
前言
学习路线
现在学习 AI,特别是上手深度学习,已经清楚的出现了两条路子。
- 以理论为中心,扎扎实实从数学基础开始,把数据科学、机器学习大基础夯实,然后顺势向上学习Deep Learning,再往前既可以做研究,也可以做应用创新。
- 以工具为中心,直接从Tensorflow、Caffe、MXNET、PyTorch 这些主流的工具着手,以用促练,以练促学。
一般来说,第一条路子适合于还在学校里、离毕业还有两年以上光景的青年学生,而第二条路子适合于已经工作,具有一定开发经验的人,也适合时间有限的转型开发者,这条路见效快,能很快出成果,受到更多人的青睐。但是它也同样需要一个健康的框架,如果自己瞎撞,表面上看很快也能重复别人已经做出来的成果,但是外强中干,并不具备解决新问题的能力,而且一般来说在知识和技能体系里会存在重大的缺陷。
斯坦福大学今年上半年开了一门课程,叫做 CS20SI: Tensorflow for Deep Learning Research。可以说这门课程为上面所说的第二条路径规划了一个非常漂亮的框架。学习斯家的课程,你很容易找到一种文武双修、理论与实践生命大和谐的感觉。特别是斯家课程的课件之细致完备、练习之精到舒适,处处体现一种“生怕你学不会、学不懂”的关怀。stanford-tensorflow-tutorials
王天一:人工智能的价值在于落地,它的优势则是几乎所有领域都有用武之地。与其星辰大海,不如近水楼台。将自身专业的领域知识和人工智能的方法结合,以解决实际问题,才是搭上人工智能这趟快列的正确方法。
机器学习的数学基础
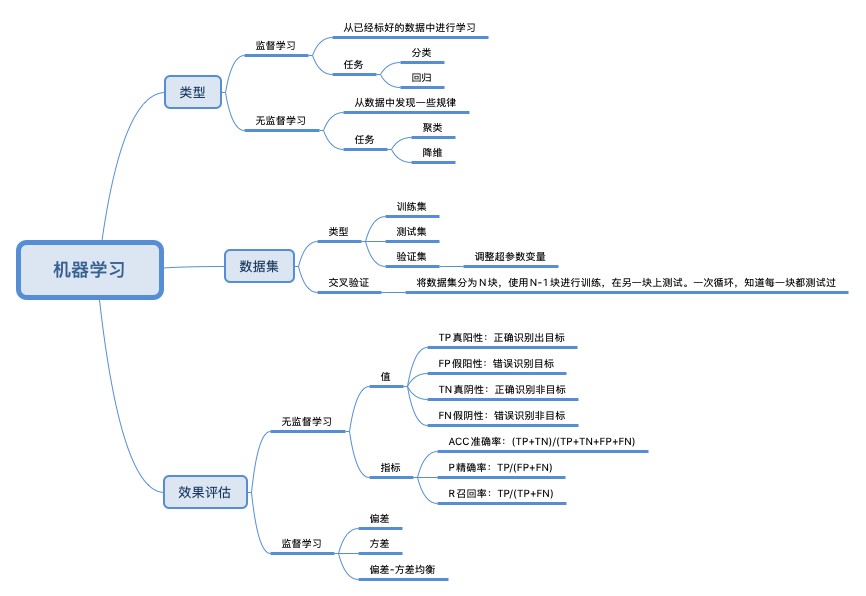
利用机器学习,我们至少能解决两个大类的问题:
- 分类(Classification)
- 回归(Regression)。
为了解决这些问题,机器学习就像一个工具箱,为我们提供了很多现成的的算法框架,比如:LR, 决策树,随机森林,Gradient boosting等等,还有近两年大热的深度学习的各种算法,但要想做到深入的话呢,只是会使用这些现成的算法库还不够,还需要在底层的数学原理上有所把握。比如
- 研究优化理论,才能够有更好的思路去设计和优化目标函数;
- 研究统计学,才能够理解机器学习本质的由来,理解为什么机器学习的方法能够使得模型一步步地逼近真实的数据分布;
- 研究线性代数,才能够更灵活地使用矩阵这一数学工具,提高了性能且表达简洁,才能够更好地理解机器学习中涉及到的维数灾难及降维问题;
- 研究信息论,才能够准确地度量不同概率分布之间的差异。
王天一:人工智能虽然复杂,但并不神秘。它建立在数学基础上,通过简单模型的组合实现复杂功能。在工程上,深度神经网络通常以其恒河沙数般的参数让人望而却步;可在理论上,各种机器学习方法的数学原理却具有更优的可解释性。从事高端研究工作固然需要非凡的头脑,但理解人工智能的基本原理绝非普通人的遥不可及的梦想。
学习材料
三百多页ppt,就说比较好的学习材料李宏毅一天搞懂深度學習
吴恩达给你的人工智能第一课 这是笔者实际的入门课程
才云内部的课程资料:适合传统软件工程师的 Machine Learning 学习路径
2017 斯坦福李飞飞视觉识别课程 虽然说得是视觉识别,但一些机器学习的基本原理也值得一看。CS231n课程笔记翻译:神经网络笔记1(上) 未读
实践
实践说的是:选择入门的编程语言(基本是python)以及编程语言在机器学习方面的库
CS231n课程笔记翻译:Python Numpy教程 未读
基本原理搞懂之后,可以先找个实际问题+dataset 实操一下 Kaggle入门,看这一篇就够了Kaggle成立于2010年,是一个进行数据发掘和预测竞赛的在线平台。入门级的三个经典练习题目:
自动编码器
如何学习特征,用到了自编码器。参考文章
自动编码器基于这样一个事实:原始input(设为x)经过加权(W、b)、映射/传递函数(Sigmoid)之后得到y,再对y反向加权映射回来成为z。
通过反复迭代训练(W、b),使得误差函数最小,即尽可能保证z近似于x,即完美重构了x。
那么可以说(W、b)是成功的,很好的学习了input中的关键特征,不然也不会重构得如此完美。Vincent在2010年的论文中做了研究,发现只要训练W就可以了。