级逻辑,使得等待队列不再有或只有探测请求进来, 同时清理等待队列中的消息,清理连接池(因为连接很有可能已经不健康了)
限流的套路
限流有哪些套路?哪些坑?
- 固定时间窗口限流算法。限流策略过于粗略,无法应对两个时间窗口临界时间内的突发流量。假设我们的限流规则是,每秒钟不能超过 100 次接口请求。第一个 1s 时间窗口内,100 次接口请求都集中在最后 10ms 内。在第二个 1s 的时间窗口内,100 次接口请求都集中在最开始的 10ms 内。虽然两个时间窗口内流量都符合限流要求(≤100 个请求),但在两个时间窗口临界的 20ms内,会集中有 200 次接口请求。固定时间窗口限流算法并不能对这种情况做限制,所以,集中在这 20ms 内的 200 次请求就有可能压垮系统。
- 滑动时间窗口限流算法。流量经过滑动时间窗口限流算法整形之后,可以保证任意一个 1s的时间窗口内,都不会超过最大允许的限流值,从流量曲线上来看会更加平滑。假设限流的规则是,在任意 1s 内,接口的请求次数都不能大于K 次。我们就维护一个大小为 K+1 的循环队列,用来记录1s 内到来的请求。当有新的请求到来时,我们将与这个新请求的时间间隔超过 1s 的请求,从队列中删除。然后,我们再来看循环队列中是否有空闲位置。如果有,则把新请求存储在队列尾部(tail 指针所指的位置);如果没有,则说明这 1 秒内的请求次数已经超过了限流值K,所以这个请求被拒绝服务。 但对细粒度时间上访问过于集中的问题也只是部分解决
- 令牌桶算法
- 漏桶算法
一个大牛开源的限流框架:wangzheng0822/ratelimiter4j
微服务不是银弹
20200527 补充:一些比较好的解决方法 如何提升微服务的幸福感
带来的问题
单体服务 ==> 通过 rpc 分割为微服务 ==> 带来以下问题:
- 查看日志 定位问题要看好几台机器
- 调用链路 较长的情况下,网络通信也是一种开销
- 一个服务出现问题,容易在整个微服务网络蔓延(通过熔断器部分解决)
拆分服务
我们为什么要做微服务?对这个问题的标准回答是,相对于整体服务(Monolithic)而言,微服务足够小,代码更容易理解,测试更容易,部署也更简单。这些道理都对,但这是做好了微服务的结果。怎么才能到达这个状态呢?这里面有一个关键因素,怎么划分微服务,也就是一个庞大的系统按照什么样的方式分解。领域驱动。
拆分服务的几种考虑:
- 服务下沉: 将具有两个以上使用者的服务下沉,使其成为一种基础服务。
- 将负载不一致的几个服务拆分,减少彼此的相互影响
- 将关键链路的服务拆分,减少代码迭代对关键链路的影响