简介
为什么需要反码和补码
有界/越界/溢出与取模
在数学的理论中,数字可以有无穷大,也有无穷小。现实中的计算机系统不可能表示无穷大或者无穷小的数字,都有一个上限和下限。加法加越界了就成了 取模运算。
符号位
在实际的硬件系统中,**计算机 CPU 的运算器只实现了加法器88,而没有实现减法器。那么计算机如何做减法呢?我们可以通过加上一个负数来达到这个目的。如何让计算机理解哪些是正数,哪些是负数呢?人们把二进制数分为有符号数(signed)和无符号数(unsigned)。如果是有符号数,那么最高位就是符号位。如果是无符号数,那么最高位就不是符号位,而是二进制数字的一部分。有些编程语言,比如 Java,它所有和数字相关的数据类型都是有符号位的;而有些编程语言,比如 C 语言,它有诸如 unsigned int 这种无符号位的数据类型。
比取模更“狠”——有符号数的溢出
对于 n 位的数字类型,符号位是 1,后面 n-1 位全是 0,我们把这种情形表示为 -2^(n-1)。n 位数字的最大的正值,其符号位为 0,剩下的 n-1 位都1,再增大一个就变为了符号位为 1,剩下的 n-1 位都为0。也就是n位 有符号最大值 加1 就变成了 n位有符号数界限范围内最小的负数——上溢出之后,又从下限开始
是不是有点扑克牌的意思, A 可以作为10JQKA 的最大牌,也可以作为A23456 的最小牌。
| 下限 | 上限 | |
|---|---|---|
| n位无符号数 | 0 | 2^n-1 |
| n位有符号数 | -2^(n-1) | 2^(n-1)-1 |
取模 可以将(最大值+1) 变成下限值,对于无符号数是0 ,对于有符号数是负数。
减法靠补码
原码就是我们看到的二进制的原始表示,是不是可以直接使用负数的原码来进行减法计算呢?答案是否定的,因为负数的原码并不适用于减法操作(加负数操作)
因为取模的特性,我们知道 i = i + 模数。 那么 i-j = i-j + 模数 也是成立的,进而i-j = i + (模数 -j)。模数 -j 即补码 可以对应到计算机的 位取反 和 加 1 操作
本质就是
- 加法器不区分 符号位和数据位
- 越界 等于 取模,对于有符号位的取模,可以使得 正数 变成负数
我们经常使用朴素贝叶斯算法 过滤垃圾短信,P(A|B)=P(A) * P(B/A) / P(B) 这个公式在数学上平淡无奇,但工程价值在于:实践中右侧数据比 左侧数据更容易获得。 cpu减法器也是类似的道理,减法器 = CPU 位取反 + 加法器
为什么要有堆和栈
- 在计算机诞生初期,在程序运行过程中没有栈帧(stack frame)需要去维护,所以内存采取的是静态分配策略,这虽然比动态分配要快,但是其一明显的缺点是程序所需的数据结构大小必须在编译期确定,而且不具备运行时分配的能力,这在现在来看是不可思议的。
- 在 1958 年,Algol-58 语言首次提出了块结构(block-structured),块结构语言通过在内存中申请栈帧来实现按需分配的动态策略。在过程被调用时,帧(frame)会被压到栈的最上面,调用结束时弹出。PS:一个block 内的变量要么都可用 要么都回收,降低了管理成本。但是后进先出(Last-In-First-Out, LIFO)的栈限制了栈帧的生命周期不能超过其调用者,而且由于每个栈帧是固定大小,所以一个过程的返回值也必须在编译期确定。所以诞生了新的内存管理策略——堆(heap)管理。
- 堆分配运行程序员按任意顺序分配/释放程序所需的数据结构——动态分配的数据结构可以脱离其调用者生命周期的限制,这种便利性带来的问题是垃圾对象的回收管理。
操作系统把磁盘上的可执行文件加载到内存运行之前,会做很多工作,其中很重要的一件事情就是把可执行文件中的代码,数据放在内存中合适的位置,并分配和初始化程序运行过程中所必须的堆栈,所有准备工作完成后操作系统才会调度程序起来运行。来看一下程序运行时在内存(虚拟地址空间)中的布局图:
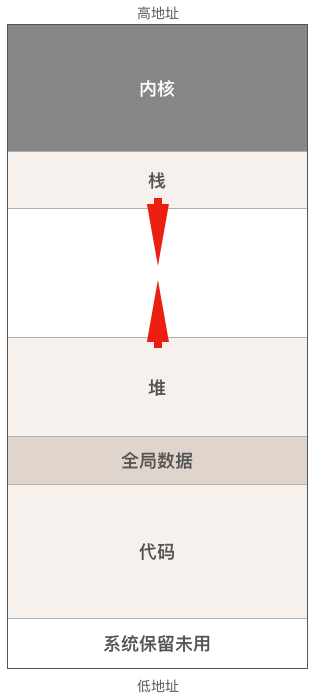
- 代码区,包括能被CPU执行的机器代码(指令)和只读数据比如字符串常量,程序一旦加载完成代码区的大小就不会再变化了。
- 数据区,包括程序的全局变量和静态变量(c语言有静态变量,而go没有),与代码区一样,程序加载完毕后数据区的大小也不会发生改变。
- 堆,程序运行时动态分配的内存都位于堆中,这部分内存由内存分配器负责管理。该区域的大小会随着程序的运行而变化。传统的c/c++代码就必须小心处理内存的分配和释放,而在go语言中,有垃圾回收器帮助我们
- 函数调用栈,简称栈。不管是函数的执行还是函数调用,栈都起着非常重要的作用
- 保存函数的局部变量;
- 向被调用函数传递参数;
- 返回函数的返回值;
- 保存函数的返回地址。返回地址是指从被调用函数返回后调用者应该继续执行的指令地址
每个函数在执行过程中都需要使用一块栈内存用来保存上述这些值,我们称这块栈内存为某函数的栈帧(stack frame)。当发生函数调用时,因为调用者还没有执行完,其栈内存中保存的数据还有用,所以被调用函数不能覆盖调用者的栈帧,只能把被调用函数的栈帧“push”到栈上,等被调函数执行完成后再把其栈帧从栈上“pop”出去,这样,栈的大小就会随函数调用层级的增加而生长,随函数的返回而缩小。栈的生长和收缩都是自动的,由编译器插入的代码自动完成,因此位于栈内存中的函数局部变量所使用的内存随函数的调用而分配,随函数的返回而自动释放,所以程序员不管是使用有垃圾回收还是没有垃圾回收的高级编程语言都不需要自己释放局部变量所使用的内存,这一点与堆上分配的内存截然不同。
AMD64 Linux平台下,栈是从高地址向低地址方向生长的,为什么栈会采用这种看起来比较反常的生长方向呢,具体原因无从考究,不过根据前面那张进程的内存布局图可以猜测,当初这么设计的计算机科学家是希望尽量利用内存地址空间,才采用了堆和栈相向生长的方式,因为程序运行之前无法确定堆和栈谁会消耗更多的内存,如果栈也跟堆一样向高地址方向生长的话,栈底的位置不好确定,离堆太近则堆内存可能不够用,离堆太远栈又可能不够用,于是乎就采用了现在这种相向生长的方式。
为什么需要栈
Memory Management/Stacks and Heaps
- The system stack, are used most often to provide frames. A frame is a way to localize information about subroutines(可以理解为函数).
- In general, a subroutine must have in its frame the return address (where to jump back to when the subroutine completes), the function’s input parameters. When a subroutine is called, all this information is pushed onto the stack in a specific order. When the function returns, all these values on the stack are popped back off, reclaimed to the system for later use with a different function call. In addition, subroutines can also use the stack as storage for local variables.
Demystifying memory management in modern programming languagesThe stack is used for static memory allocation and as the name suggests it is a last in first out(LIFO) stack. the process of storing and retrieving data from the stack is very fast as there is no lookup required, you just store and retrieve data from the topmost block on it.
栈 (stack) 是现代计算机程序里最为重要的概念之一,几乎每一个程序都使用了栈,没有栈就没有函数,没有局部变量,也就没有我们如今能够看见的所有的计算机语言。在数据结构中,栈被定义为一个特殊的容器,先进后出。在计算机系统中,栈则是一个具有以上属性的动态内存区域。栈在程序运行中具有举足轻重的地位。最重要的,栈保存了一个函数调用所需要的维护信息,这常常被称为堆栈帧(Stack Frame)。
根据上文可以推断:为什么需要栈?为了支持函数。OS设计体现了对进程、线程的支持,直接提供系统调用创建进程、线程,但就进程/线程内部来说,os 认为代码段是一个指令序列,最多jump几下,指令操作的数据都是事先分配好的(数据段主要容纳全局变量,且是静态分配的),没有直接体现对函数的支持(只是硬件层面上提供了栈指针寄存器,编译器实现函数参数、返回值压栈、出栈)。没有函数,代码会重复,有了函数,才有局部变量一说,有了局部变量才有了数据的动态申请与分配一说。函数及其局部变量 是最早的 代码+数据的封装。
加入线程的因素:每个线程有独立的栈(栈一般作为线程独占的内存空间,使用时也就无需担心并发安全),而栈既保留了变量的值,也保留了函数的调用关系、参数和返回值。
Go 垃圾回收(二)——垃圾回收是什么?GC 不负责回收栈中的内存,为什么呢?主要原因是栈是一块专用内存,专门为了函数执行而准备的,存储着函数中的局部变量以及调用栈。除此以外,栈中的数据都有一个特点——简单。比如局部变量就不能被函数外访问,所以这块内存用完就可以直接释放。正是因为这个特点,栈中的数据可以通过简单的编译器指令自动清理,也就不需要通过 GC 来回收了。
栈空间可以被重复利用,新增和删除栈的数据只需要移动栈顶指针即可,节约了重复申请和释放内存的操作。基于栈被重复利用的特性,这块内存很大概率能被 CPU 的缓存命中,从而可以极大地提升访问的速度。
函数调用栈相关的指令和寄存器
- rsp 栈顶寄存器和rbp栈基址寄存器:这两个寄存器都跟函数调用栈有关,其中rsp寄存器一般用来存放函数调用栈的栈顶地址,而rbp寄存器通常用来存放函数的栈帧起始地址,编译器一般使用这两个寄存器加一定偏移的方式来访问函数局部变量或函数参数。比如:
mov 0x8(%rsp),%rdx call 目标地址指令执行函数调用。CPU执行call指令时首先会把rip寄存器中的值入栈,然后设置rip值为目标地址,又因为rip寄存器决定了下一条需要执行的指令,所以当CPU执行完当前call指令后就会跳转到目标地址去执行。一条call指令修改了3个地方的值:rip寄存器、rsp和栈。- ret指令从被调用函数返回调用函数,它的实现原理是把call指令入栈的返回地址弹出给rip寄存器。一条call指令修改了3个地方的值:rip寄存器、rsp和栈。
一些有意思的表述:
- 函数调用后的返回地址会保存到堆栈中。jmp跳过去就不知道怎么回来了,而通过call跳过去后,是可以通过ret指令直接回来的。call指令保存eip的地方叫做栈,在内存里,ret指令执行的时候是直接取出栈中保存的eip值 并恢复回去,达到返回的效果。PS: rsp 和 rsp 就好像一个全局变量,一经改变,call/ret/push/pop 这些指令的行为就都改变了。
- 函数的局部状态也可以保存到堆栈中。在汇编环境下,寄存器是全局可见的,不能用于充当局部变量。借鉴call指令保存返回地址的思路,如果,在每一层函数中都将当前比较关键的寄存器保存到堆栈中,然后才去调用下一层函数,并且,下层的函数返回的时候,再将寄存器从堆栈中恢复出来,这样也就能够保证下层的函数不会破坏掉上层函数的状了。
go调度器源代码情景分析之九:操作系统线程及线程调度线程是什么?进程切换、线程切换、协程切换、函数切换,cpu 只有一个,寄存器也只有一批,想要并发,就得对硬件分时(cpu和寄存器)使用,分时就得save/load,切换时保留现场,返回时恢复现场。线程调度时操作系统需要保存和恢复的寄存器除了通用寄存器之外,还包括指令指针寄存器rip以及与栈相关的栈顶寄存器rsp和栈基址寄存器rbp,rip寄存器决定了线程下一条需要执行的指令,2个栈寄存器确定了线程执行时需要使用的栈内存。所以恢复CPU寄存器的值就相当于改变了CPU下一条需要执行的指令,同时也切换了函数调用栈,因此从调度器的角度来说,线程至少包含以下3个重要内容:
- 一组通用寄存器的值
- 将要执行的下一条指令的地址
- 栈
| 现场 | 创建成本 | |
|---|---|---|
| 函数调用 | 堆栈和指令寄存器 | |
| 协程切换 | 少数几个寄存器 | 协程struct |
| 线程切换 | 寄存器 | 线程struct + 堆栈空间 |
| 进程切换 | 几乎所有寄存器 | 进程struct + 堆栈空间,文件描述符 |
所以操作系统对线程的调度可以简单的理解为内核调度器对不同线程所使用的寄存器和栈的切换。最后,我们对操作系统线程下一个简单且不准确的定义:操作系统线程是由内核负责调度且拥有自己私有的一组寄存器值和栈的执行流。
为什么需要堆?
Heap is used for dynamic memory allocation(data with dynamic size ) and unlike stack, the program needs to look up the data in heap using pointers.
光有栈,对于面向过程的程序设计还远远不够,因为栈上的数据在函数返回的时候就会被释放掉,所以无法将数据传递至函数外部。而全局变量没有办法动态地产生,只能在编译的时候定义,有很多情况下缺乏表现力,在这种情况下,堆(Heap)是一种唯一的选择。The heap is an area of dynamically-allocated memory that is managed automatically by the operating system or the memory manager library. Memory on the heap is allocated, deallocated, and resized regularly during program execution, and this can lead to a problem called fragmentation. 堆适合管理生存期较长的一些数据,这些数据在退出作用域以后也不会消失。
如果堆上有足够的空间的满足我们代码的内存申请,内存分配器可以完成内存申请无需内核参与,否则将通过操作系统调用(brk)进行扩展堆,通常是申请一大块内存。(对于 malloc 大默认指的是大于 MMAP_THRESHOLD 个字节 - 128KB)。
调度系统设计精要
调度系统设计精要在计算机科学中,调度就是一种将任务(Work)分配给资源的方法。任务可能是虚拟的计算任务,例如线程、进程或者数据流,这些任务会被调度到硬件资源上执行,例如:处理器 CPU 等设备。调度模块的核心作用就是对有限的资源进行分配以实现最大化资源的利用率或者降低系统的尾延迟,调度系统面对的就是资源的需求和供给不平衡的问题。
| 任务 | 资源 | 描述 | |
|---|---|---|---|
| 操作系统 | 线程 | cpu | |
| Go | 协程 | cpu线程 | |
| Kubernetes | pod | node | 为待运行的工作负载 Pod 绑定运行的节点 Node |
| CDN的资源调度 | |||
| 订单调度 | |||
| 离线任务调度 |