
前言
Scheduling In Go : Part I - OS Scheduler Scheduling In Go : Part II - Go Scheduler Scheduling In Go : Part III - Concurrency
过去的语言(如C语言)只是提供标准的库,让你访问操作系统的线程管理功能,包括信号量、同步互斥什么的。Java语言增加了一些专门处理多线程的元素,比如synchronized关键字。go语言又更进一步,把操作系统的线程进行了封装,变成了轻量级的goroutine。
万字长文深入浅出 Golang Runtime调度在计算机中是分配工作所需资源的方法,linux的调度为CPU找到可运行的线程,而Go的调度是为M(线程)找到P(内存、执行票据)和可运行的G。
The Go scheduler为什么Go 运行时需要一个用户态的调度器?
- 线程调度成本高,比如context switch比如陷入内核执行
- 操作系统在Go模型下不能做出好的调度决策。os 只能根据时间片做一些简单的调度。
调度模型的演化
// 程序启动时的初始化代码
......
for i := 0; i < N; i++{ // 创建N个操作系统线程执行schedule函数
create_os_thread(schedule) // 创建一个操作系统线程执行schedule函数
}
//schedule函数实现调度逻辑
func schedule() {
for { // 调度循环
// 根据某种算法从M个goroutine中找出一个需要运行的goroutine
g = find_a_runnable_goroutine_from_M_goroutines()
run_g(g) // CPU运行该goroutine,直到需要调度其它goroutine才返回
save_status_of_g(g) // 保存goroutine的状态,主要是寄存器的值
}
}
创建一个操作系统线程执行schedule函数。
GM模型
go1.1 之前都是该模型, 单线程调度器(0.x) 和多线程调度器(1.0),单线程调度器(0.x) 核心逻辑如下
static void scheduler(void) {
G* gp;
lock(&sched);
if(gosave(&m->sched)){ // 保存栈寄存器和程序计数器
lock(&sched);
gp = m->curg;
switch(gp->status){
case Grunnable:
case Grunning:
gp->status = Grunnable;
gput(gp);
break;
...
}
notewakeup(&gp->stopped);
}
gp = nextgandunlock(); // 获取下一个需要运行的 Goroutine 并解锁调度器
noteclear(&gp->stopped);
gp->status = Grunning;
m->curg = gp; // 修改全局线程 m 上要执行的 Goroutine;
g = gp;
gogo(&gp->sched); // 运行最新的 Goroutine
}
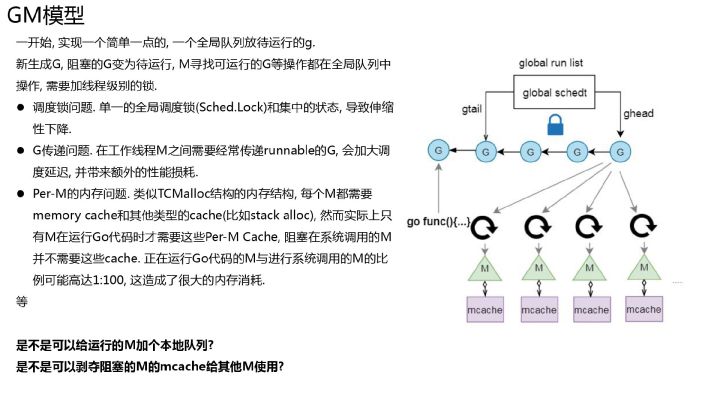
在这个阶段,goroutine 调度跟 java 的ThreadPool 是一样一样的,除了io操作会阻塞线程外,java Executor也可以视为一个用户态线程调度框架。runnable 表示运行逻辑 提交到queue,ThreadPool 维持多个线程 从queue 中取出runnable 并执行。
GPM模型
static void schedule(void) {
G *gp;
top:
if(runtime·gcwaiting) { // 如果当前运行时在等待垃圾回收,调用 runtime.gcstopm 函数;
gcstopm();
goto top;
}
gp = runqget(m->p); // 从本地运行队列中获取待执行的 Goroutine;
if(gp == nil)
gp = findrunnable(); // 从全局的运行队列中获取待执行的 Goroutine;
...
execute(gp); // 在当前线程 M 上运行 Goroutine
}
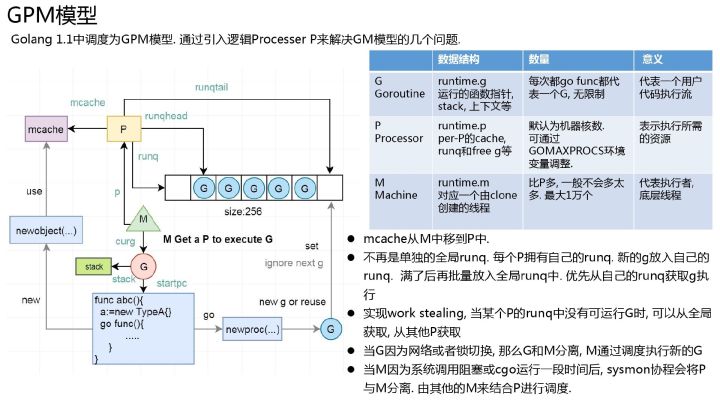
当有了一个P 存在后,一些数据结构(跨协程的) 就顺势放在了P 中,包括与性能追踪、垃圾回收和计时器相关的字段。
go java 都有runtime,runtime 不只是一对一辅助执行代码,本身也会运行很多协程/线程,以提高io、定时器、gc等的执行效率,为上层高级特性提供支持。在目前的runtime中,线程、处理器、网络轮询器、运行队列、全局内存分配器状态、内存分配缓存和垃圾收集器都是全局资源。
Go: Goroutine, OS Thread and CPU Management 来讲述GPM时,用到了 orchestration 这个词, Go has its own scheduler to distribute goroutines over the threads. This scheduler defines three main concepts
goroutine调度模型的四个抽象及其数据结构
Go 语言设计与实现-调度器goroutine调度模型4个重要结构,分别是M、G、P、Sched,前三个定义在runtime.h中,Sched定义在proc.c中。
P 的数量决定了系统内最大可并行的 G 的数量(前提:物理 CPU 核数 >= P 的数量)。P 的数量由用户设置的 GoMAXPROCS 决定,但是不论 GoMAXPROCS 设置为多大,P 的数量最大为 256。M 的数量是不定的,由 Go Runtime 调整,为了防止创建过多 OS 线程导致系统调度不过来,目前默认最大限制为 10000 个。
理解 M、P、G 三者的关系,可以通过经典的地鼠推车搬砖的模型来说明其三者关系:地鼠(Gopher)的工作任务是:工地上有若干砖头,地鼠借助小车把砖头运送到火种上去烧制。M 就可以看作图中的地鼠,P 就是小车,G 就是小车里装的砖。
G
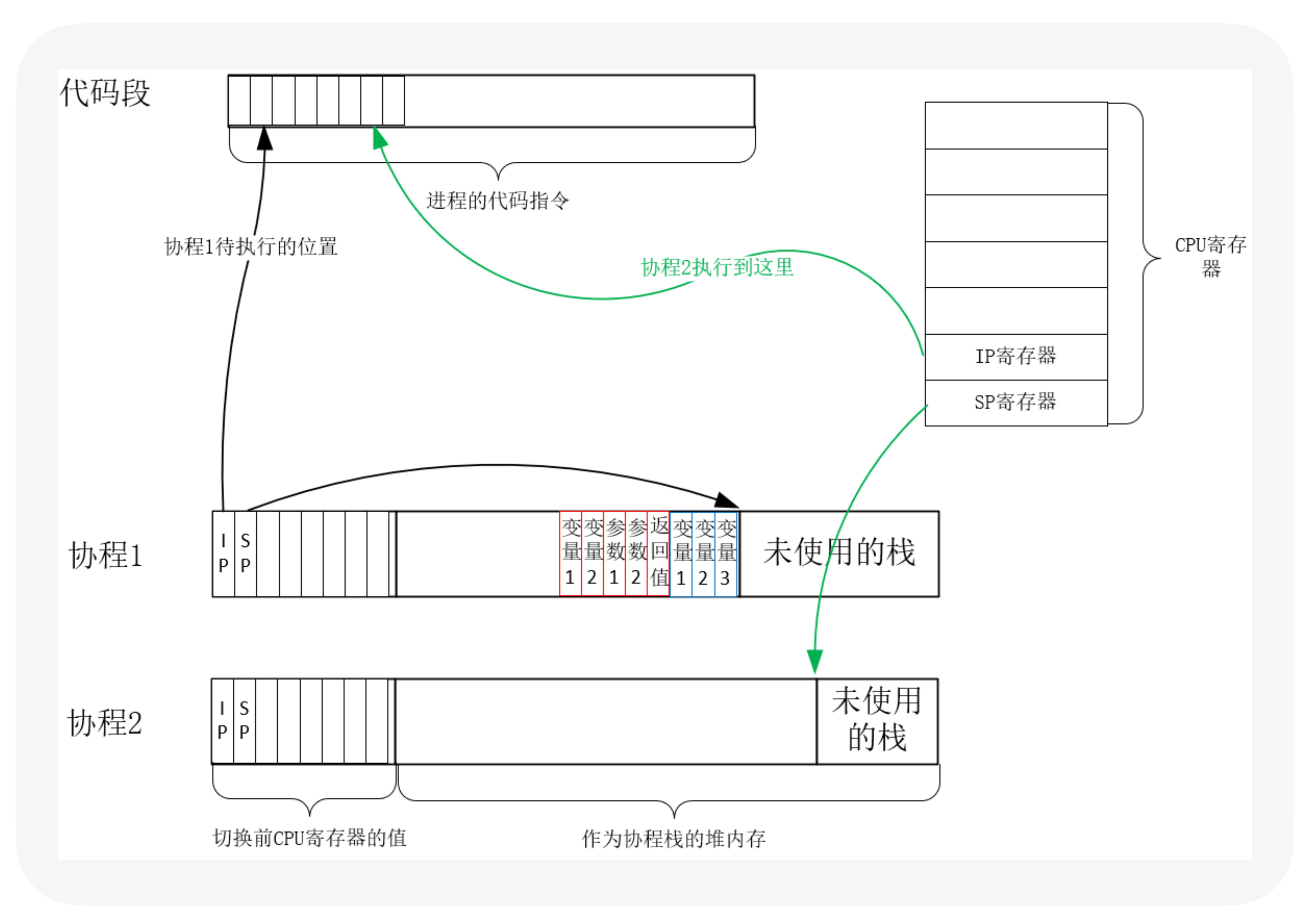
Go语言goroutine调度器概述(11)系统线程对goroutine的调度与内核对系统线程的调度原理是一样的,实质都是通过保存和修改CPU寄存器的值来达到切换线程/goroutine的目的。为了实现对goroutine的调度,需要引入一个数据结构来保存CPU寄存器的值(具体的说就是栈指针、pc指针,题外话:有栈指针之后,栈数据也要实现准备好)以及goroutine的其它一些状态信息。调度器代码可以通过g对象来对goroutine进行调度,当goroutine被调离CPU时,调度器代码负责把CPU寄存器的值保存在g对象的成员变量之中,当goroutine被调度起来运行时,调度器代码又负责把g对象的成员变量所保存的寄存器的值恢复到CPU的寄存器。PS:函数不是并发执行体,所以函数切换只需要保留栈指针就可以了。
G是goroutine实现的核心结构,G维护了goroutine需要的栈、程序计数器以及它所在的M等信息。一个协程代表了一个执行流,执行流有需要执行的函数(startpc),有函数的入参,有当前执行流的状态和进度(对应 CPU 的 PC 寄存器和 SP 寄存器),当然也需要有保存状态的地方,用于执行流恢复。
type g struct {
m *m // 当前 Goroutine 占用的线程,可能为空;
sched gobuf // 存储 Goroutine 的调度相关的数据
atomicstatus uint32 // Goroutine 的状态
goid int64 // Goroutine 的 ID,该字段对开发者不可见
// 与栈相关
stack stack // 描述了当前 Goroutine 的栈内存范围 [stack.lo, stack.hi)
stackguard0 uintptr // 用于调度器抢占式调度
// 与抢占相关
preempt bool // 抢占信号
preemptStop bool // 抢占时将状态修改成 `_Gpreempted`
preemptShrink bool // 在同步安全点收缩栈
// defer 和 panic 相关
_panic *_panic // 最内侧的 panic 结构体
_defer *_defer // 最内侧的延迟函数结构体
}
type gobuf struct { // 让出cpu 时,将寄存器信息保留在这里。即将获得cpu时,将这里的信息加载到寄存器
sp uintptr // 栈指针(Stack Pointer)
pc uintptr // 程序计数器(Program Counter)
g guintptr // 持有 runtime.gobuf 的 Goroutine
ret sys.Uintreg // 系统调用的返回值
...
}
结构体 g 的字段 atomicstatus 就存储了当前 Goroutine 的状态,可选值为
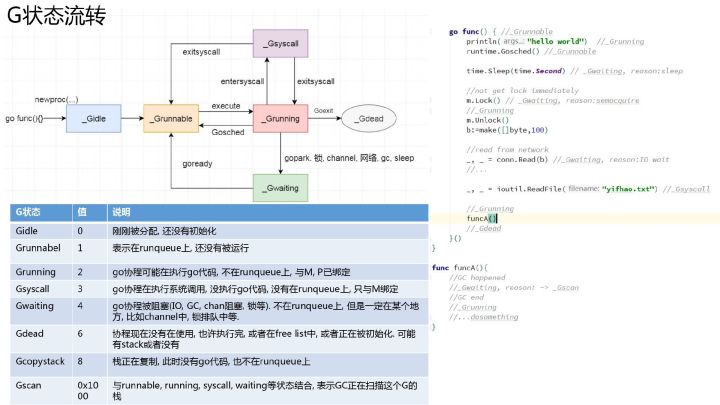
虽然 Goroutine 在运行时中定义的状态非常多而且复杂,但是我们可以将这些不同的状态聚合成最终的三种:等待中(比如正在执行系统调用或同步操作)、可运行、运行中(占用M),在运行期间我们会在这三种不同的状态来回切换。
Sched
Go语言goroutine调度器概述(11)要实现对goroutine的调度,仅仅有g结构体对象是不够的,至少还需要一个存放所有(可运行)goroutine的容器,便于工作线程寻找需要被调度起来运行的goroutine,于是Go调度器又引入了schedt结构体,一方面用来保存调度器自身的状态信息,另一方面它还拥有一个用来保存goroutine的运行队列。因为每个Go程序只有一个调度器,所以在每个Go程序中schedt结构体只有一个实例对象,该实例对象在源代码中被定义成了一个共享的全局变量,这样每个工作线程都可以访问它以及它所拥有的goroutine运行队列,我们称这个运行队列为全局运行队列。
// src/runtime/runtime2.go
type schedt struct {
// Global runnable queue.
runq gQueue
runqsize int32
// Global cache of dead G's.
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
gcwaiting uint32 // gc is waiting to run
}
P
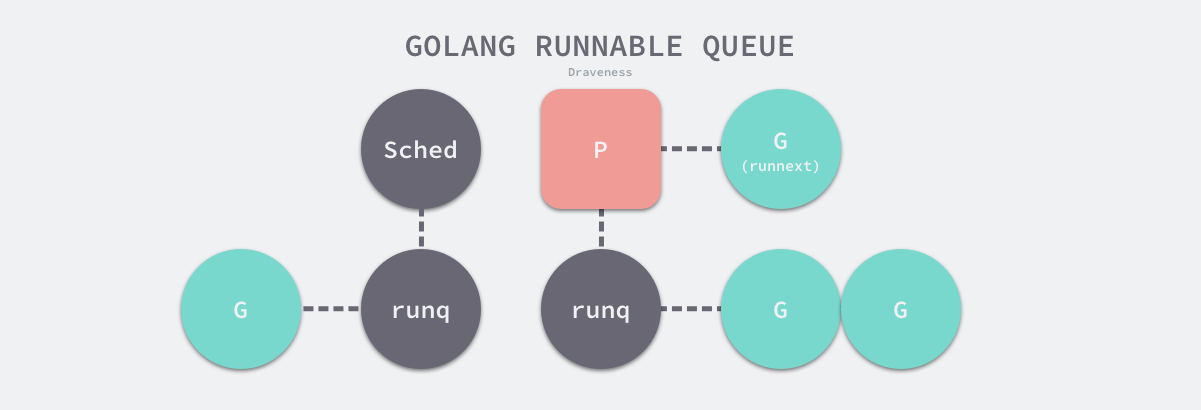
为什么引入Processor 的概念?为什么把全局队列打散?对该队列的操作均需要竞争同一把锁, 导致伸缩性不好. 一个协程派生的协程也会放入全局的队列, 大概率是被其他 m运行了, “父子协程” 被不同的m 运行,内存亲和性不好。 ==> 为每一个 M 维护一个运行队列 runq ==> 如果G 包含同步调用,会导致执行G 的M阻塞,进而导致 与M 绑定的所有runq 上的 G 无法执行 ==> 将M 和 runq 拆分,M 可以阻塞,M 阻塞后,runq 交由新的M 执行 ==> 对runq 及相关信息进行抽象 得到P。 go1.1 以P 为基础实现了基于工作窃取的调度器。
The Go scheduler为什么我们需要P,我们不能把任务队列直接挂载到M上而去掉P吗?答案是不行。原因是当运行着的线程由于某些原因需要阻塞时,我们需要通过P把任务队列挂载到其它线程中。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。
P全称是Processor,处理器,表示调度的上下文,它可以被看做一个运行于线程 M 上的本地调度器,所以它维护了一个goroutine队列(环形链表),里面存储了所有需要它来执行的goroutine。通过处理器 P 的调度,每一个内核线程都能够执行多个 Goroutine,它能在 Goroutine 进行一些 I/O 操作时及时切换,提高线程的利用率。
struct P {
Lock;
uint32 status;
P* link;
uint32 tick;
M* m; // 执行runq 的M
MCache* mcache;
G** runq; // 运行的 Goroutine 组成的环形的运行队列
int32 runqhead;
int32 runqtail;
int32 runqsize;
G* gfree;
int32 gfreecnt;
};
runhead、runqtail、runq 以及 runnext 等字段表示P持有的运行队列,该运行队列是一个使用数组构成的环形链表,其中最多能够存储 256 个指向Goroutine 的指针,除了 runq 中能够存储待执行的 Goroutine 之外,runnext 指向的 Goroutine 会成为下一个被运行的 Goroutine
p 结构体中的状态 status 可选值
- _Pidle 处理器没有运行用户代码或者调度器,运行队列为空
- _Prunning 被线程 M 持有,并且正在执行用户代码或者调度器
- _Psyscall 没有执行用户代码,当前线程陷入系统调用
- _Pgcstop 被线程 M 持有,当前处理器由于垃圾回收被停止
- _Pdead 当前处理器已经不被使用
M
调度器最多可以创建 10000 个线程,但是其中大多数的线程都不会执行用户代码(可能陷入系统调用),最多只会有 GOMAXPROCS 个活跃线程能够正常运行。在默认情况下,运行时会将 GOMAXPROCS 设置成当前机器的核数。
M代表内核级线程,一个M就是一个线程,goroutine就是跑在M之上 ;
type m struct {
g0 *g // 持有调度栈的 Goroutine
curg *g // 在当前线程上运行的用户 Goroutine
p puintptr // 正在运行代码的处理器 p
nextp puintptr // 暂存的处理器 nextp
oldp puintptr // 执行系统调用之前的使用线程的处理器 oldp
...
}
g0 是一个运行时中比较特殊的 Goroutine,它会深度参与运行时的调度过程,包括 Goroutine 的创建、大内存分配和 CGO 函数的执行。
如果只有一个工作线程,那么就只会有一个m结构体对象,问题就很简单,定义一个全局的m结构体变量就行了。可是我们有多个工作线程和多个m需要一一对应,怎么办呢?线程本地存储其实就是线程私有的全局变量,每个工作线程在刚刚被创建出来进入调度循环之前就利用线程本地存储机制为该工作线程实现了一个指向m结构体实例对象的私有全局变量,这样在之后的代码中就使用该全局变量来访问自己的m结构体对象,进而访问与m相关联的p和g对象。
重要的全局变量
allgs []*g // 保存所有的g
allm *m // 所有的m构成的一个链表,包括下面的m0
allp []*p // 保存所有的p,len(allp) == gomaxprocs
ncpu int32 // 系统中cpu核的数量,程序启动时由runtime代码初始化
gomaxprocs int32 // p的最大值,默认等于ncpu,但可以通过GOMAXPROCS修改
sched schedt // 调度器结构体对象,记录了调度器的工作状态
m0 m // 代表进程的主线程
g0 g // m0的g0,也就是m0.g0 = &g0
函数运行
$GOROOT/src/runtime/proc.go
goroutine 创建
go 关键字在编译期间通过 stmt 和 call 两个方法将该关键字转换成 newproc 函数调用,代码的路径和原理与 defer 关键字几乎完全相同。
我们向 newproc 中传入一个表示函数的指针 funcval,在这个函数中我们还会获取当前调用 newproc 函数的 Goroutine 以及调用方的程序计数器 PC,然后调用 newproc1 函数:
func newproc(siz int32, fn *funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg()
pc := getcallerpc()
newproc1(fn, (*uint8)(argp), siz, gp, pc)
}
newproc1 函数的主要作用就是创建一个运行传入参数 fn 的 g 结构体,并对其各个成员赋值。
func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {
_g_ := getg()
siz := narg
siz = (siz + 7) &^ 7
_p_ := _g_.m.p.ptr()
// 获取或创建一个 g struct
newg := gfget(_p_)
if newg == nil {
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg)
}
// 获取新创建 Goroutine 的堆栈并直接通过 memmove 将函数 fn 需要的参数全部拷贝到栈中
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize
totalSize += -totalSize & (sys.SpAlign - 1)
sp := newg.stack.hi - totalSize
spArg := sp
if narg > 0 {
memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))
}
// 初始化新 Goroutine 的栈指针、程序计数器、调用方程序计数器等属性
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = funcPC(goexit) + sys.PCQuantum
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
newg.startpc = fn.fn
if isSystemGoroutine(newg, false) {
atomic.Xadd(&sched.ngsys, +1)
}
// 将新 Goroutine 的状态从 _Gdead 切换成 _Grunnable 并设置 Goroutine 的标识符(goid)
casgstatus(newg, _Gdead, _Grunnable)
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
// runqput 函数会将新的 Goroutine 添加到处理器 P 的运行队列上
runqput(_p_, newg, true)
// 如果符合条件,当前函数会通过 wakep 来添加一个新的 p 结构体来执行 Goroutine
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
wakep()
}
}
协程切换/当前协程保留现场,退出执行
协程切换的原因一般有以下几种情况:
- 系统调用;Go 语言通过 Syscall 和 Rawsyscall 等使用汇编语言编写的方法封装了操作系统提供的所有系统调用
- 同步和编配;如果原子、互斥量或通道操作调用将导致 Goroutine 阻塞,调度器可以将之切换到一个新的 Goroutine 去运行。一旦 Goroutine 可以再次运行,它就可以重新排队,并最终在M上切换回来。
- 抢占式调度时间片结束;
- 垃圾回收
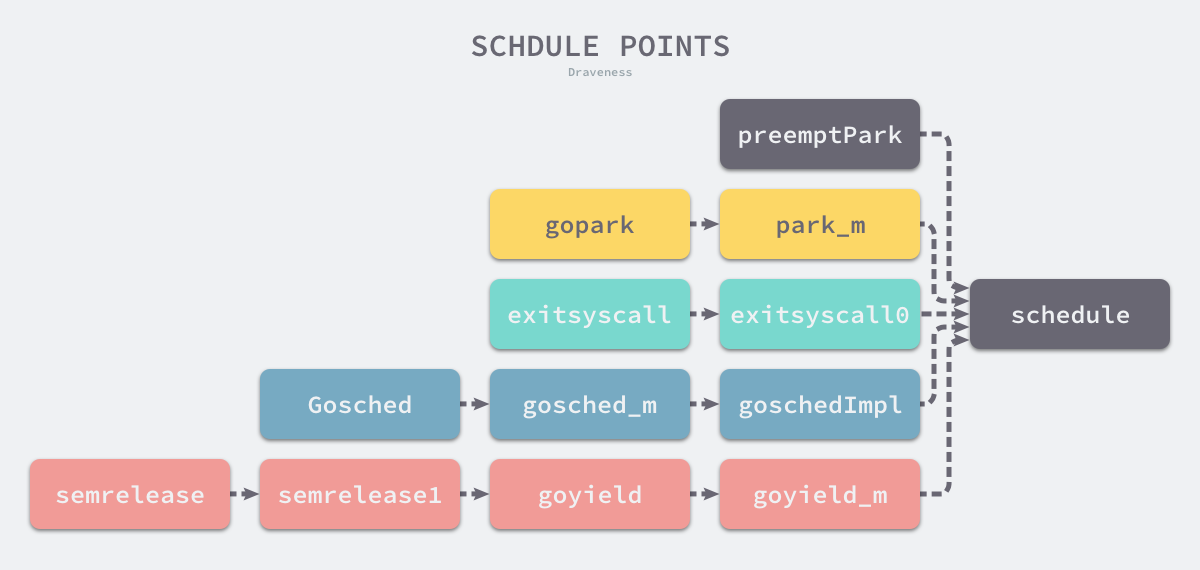
就好像linux 进程会主动调用schedule() 触发调度让出cpu 控制权,只是linux 多了时间片中断主动触发调度而已。
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) {
mp := acquirem()
gp := mp.curg
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waittraceev = traceEv
mp.waittraceskip = traceskip
releasem(mp)
mcall(park_m)
}
gopark 函数中会更新当前处理器(mp)的状态并在处理器上设置该 Goroutine 的等待原因。gopark中调用的 park_m 函数会将当前 Goroutine 的状态从 _Grunning 切换至 _Gwaiting 并调用 waitunlockf 函数进行解锁
func park_m(gp *g) {
_g_ := getg()
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
if fn := _g_.m.waitunlockf; fn != nil {
ok := fn(gp, _g_.m.waitlock)
_g_.m.waitunlockf = nil
_g_.m.waitlock = nil
if !ok {
casgstatus(gp, _Gwaiting, _Grunnable)
execute(gp, true) // Schedule it back, never returns.
}
}
schedule()
}
协程调度
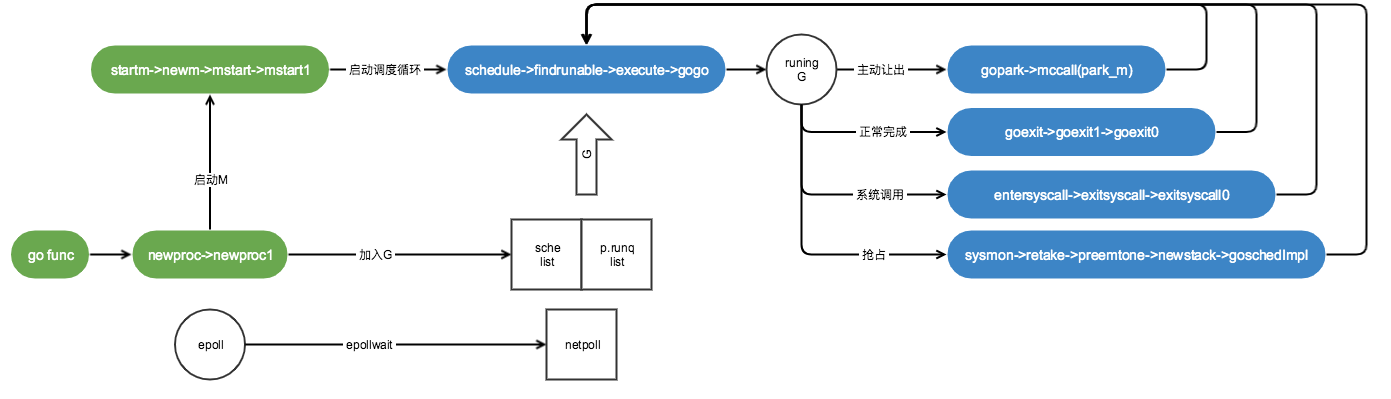
在大多数情况下都会调用 schedule 触发一次 Goroutine 调度,这个函数的主要作用就是从不同的地方查找待执行的 Goroutine:
func schedule() {
_g_ := getg()
top:
var gp *g
var inheritTime bool
// 有一定几率会从全局的运行队列中选择一个 Goroutine;为了保证调度的公平性,每个工作线程每进行61次调度就需要优先从全局运行队列中获取goroutine出来运行,因为如果只调度本地运行队列中的goroutine,则全局运行队列中的goroutine有可能得不到运行
if gp == nil {
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
// 从当前处理器本地的运行队列中查找待执行的 Goroutine;
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
if gp != nil && _g_.m.spinning {
throw("schedule: spinning with local work")
}
}
// 尝试从其他处理器上取出一部分 Goroutine,如果没有可执行的任务就会阻塞直到条件满足;
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}
execute(gp, inheritTime)
}
findrunnable 函数会再次从本地运行队列、全局运行队列、网络轮询器和其他的处理器中偷取/获取待执行的任务,该方法一定会返回待执行的 Goroutine,否则就会一直阻塞。
获取可以执行的任务之后就会调用 execute 函数执行该 Goroutine,执行的过程中会先将其状态修改成 _Grunning、与线程 M 建立起双向的关系并调用 gogo 触发调度。
func execute(gp *g, inheritTime bool) {
_g_ := getg()
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
if !inheritTime {
_g_.m.p.ptr().schedtick++
}
// 与线程 M 建立起双向的关系
_g_.m.curg = gp
gp.m = _g_.m
gogo(&gp.sched)
}
gogo 在不同处理器架构上的实现都不相同,但是不同的实现其实也大同小异,下面是该函数在 386 架构上的实现:
TEXT runtime·gogo(SB), NOSPLIT, $8-4
MOVL buf+0(FP), BX // gobuf
MOVL gobuf_g(BX), DX
MOVL 0(DX), CX // make sure g != nil
get_tls(CX)
MOVL DX, g(CX)
MOVL gobuf_sp(BX), SP // restore SP
MOVL gobuf_ret(BX), AX
MOVL gobuf_ctxt(BX), DX
MOVL $0, gobuf_sp(BX) // clear to help garbage collector
MOVL $0, gobuf_ret(BX)
MOVL $0, gobuf_ctxt(BX)
MOVL gobuf_pc(BX), BX
JMP BX
这个函数会从 gobuf 中取出 Goroutine 指针、栈指针、返回值、上下文以及程序计数器并将通过 JMP 指令跳转至 Goroutine 应该继续执行代码的位置。PS:就切换几个寄存器,所以协程的切换成本更低
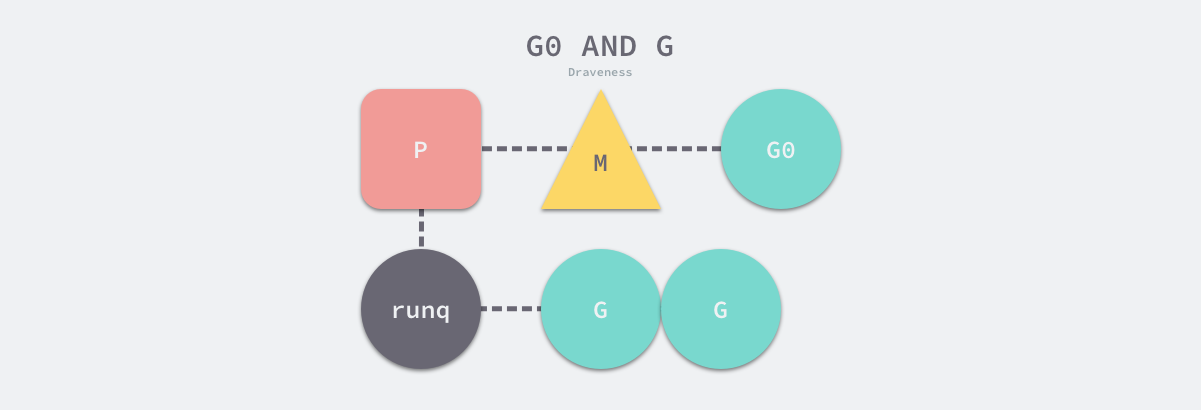
G0
聊聊 g0linux 执行调度任务:cpu 发生时间片中断,正在执行的线程 被剥离cpu,cpu 执行调度 程度寻找下一个线程并执行。 调度程度 的运行依托 栈、寄存器等上下文环境。对于go 来说,每一个线程 一直在执行一个 调度循环schedule()->execute()->gogo()->g2()->goexit()->goexit1()->mcall()->goexit0()->schedule() ,每个被调度的协程 有自己的栈 等 空间,那么先后执行的 两个协程之间 运行 schedule 这些逻辑时,也需要一些栈空间,这些都归属于g0。
Go: g0, Goroutine for SchedulingGo has to schedule and manage goroutines on each of the running threads. This role is delegated to a special goroutine, called g0, that is the first goroutine created for each OS thread. 以下图为例,在g7 被挂起后,运行g0,选择g2 来执行。
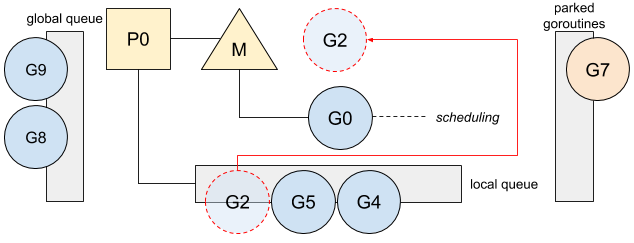
此外 g0 has a fix and larger stack. This allows Go to perform operations where a bigger stack is needed. 比如 Goroutine creation, Defer functions allocations, Garbage collector operations
补充
笔者今日学习Joe Armstrong的博士论文《面对软件错误构建可靠的分布式系统》,文中提到“在构建可容错软件系统的过程中要解决的本质问题就是故障隔离。”操作系统进程本身就是一种天然的故障隔离机制,当然从另一个层面,进程间还是因为共享cpu和内存等原因相互影响。进程要想达到容错性,就不能与其他进程有共享状态;它与其他进程的唯一联系就是由内核消息系统传递的消息。