
前言
Garbage Collection In Go : Part I - Semantics Garbage Collection In Go : Part II - GC Traces Garbage Collection In Go : Part III - GC Pacing
现代计算机语言大多数都带有自动内存管理功能,也就是垃圾收集(GC)。程序可以使用堆中的内存,但我们没必要手工去释放。垃圾收集器可以知道哪些内存是垃圾,然后归还给操作系统。垃圾收集包括标记-清除、停止-拷贝两大类算法,停止-拷贝算法被认为是最快的垃圾收集算法,但停止-拷贝算法有缺陷STW(Stop-The-World)。 在自动内存管理领域的一个研究的重点,就是如何缩短这种停顿时间。以 Go 语言为例,它的停顿时间从早期的几十毫秒,已经降低到了几毫秒。甚至有一些激进的算法,力图实现不用停顿。增量收集和并发收集算法,就是在这方面的有益探索。
增量收集可以每次只回收部分对象,没必要一次把活干完,从而减少停顿。并发收集就是在不影响程序执行的情况下,并发地执行垃圾收集工作。
为了讨论增量和并发收集算法,我们定义两个角色:一个是收集器(Collector),负责垃圾收集;一个是变异器/应用程序(Mutator),它会造成可达对象的改变。
Visualizing memory management in Golang 有动图建议细读
三色标记法
采取 STW 这样凶残的策略,主要还是防止 mutator 在 GC 的时候捣乱——这跟你用扫地机器人的时候先把狗(Mutator/Application)先锁起来,等房子全部打扫完再把狗放开 的道理是一样的(Stop The Dog)。
新一代垃圾回收器ZGC的探索与实践 与jvm ZGC 非常类似。自己的理解:
- java对象头信息是跟对象自身定义的数据结构无关的,这些信息所记录的状态是用于JVM对对象的管理的(比如并发访问和gc)。
- gc root 是一些固定特点的对象,一直存在。gc过程可以看做给 gc root加子节点的过程,最后得出一棵树(可达对象在“物理平面”是犬牙交错的),节点有两种状态,在不在树上(可达不可达,对象头mark word 有专门字段),在树上的节点不会被回收。事实上树并不存在(否则对象头 就得有字段表示子节点了),只是gc 线程遍历轨迹的一种表示。
- 抛开gc 线程和应用线程,线程A和线程B竞争访问同一个对象,可以线程安全的一个底层机制就是,对象头 里有一个mark word 标记了对象是线程A的“人”,当线程B 从对象 mark word 中发现 对象“名花有主”了,就会放弃操作 对象,等待。
- gc 线程和 应用线程 也是如此,之前 gc 和 应用线程没有 沟通机制,所以gc 干活儿的时候,应用线程就得 “歇着”。涂色 本质上 是给了 应用线程一种权力,在对象上做标记(就像对象mark word上的 线程标识符一样),告诉 gc 线程 这个对象 “我罩着了”,gc 线程便不会回收了。
在三色标记法之前有一个算法叫 Mark-And-Sweep(标记清扫),这个算法就是严格按照追踪式算法的思路来实现的。这个算法会设置一个标志位来记录对象是否被使用。最开始所有的标记位都是 0,如果发现对象是可达的就会置为 1,一步步下去就会呈现一个类似树状的结果。等标记的步骤完成后,会将未被标记的对象统一清理,再次把所有的标记位设置成 0 方便下次清理。这个算法最大的问题是 GC 执行期间需要把整个程序完全暂停,不能异步进行 GC 操作。因为在不同阶段标记清扫法的标志位 0 和 1 有不同的含义(比如0 可能是未被清理 也可能是清理完毕了?),那么新增的对象无论标记为 什么都有可能意外删除这个对象。对实时性要求高的系统来说,这种需要长时间挂起的标记清扫法是不可接受的。所以就需要一个算法来解决 GC 运行时程序长时间挂起的问题,那就三色标记法。
相比传统的标记清扫算法,三色标记最大的好处是可以异步执行,从而可以以中断时间极少的代价或者完全没有中断来进行整个 GC。三色标记法很简单。
- 首先将对象用三种颜色表示,分别是白色、灰色和黑色。最开始所有对象都是白色的,然后把其中全局变量和函数栈里的对象置为灰色。
- 第二步把灰色的对象全部置为黑色,然后把原先灰色对象指向的变量都置为灰色,以此类推。
- 等发现没有对象可以被置为灰色时,所有的白色变量就一定是需要被清理的垃圾了。
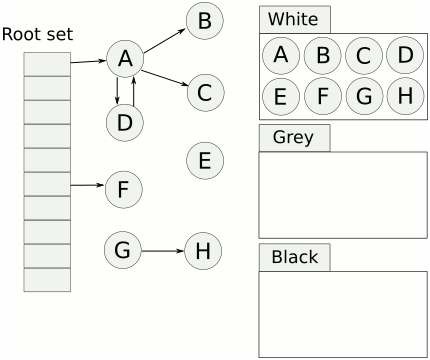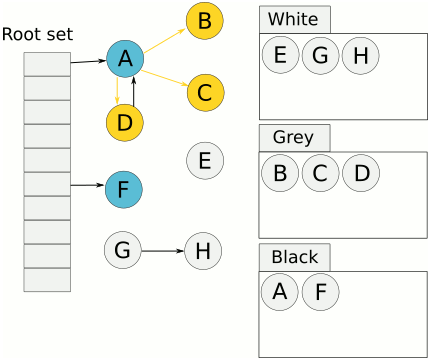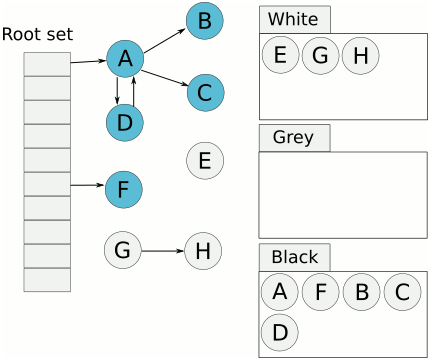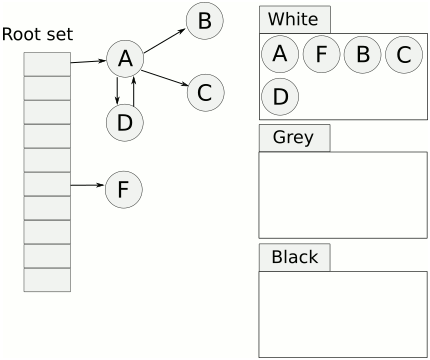
三色标记法因为多了一个白色的状态来存放不确定的对象,所以可以异步地执行。当然异步执行的代价是可能会造成一些遗漏,因为那些早先被标记为黑色的对象可能目前已经是不可达的了。所以三色标记法是一个 false negative(假阴性)的算法。
三色标记法是一种可以并发执行的算法。所以在运行过程中程序的函数栈内可能会有新分配的对象,那么这些对象该怎么通知到 GC,怎么给他们着色呢?这个时候就需要我们的 Write Barrier 出马了。Write Barrier 主要做这样一件事情,修改原先的写逻辑,然后在对象新增的同时给它着色,并且着色为”灰色“。因此打开了 Write Barrier 可以保证了三色标记法在并发下安全正确地运行。
三色标记主要是为了解决传统双色标记过程无法分片的问题(或者说STW是 串行执行的,不需要分片),有了三色标记,Collector/GC线程便可以暂停、重启,变成跟 mutator并发的方式来运行;
三色标记法是什么?三色标记过程其实是一个波面不断前进的过程。
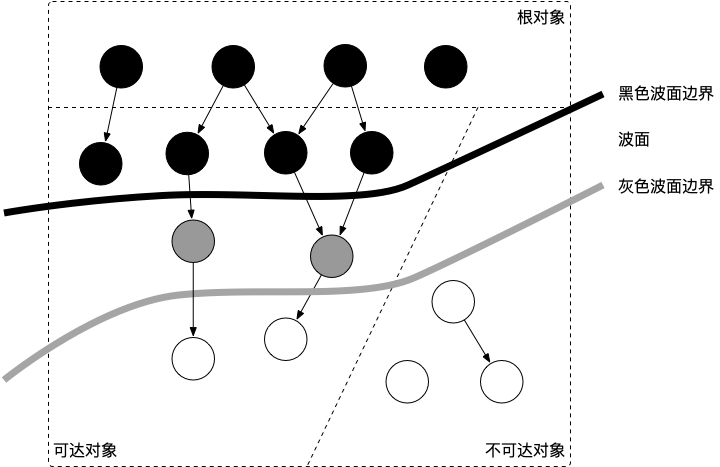
就物理位置来说,三个颜色的对象是“犬牙交错”的,通过标记颜色,使其变成了几块“泾渭分明”的区域。
小时候看动画片《一休》,提到有一次一休的师兄被惩罚去树林里数一下树有多少,结果下雨天摔倒啥的,很容易就忘了刚才数到哪了。后来一休想了个办法,拿来一捆绳子,每棵树上系一根绳子,数一下剩下多少根绳子,就知道有多少棵树了。
Go 的 GC 有且只会有一个参数进行调优,也就是我们所说的 GOGC,目的是为了防止大家在一大堆调优参数中摸不着头脑。 默认值是 100。这个 100 表示当内存的增加值小于等于 100% 时会强制进行一次垃圾回收。我们可以通过环境变量将这个值修改成 200,表示当内存增加 200% 时强制进行垃圾回收。或者将这个值设置为负数表示不进行垃圾回收。
图解
Go GC visualized 部分图如下
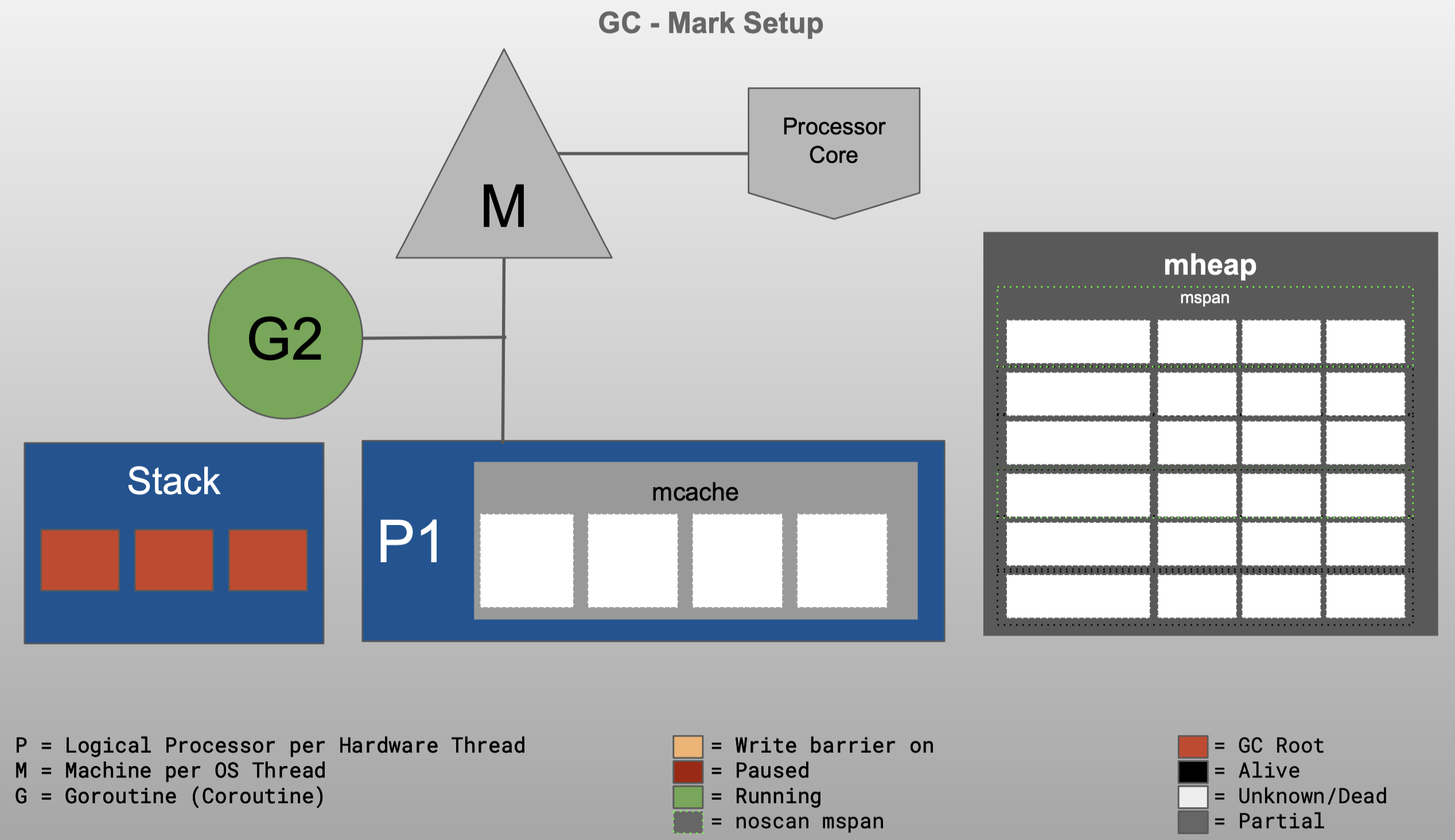
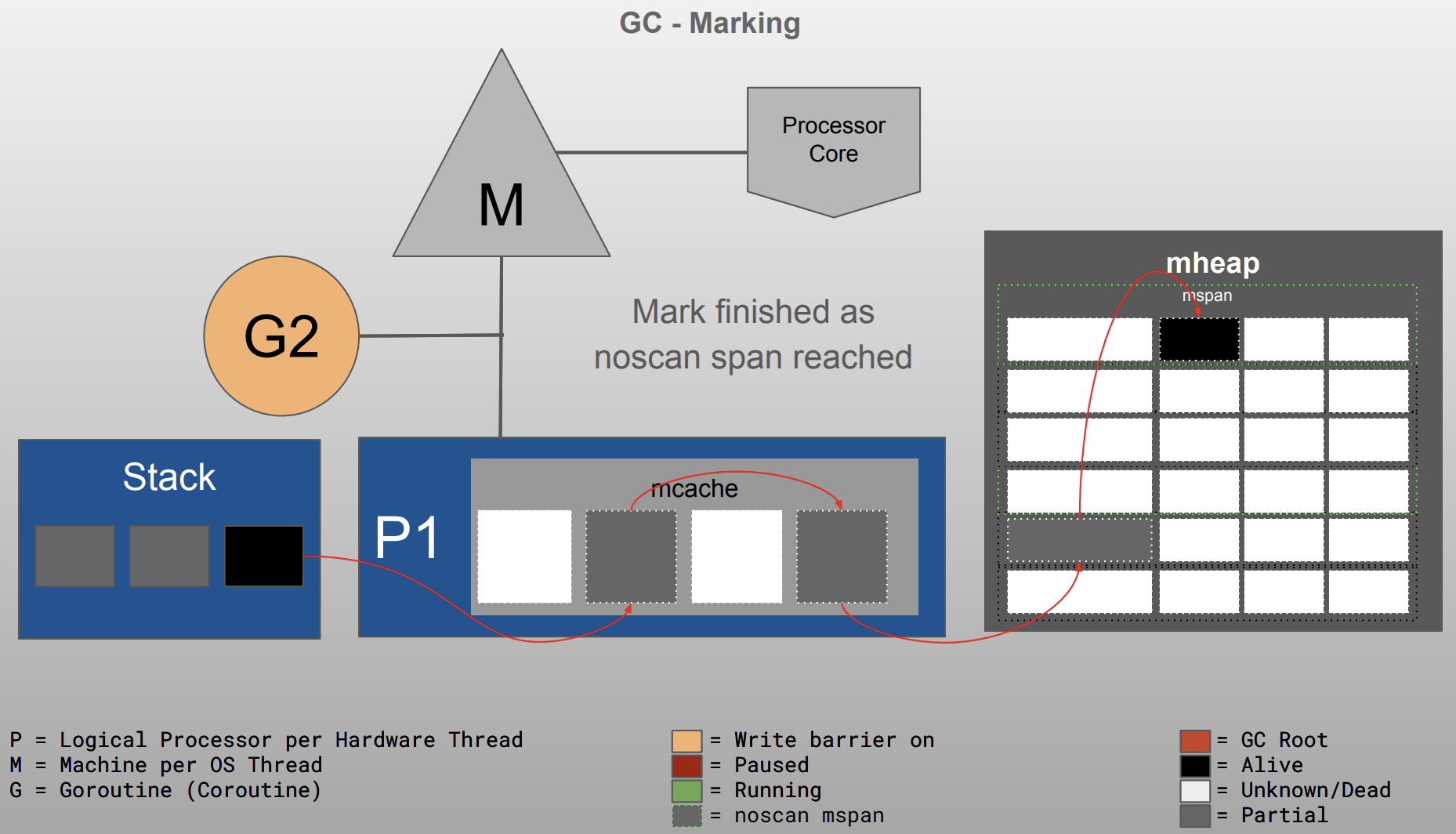
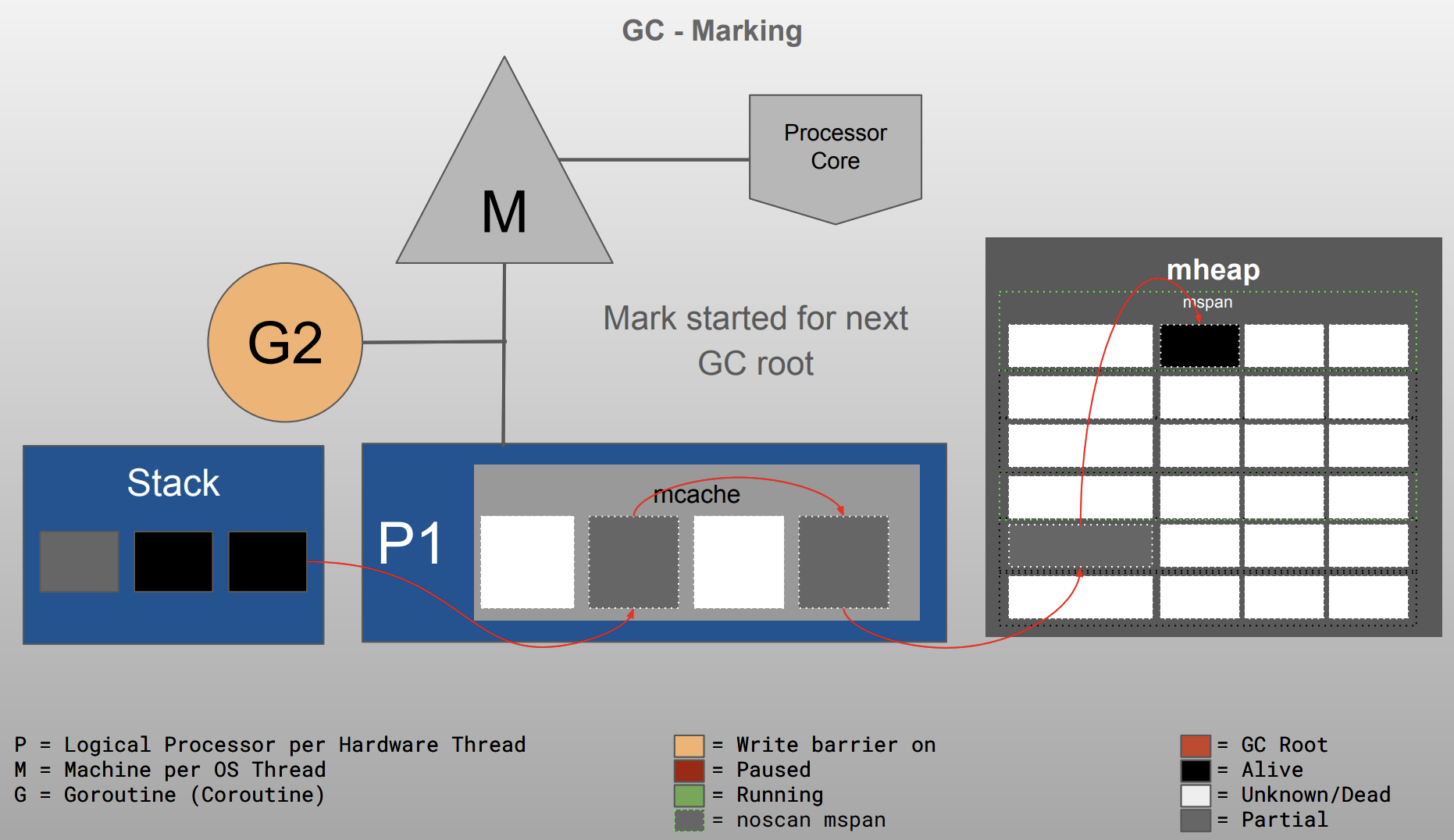
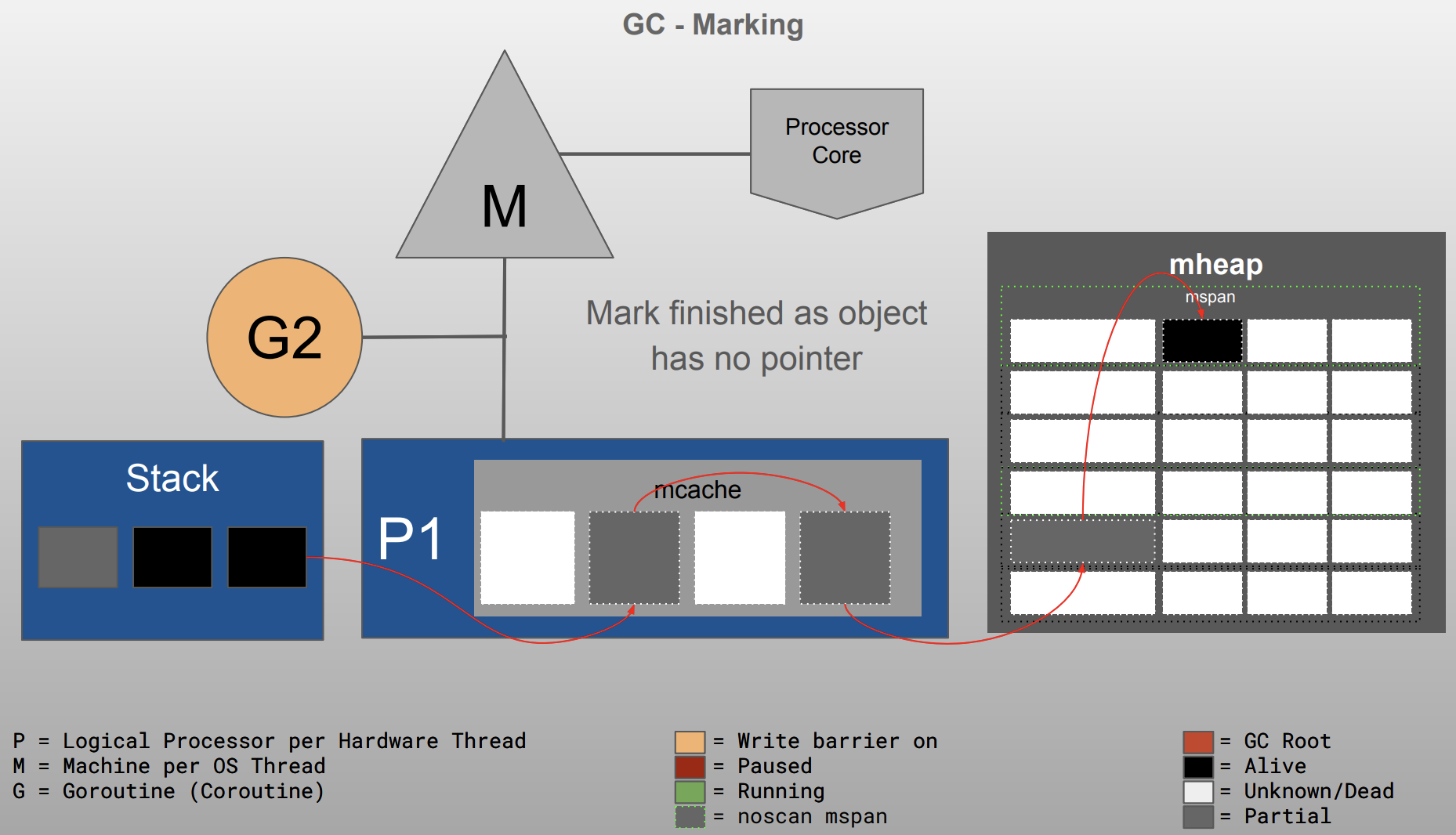
整体实现
Golang源码探索(三) GC的实现原理GO的GC是并行GC, 也就是GC的大部分处理和普通的go代码是同时运行的, 这让GO的GC流程比较复杂.
首先GC有四个阶段, 它们分别是:
- Sweep Termination: 对未清扫的span进行清扫, 只有上一轮的GC的清扫工作完成才可以开始新一轮的GC
- Mark: 扫描所有根对象, 和根对象可以到达的所有对象, 标记它们不被回收
- Mark Termination: 完成标记工作, 重新扫描部分根对象(要求STW)
- Sweep: 按标记结果清扫span
在GC过程中会有两种后台任务(G), 一种是标记用的后台任务, 一种是清扫用的后台任务.
- 标记用的后台任务会在需要时启动, 可以同时工作的后台任务数量大约是P的数量的25%, 也就是go所讲的让25%的cpu用在GC上的根据.
- 清扫用的后台任务在程序启动时会启动一个, 进入清扫阶段时唤醒.
源码入口
$GOROOT/src/runtime/mgc.go go触发gc会从gcStart函数开始
GC友好的代码
避免内存分配和赋值
- 尽量使用引用传递
- 初始化至合适的大小
- 复用内存