
简介
条分缕析分布式:到底什么是一致性?在证明CAP定理的原始论文Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web,C指的是linearizable consistency,也就是「线性一致性」。更精简的英文表达则是linearizability。而很多人在谈到CAP时,则会把这个C看成是强一致性(strong consistency)。这其实也没错,因为线性一致性的另一个名字,就是强一致性。只不过,相比「线性一致性」来说,「强一致性」并不是一个好名字。因为,从这个名字你看不出来它真实的含义(到底「强」在哪?)
那线性一致性是什么意思呢?它精确的形式化定义非常抽象,且难以理解。具体到一个分布式存储系统来说,线性一致性的含义可以用一个具体的描述来取代:对于任何一个数据对象来说,系统表现得就像它只有一个副本一样。显然,如果系统对于每个数据对象真的只存一个副本,那么肯定是满足线性一致性的。但是单一副本不具有容错性,所以分布式存储系统一般都会对数据进行复制(replication),也就是保存多个副本。这时,在一个分布式多副本的存储系统中,要提供线性一致性的保证,就需要付出额外的成本了。
分布式一致性技术是如何演进的?分布式一致性,简单的说就是在一个或多个进程提议了一个值后,使系统中所有进程对这个值达成一致。
basic-paxos
每个Node 同时充当了两个角色:Proposer和Acceptor,在实现过程中, 两个角色在同一个进程里面。专门提一个Proposer概念(只是一个角色概念)的好处是:对业务代码没有侵入性,也就是说,我们不需要在业务代码中实现算法逻辑,就可以像使用数据库一样访问后端的数据。
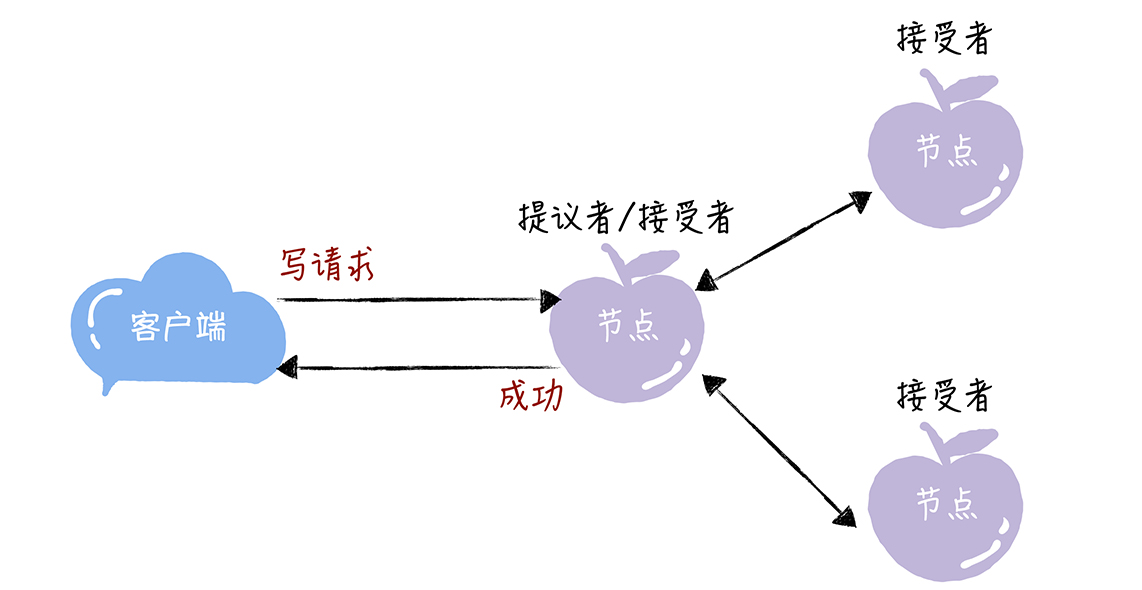
| proposer | acceptor | 作用 | |
|---|---|---|---|
| prepare阶段 | proposer 生成全局唯一且自增的proposal id,广播propose 只广播proposal id即可,无需value |
Acceptor 收到 propose 后,做出“两个承诺,一个应答” 1. 不再应答 proposal id 小于等于当前请求的propose 2. 不再应答 proposal id 小于 当前请求的 accept 3. 若是符合应答条件,返回已经accept 过的提案中proposal id最大的那个 propose 的value 和 proposal id, 没有则返回空值 |
争取提议权,争取到了提议权才能在Accept阶段发起提议,否则需要重新争取 学习之前已经提议的值 |
| accept阶段 | 提案生成规则 1. 从acceptor 应答中选择proposalid 最大的value 作为本次的提案 2. 如果所有的应答的天value为空,则可以自己决定value |
在不违背“两个承诺”的情况下,持久化当前的proposal id和value | 使提议形成多数派,提议一旦形成多数派则决议达成,可以开始学习达成的决议 |
Proposer 之间并不直接交互,Acceptor除了一个“存储”的作用外,还有一个信息转发的作用。从Acceptor的视角看,basic-paxos 及 multi-paxos 选举过程是协商一个值,每个Proposer提出的value 都可能不一样。所以第一阶段,先经由Acceptor将已提交的ProposerId 最大的value 尽可能扩散到Proposer(即决定哪个Proposer 是“意见领袖”)。第二阶段,再将“多数意见”形成“决议”(Acceptor持久化value)
目前比较好的通俗解释,以贿选来描述 如何浅显易懂地解说 Paxos 的算法? - GRAYLAMB的回答 - 知乎。
multi-paxos
《分布式协议与算法实战》Multi-Paxos 是一种思想,不是算法,缺失实现算法的必须编程细节。而 Multi-Paxos 算法是一个统称,它是指基于 Multi-Paxos 思想,通过多个 Basic Paxos 实例实现一系列值的共识的算法(比如 Chubby 的 Multi-Paxos 实现、Raft 算法等)。
Basic Paxos达成一次决议至少需要两次网络来回,并发情况下可能需要更多,极端情况下甚至可能形成活锁,效率低下。Multi-Paxos选举一个Leader,提议由Leader发起,没有竞争,解决了活锁问题。提议都由Leader发起的情况下,Prepare阶段可以跳过,将两阶段变为一阶段,提高效率。Multi-Paxos并不假设唯一Leader,它允许多Leader并发提议,不影响安全性,极端情况下退化为Basic Paxos。Multi-Paxos与Basic Paxos的区别并不在于Multi(Basic Paxos也可以Multi),只是在同一Proposer连续提议时可以优化跳过Prepare直接进入Accept阶段,仅此而已。
以 Chubby 的 Multi-Paxos 实现为例
- 主节点作为唯一提议者,这样就不存在多个提议者同时提交提案的情况,也就不存在提案冲突的情况
- 在 Chubby 中,主节点是通过执行 Basic Paxos 算法,进行投票选举产生的,并且在运行过程中,主节点会通过不断续租的方式来延长租期(Lease)。
- 在 Chubby 中实现了兰伯特提到的,“当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段”这个优化机制,减少非必须的协商步骤来提升性能。
- 在 Chubby 中,为了实现了强一致性,所有的读请求和写请求都由主节点来处理。也就是说,只要数据写入成功,之后所有的客户端读到的数据都是一致的。
Raft
强烈推荐细读 《In Search of an Understandable Consensus Algorithm》 论文,说清楚好多事情。
不同于Paxos直接从分布式一致性问题出发推导出来,Raft则是从多副本状态机的角度提出,使用更强的假设来减少需要考虑的状态,使之变的易于理解和实现。
通过选出leader,Raft 将一致性问题分解成为三个相对独立的子问题:
- leader选取, 在一个leader宕机之后必须要选取一个新的leader
- 日志复制,leader必须从client接收日志然后复制到集群中的其他服务器,并且强制要求其他服务器的日志保持和自己相同
- 安全性(Safety),一系列的规则约束
Raft 和 Paxos
Raft 算法属于 Multi-Paxos 算法,它是在兰伯特 Multi-Paxos 思想的基础上,做了一些简化和限制,比如增加了日志必须是连续的,只支持领导者、跟随者和候选人三种状态,在理解和算法实现上都相对容易许多。Raft 算法是现在分布式系统开发首选的共识算法。绝大多数选用 Paxos 算法的系统(比如 Cubby、Spanner)都是在 Raft 算法发布前开发的,当时没得选;而全新的系统大多选择了 Raft 算法(比如 Etcd、Consul、CockroachDB)。
《In Search of an Understandable Consensus Algorithm》: In order to enhance understandability, Raft separates the key elements of consensus, such as leader election, log replication, and safety, and it enforces a stronger degree of coherency to reduce the number of states that must be considered.
《In Search of an Understandable Consensus Algorithm》单决策(Single-decree)Paxos 是晦涩且微妙的:它被划分为两个没有简单直观解释的阶段,并且难以独立理解。正因为如此,它不能很直观的让我们知道为什么单一决策协议能够工作。为多决策 Paxos 设计的规则又添加了额外的复杂性和精巧性。我们相信多决策问题能够分解为其它更直观的方式。PS: 现实问题是多决策的,paxos 单决策出现在 多决策之前,彼时是以单决策的视角来考虑问题(在单决策场景下,选主不是很重要),又简单的以为将单决策 组合起来就可以支持 多决策。
Raft与Multi-Paxos中相似的概念:
| raft | Multi-Paxos |
|---|---|
| leader | proposer |
| term | proposal id |
| log entry | proposal |
| log index | instance id |
| Leader选举 | prepare 阶段 |
| 日志复制 | Accept阶段 |
Raft与Multi-Paxos的不同:
| raft | Multi-Paxos | |
|---|---|---|
| 领导者 | 强leader | 弱leader |
| 领导者选举权 | 具有已连续提交日志的副本 | 任意副本 |
| 日志复制 | 保证复制 | 允许空洞 |
| 日志提交 | 推进commit index | 异步的commit 消息 |
Raft 和 Paxos 最大的不同之处就在于 Raft 的强领导特性:Raft 使用leader选举作为一致性协议里必不可少的部分,并且将尽可能多的功能集中到了leader身上。这样就可以使得算法更加容易理解。例如,在 Paxos 中,leader选举和基本的一致性协议是正交的:leader选举仅仅是性能优化的手段,而且不是一致性所必须要求的。但是,这样就增加了多余的机制:Paxos 同时包含了针对基本一致性要求的两阶段提交协议和针对leader选举的独立的机制。相比较而言,Raft 就直接将leader选举纳入到一致性算法中,并作为两阶段一致性的第一步。这样就减少了很多机制。
强Leader在工程中一般使用Leader Lease和Leader Stickiness来保证:
- Leader Lease:上一任Leader的Lease过期后,随机等待一段时间再发起Leader选举,保证新旧Leader的Lease不重叠。
- Leader Stickiness:Leader Lease未过期的Follower拒绝新的Leader选举请求。
Leader 选举
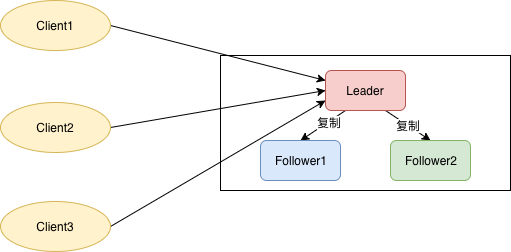
Raft协议比paxos的优点是 容易理解,容易实现。它强化了leader的地位,把整个协议可以清楚的分割成两个部分,并利用日志的连续性做了一些简化:
- Leader在时。leader来处理所有来自客户端的请求,由Leader向Follower同步日志 ==> 日志流动是单向的
- Leader挂掉了,选一个新Leader
- 在初始状态下,集群中所有的节点都是follower的状态。
- Raft 算法实现了随机超时时间的特性。也就是说,每个节点等待Leader节点心跳信息的超时时间间隔是随机的。等待超时时间最小的节点(以下称节点 A),它会最先因为没有等到Leader的心跳信息,发生超时。
- 这个时候,节点 A 就增加自己的任期编号,并推举自己为候选人,先给自己投上一张选票,然后向其他节点发送请求投票 RPC 消息,请它们选举自己为领导者。
- 如果其他节点接收到候选人 A 的请求投票 RPC 消息,在编号为 1 的这届任期内,也还没有进行过投票,那么它将把选票投给节点 A,并增加自己的任期编号。
- 如果候选人在选举超时时间内赢得了大多数的选票,那么它就会成为本届任期内新的领导者。节点 A 当选领导者后,他将周期性地发送心跳消息,通知其他服务器我是领导者,阻止跟随者发起新的选举,篡权。
在 Raft 算法中,约定了很多规则,主要有这样几点
- 领导者周期性地向所有跟随者发送心跳消息,通知大家我是领导者,阻止跟随者发起新的选举。
- 如果在指定时间内,跟随者没有接收到来自领导者的消息,那么它就认为当前没有领导者,推举自己为候选人,发起领导者选举。
- 在一次选举中,赢得大多数选票的候选人,将晋升为领导者。
- 在一个任期内,领导者一直都会是领导者,直到它自身出现问题(比如宕机),或者因为网络延迟,其他节点发起一轮新的选举。
- 在一次选举中,每一个服务器节点最多会对一个任期编号投出一张选票,并且按照“先来先服务”的原则进行投票。
- 日志完整性高的跟随者(也就是最后一条日志项对应的任期编号值更大,索引号更大),拒绝投票给日志完整性低的候选人。
- 如果一个候选人或者领导者,发现自己的任期编号比其他节点小,那么它会立即恢复成跟随者状态。
- 如果一个节点接收到一个包含较小的任期编号值的请求,那么它会直接拒绝这个请求。
在议会选举中,常出现未达到指定票数,选举无效,需要重新选举的情况。在 Raft 算法的选举中,也存在类似的问题,那它是如何处理选举无效的问题呢?其实,Raft 算法巧妙地使用随机选举超时时间的方法,把超时时间都分散开来,在大多数情况下只有一个服务器节点先发起选举,而不是同时发起选举,这样就能减少因选票瓜分导致选举失败的情况。如何避免候选人同时发起选举?
- 跟随者等待领导者心跳信息超时的时间间隔,是随机的;
- 如果候选人在一个随机时间间隔内,没有赢得过半票数,那么选举无效了,然后候选人发起新一轮的选举,也就是说,等待选举超时的时间间隔,是随机的。
日志复制
一旦选出了leader,它就开始接收客户端的请求。每一个客户端请求都包含一条需要被复制状态机(replicated state machine)执行的命令。leader把这条命令作为新的日志条目加入到它的日志中去,然后并行的向其他服务器发起 AppendEntries RPC ,要求其它服务器复制这个条目。当这个条目被安全的复制之后,leader会将这个条目应用到它的状态机中并且会向客户端返回执行结果。如果追随者崩溃了或者运行缓慢或者是网络丢包了,leader会无限的重试 AppendEntries RPC(甚至在它向客户端响应之后)直到所有的追随者最终存储了所有的日志条目。
一旦被leader创建的条目已经复制到了大多数的服务器上,这个条目就称为可被提交的(commited)
副本数据是以日志的形式存在的,日志是由日志项组成,日志项是一种数据格式,它主要包含用户指定的数据,也就是指令(Command),还包含一些附加信息,比如索引值(Log index)、任期编号(Term)。
- 指令:一条由客户端请求指定的、状态机需要执行的指令。你可以将指令理解成客户端指定的数据。
- 索引值:日志项对应的整数索引值。它其实就是用来标识日志项的,是一个连续的、单调递增的整数号码。
- 任期编号:创建这条日志项的领导者的任期编号。
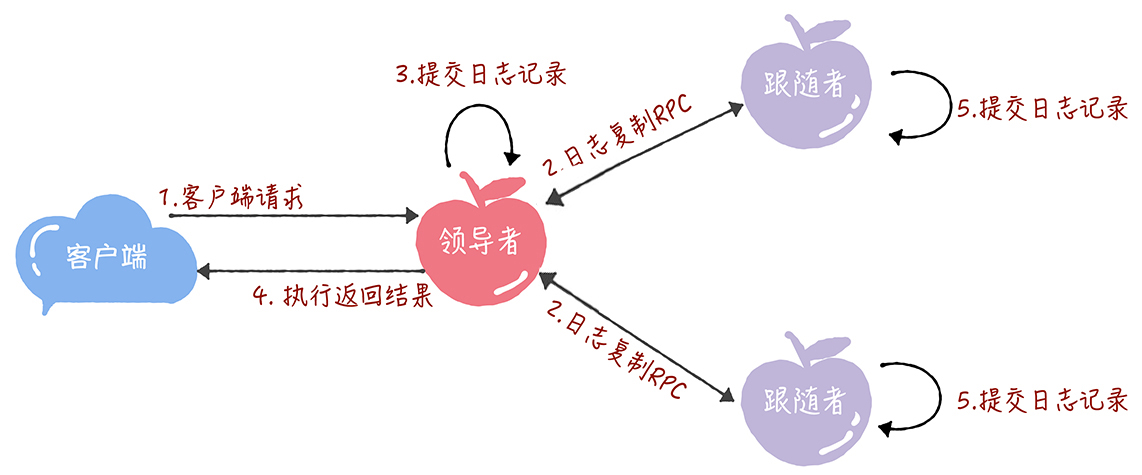
- 接收到客户端请求后,领导者基于客户端请求中的指令,创建一个新日志项,并附加到本地日志中。
- 领导者通过日志复制 RPC,将新的日志项复制到其他的服务器。
- 当领导者将日志项,成功复制到大多数的服务器上的时候,领导者会将这条日志项应用到它的状态机中。
- 领导者将执行的结果返回给客户端。
- 当跟随者接收到心跳信息,或者新的日志复制 RPC 消息后,如果跟随者发现领导者已经提交了某条日志项,而它还没应用,那么跟随者就将这条日志项应用到本地的状态机中。
在实际环境中,复制日志的时候,你可能会遇到进程崩溃、服务器宕机等问题,这些问题会导致日志不一致。那么在这种情况下,Raft 算法是如何处理不一致日志,实现日志的一致的呢?
- 领导者通过日志复制 RPC 的一致性检查,找到跟随者节点上,与自己相同日志项的最大索引值。也就是说,这个索引值之前的日志,领导者和跟随者是一致的,之后的日志是不一致的了。
- 领导者强制跟随者更新覆盖的不一致日志项,实现日志的一致。
跟随者中的不一致日志项会被领导者的日志覆盖,而且领导者从来不会覆盖或者删除自己的日志。
补充
复制模型
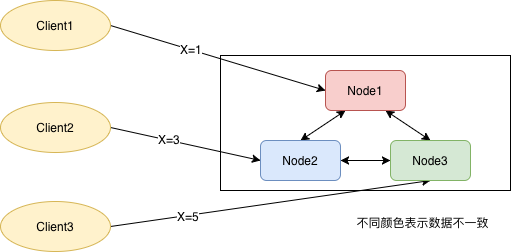
假设KV集群有三台机器,机器之间相互通信,把自己的值传播给其他机器,三个客户端并发的向集群发送三个请求,值X 应该是多少?是多少没关系,135都行,向一个client返回成功、其它client返回失败(或实际值)也可,关键是Node1、Node2、Node3 一致。
| Replicated State Machine | Primary-Backup System | |
|---|---|---|
| 中文 | 复制状态机 | |
| 应用的协议 | Paxos、Raft | Zab |
| mysql binlog的数据格式 | statement 存储的是原始的sql语句 |
raw 数据表的变化数据 |
| redis持久化的两种方式 | AOF 持久化的是客户端的set/incr/decr命令 |
RDB 持久化的是内存的快照 |
| 数据同步次数 | 客户端的写请求都要在节点之间同步 | 有时可以合并 |
如何理解ProposerId——逻辑锁
如何浅显易懂地解说 Paxos 的算法?Basic Paxos 的两个阶段可以看成多机下的一次读 version number + value(读阶段,原文中的准备阶段),然后拿读到的 version number 和 value 做一次 CAS (略有不同,但思想类似)(写阶段,原文中的接受阶段),非常直观。
类比一下,以mvcc 方式并发修改一行记录为例,假设一个student表, 带有version字段,当前version = 0, money = 100。线程1 和 线程2 都给zhangsan打钱(150,180), 则打钱过程分两步
- 读取到money = 100,此时version = 0
select money,version from student where name = zhangsan -
打钱
update money = 150,version=1 set student where name = zhangsan and version = 0- 如果在此期间 线程2没有修改过, 则vesion 为0,执行成功
- 若修改过,则因为实际version = 1 无法匹配数据记录,修改失败。
假设存在一个全局唯一自增id服务,线程2_id > 线程1_id,也可以换个方式
| 步骤 | 线程1 | 线程2 |
|---|---|---|
| 改version占坑 | update version = 线程1_id where name = zhangsan and version < 线程1_id |
|
| 改version占坑 | update version = 线程2_id where name = zhangsan and version < 线程2_id |
|
| 结果 | version = 线程2_id |
|
| 打钱 | update money = 150 set student where name = zhangsan and version = 线程1_id |
|
| 打钱 | update money = 180 set student where name = zhangsan and version = 线程2_id |
|
| 结果 | 失败 | 成功 |
paxos 与线程安全问题不同的地方是,paxos的node之间 是为了形成一致,而线程安全则是要么成功要么失败,所以有一点差异。
生活中面临的任何选择,最后都可以转换为一个问题:你想要什么(以及为此愿意牺牲什么)。任何不一致问题, 本质上都可以转换为一个一致问题。 一个队伍谁当老大 可以各不服气,但大家可以对“多票当选”取得一致,这就是所谓“民主”。你可以不尊重老大,但必须尊重价值观。而在basic-poxos 中,底层的“价值观”就是:谁的ProposerId 大谁的优先级更高。有了“优先级”/“价值观” 就可以让“无序”的世界变“有序”。
读写性能优化
Quorum NWR 中的三个要素NWR
- N 表示副本数,又叫做复制因子(Replication Factor)
- W又称写一致性级别(Write Consistency Level),表示成功完成 W 个副本更新,才完成写操作
- R,又称读一致性级别(Read Consistency Level),表示读取一个数据对象时需要读 R 个副本。你可以这么理解,读取指定数据时,要读 R 副本,然后返回 R 个副本中最新的那份数据
N、W、R 值的不同组合,会产生不同的一致性效果,具体来说,有这么两种效果:
- 当 W + R > N 的时候,对于客户端来讲,整个系统能保证强一致性,一定能返回更新后的那份数据。
- 当 W + R <= N 的时候,对于客户端来讲,整个系统只能保证最终一致性,可能会返回旧数据。
Kafka 数据可靠性深度解读虽然 Raft 算法能实现强一致性,也就是线性一致性(Linearizability),但需要客户端协议的配合。在实际场景中,我们一般需要根据场景特点,在一致性强度和实现复杂度之间进行权衡。比如 Consul 实现了三种一致性模型。
- default:客户端访问领导者节点执行读操作,领导者确认自己处于稳定状态时(在 leader leasing 时间内),返回本地数据给客户端,否则返回错误给客户端。在这种情况下,客户端是可能读到旧数据的,比如此时发生了网络分区错误,新领导者已经更新过数据,但因为网络故障,旧领导者未更新数据也未退位,仍处于稳定状态。
- consistent:客户端访问领导者节点执行读操作,领导者在和大多数节点确认自己仍是领导者之后返回本地数据给客户端,否则返回错误给客户端。在这种情况下,客户端读到的都是最新数据。
- stale:从任意节点读数据,不局限于领导者节点,客户端可能会读到旧数据。
当kafka producer 向 leader 发送数据时,可以通过 request.required.acks 参数来设置数据可靠性的级别:
- 1(默认):这意味着 producer 在 ISR 中的 leader 已成功收到的数据并得到确认后发送下一条 message。如果 leader 宕机了,则会丢失数据。
- 0:这意味着 producer 无需等待来自 broker 的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
- -1:producer 需要等待 ISR 中的所有 follower 都确认接收到数据后才算一次发送完成,可靠性最高。但是这样也不能保证数据不丢失,比如当 ISR 中只有 leader 时(前面 ISR 那一节讲到,ISR 中的成员由于某些情况会增加也会减少,最少就只剩一个 leader),这样就变成了 acks=1 的情况。
如果要提高数据的可靠性,在设置 request.required.acks=-1 的同时,也要 min.insync.replicas 这个参数 (可以在 broker 或者 topic 层面进行设置) 的配合,这样才能发挥最大的功效。
其它
分布式系统原理介绍副本控制协议指按特定的协议流程控制副本数据的读写行为,使得副本满足一定的可用性和一致性要求的分布式协议。
- 中心化(centralized)副本控制协议,由一个中心节点协调副本数据的更新、维护副本之间的一致性。所有的副本相关的控制交由中心节点完成。并发控制将由中心节点完成,从而使得一个分布式并发控制问题,简化为一个单机并发控制问题。所谓并发控制,即多个节点同时需要修改副本数据时,需要解决“写写”、“读写”等并发冲突。单机系统上常用加锁等方式进行并发控制。
- 去中心化(decentralized)副本控制协议
kafka 因为有更明确地业务规则,有一个专门的coordinator,选举过程进一步简化,复制log的逻辑基本一致。《软件架构设计》 多副本一致性章节的开篇就 使用kafka 为例讲了一个 做一个强一致的系统有多难。