
简介
并发控制的基本手段(没有好不好,只有合适不合适)
- 悲观锁:假定冲突的概率很高。
- 当你无法判断锁住的代码会执行多久时,互斥
- 如果你能确定被锁住的代码执行时间很短,自旋
- 如果能区分出读写操作
- 乐观锁,假定冲突的概率很低,先修改完共享资源,再验证这段时间内有没有发生冲突。如果没有其他线程在修改资源,那么操作完成。如果发现其他线程已经修改了这个资源,就放弃本次操作。至于放弃后如何重试,则与业务场景相关。无锁编程中,验证是否发生了冲突是关键。
为什么要做并发控制
线程同步出现的根本原因是访问公共资源需要多个操作,而这多个操作的执行过程不具备原子性,被任务调度器分开了,而其他线程会破坏共享资源,所以需要在临界区做线程的同步,这里我们先明确一个概念,就是临界区,临界区是指多个任务访问共享资源如内存或文件时候的指令,临界区是指令并不是受访问的资源。
- 一个资源 同一时间只能被一个进程操作,在current进程操作完成之前,其它进程不可以操作。
- 操作资源 的代码 可以认为是一个有状态服务,被调度到某个进程去执行。
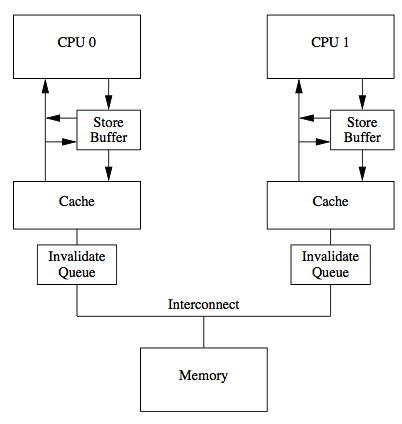
cpu 也可以是一个主机的两个进程、两台机器,想对同一个数据进行操作。
共享资源就像cpu,只能分时共享。 cpu 如何执行分时共享呢?cpu 执行完每条指令后,会检查下有没有中断,若有则执行中断处理程序。对应到进程/线程调度上,就是时间片中断。进程每次访问共享资源之前,本质上也是先去查询一个变量,若允许则执行,不允许,则让出cpu。
硬件对并发控制的支持
提供的原子操作:
- 关中断指令、内存屏障指令、停止相关流水线指令
- 对于单核cpu,禁止抢占。
- 对于SMP,提供lock 指令。lock指令是一种前缀,它可与其他指令联合,用来维持总线的锁存信号直到与其联合的指令执行完为止。比如基于AT&T的汇编指令
LOCK_PREFIX xaddw %w0,%1,xaddw 表示先交换源操作数和目的操作数,然后两个操作数求和,存入目的寄存器。为了防止这个过程被打断,加了LOCK_PREFIX的宏(修饰lock指令)。
这些指令,辅助一定的算法,就可以包装一个自旋锁、读写锁、顺序锁出来。os中,lock一词主要指自旋锁。注意,自旋锁时,线程从来没有停止运行过。
操作系统对并发控制的支持
我们常见的各种锁是有层级的,最底层的两种锁就是互斥锁和自旋锁,其他锁都是基于它们实现的。
POSIX表示可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX ),POSIX标准定义了操作系统应该为应用程序提供的接口标准。POSIX 定义了五种同步对象,互斥锁,条件变量,自旋锁,读写锁,信号量。有些时候,名词限制了我们对事物的认识。我们谈到锁、信号量这些,分析它们如何实现,或许走入了一个误区。Locks, Mutexes, and Semaphores: Types of Synchronization Objects 中认为锁是一个抽象概念,包括:
- 竞态条件。只有一个进入,还是多个进入,还是读写进入,线程能否重复获取自己已占用的锁
- 获取锁失败时的反应。提示失败、自旋还是直接阻塞,阻塞能不能被打断
按照这些不同,人们给它mutex、信号量等命名。
互斥锁和自旋锁
如何使用Redis实现分布式锁?我们通常说的线程调用加锁和释放锁的操作,到底是啥意思呢?我来解释一下。实际上,一个线程调用加锁操作,其实就是检查锁变量值是否为 0。如果是 0,就把锁的变量值设置为 1,表示获取到锁,如果不是 0,就返回错误信息,表示加锁失败,已经有别的线程获取到锁了。而一个线程调用释放锁操作,其实就是将锁变量的值置为 0,以便其它线程可以来获取锁。
当你无法判断锁住的代码会执行多久时,应该首选互斥锁,互斥锁是一种独占锁。当 A 线程取到锁后,互斥锁将被 A 线程独自占有,当 A 没有释放这把锁时,其他线程的取锁代码都会被阻塞。阻塞是如何实现的呢?对于 99% 的线程级互斥锁而言,阻塞都是由操作系统内核实现的(比如 Linux 下它通常由内核提供的信号量实现)。当获取锁失败时,内核会将线程置为休眠状态,等到锁被释放后,内核会在合适的时机唤醒线程,而这个线程成功拿到锁后才能继续执行。互斥锁通过内核帮忙切换线程,简化了业务代码使用锁的难度。但是,线程获取锁失败时,增加了两次上下文切换的成本:从运行中切换为休眠,以及锁释放时从休眠状态切换为运行中。上下文切换耗时在几十纳秒到几微秒之间,或许这段时间比锁住的代码段执行时间还长。
互斥锁能够满足各类功能性要求,特别是被锁住的代码执行时间不可控时,它通过内核执行线程切换及时释放了资源,但它的性能消耗最大。
如果你能确定被锁住的代码执行时间很短,就应该用自旋锁取代互斥锁。自旋锁比互斥锁快得多,因为它通过 CPU 提供的 CAS 函数(全称 Compare And Swap),在用户态代码中完成加锁与解锁操作。
多线程竞争锁的时候,加锁失败的线程会“忙等待”,直到它拿到锁。什么叫“忙等待”呢?它并不意味着一直执行 CAS 函数,生产级的自旋锁在“忙等待”时,会与 CPU 紧密配合 ,它通过 CPU 提供的 PAUSE 指令,减少循环等待时的耗电量;对于单核 CPU,忙等待并没有意义,此时它会主动把线程休眠。
当取不到锁时,互斥锁用“线程切换”来面对,自旋锁则用“忙等待”来面对。这是两种最基本的处理方式,更高级别的锁都会选择其中一种来实现,比如读写锁就既可以基于互斥锁实现,也可以基于自旋锁实现。
实现
通过对硬件指令的包装,os提供原子整数操作等系统调用。本质上,通过硬件指令,可以提供对一个变量的独占访问。
int atomic_read(const atomic_t *v)
// 将v设置为i
int atomic_set(atomic_t *v,int id);
通过对硬件指令的封装,操作系统可以封装一个自旋锁出来。
- 获取锁spin_lock_irq:用变量标记是否被其他线程占用,变量的独占访问,发现占用后自旋,结合关中断指令。
- 释放锁spin_unlock_irq:独占的将变量标记为未访问状态
那么在获取锁与释放锁之间,可以实现一个临界区。
spin_lock_irq();
// 临界区
spin_unlock_irq();
通过自旋锁,os可以保证count 修改的原子性。线程尝试修改count的值,根据修改后count值,决定是否挂起当前进程,进而提供semaphore和mutex(类似于semaphore=1)等抽象。也就是说,semaphore = 自旋锁 + 线程挂起/恢复。
操作系统中,semaphore与自旋锁类似的概念,只有得到信号量的进程才能执行临界区的代码;不同的是获取不到信号量时,进程不会原地打转而是进入休眠等待状态(自己更改自己的状态位)
struct semaphore{
spinlock_t lock;
unsigned int count;
struct list_head wait_list;
}
// 获取信号量,会导致睡眠
void down(struct semaphore *sem);
// 获取信号量,会导致睡眠,但睡眠可被信号打断
int down_interruptible(struct semaphore *sem);
// 无论是否获得,都立即返回,返回值不同,不会导致睡眠
int down_trylock(struct semaphore *sem);
// 释放信号量
void up(struct semaphore *sem))
内存屏障
什么是内存屏障?它是一个CPU指令
- 插入一个内存屏障,相当于告诉CPU和编译器先于这个命令的必须先执行,后于这个命令的必须后执行
- 强制更新一次不同CPU的缓存。例如,一个写屏障会把这个屏障前写入的数据刷新到缓存,这样任何试图读取该数据的线程将得到最新值
volatile,Java内存模型将在写操作后插入一个写屏障指令,在读操作前插入一个读屏障指令。
说白了,这是除cas 之外,又一个暴露在 java 层面的指令。
volatile 也是有成本的 剖析Disruptor:为什么会这么快?(二)神奇的缓存行填充
| 从CPU到 | 大约需要的 CPU 周期 | 大约需要的时间 |
|---|---|---|
| 主存 | 约60-80纳秒 | |
| QPI 总线传输(between sockets, not drawn) | 约20ns | |
| L3 cache | 约40-45 cycles | 约15ns |
| L2 cache | 约10 cycles | 约3ns |
| L1 cache | 约3-4 cycles | 约1ns |
| 寄存器 | 1 cycle |
分布式锁
如何使用Redis实现分布式锁?为了避免 Redis 实例故障而导致的锁无法工作的问题,Redis 的开发者 Antirez 提出了分布式锁算法 Redlock。基本思路是让客户端和多个独立的 Redis 实例依次请求加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,就认为客户端成功地获得分布式锁了,否则加锁失败。
linux 线程
Understanding Linux Process States
| 进程的基本状态 | 运行 | 就绪 | 阻塞 | 退出 |
|---|---|---|---|---|
| Linux | TASK_RUNNING | TASK_INTERRUPTIBLE、TASK_UNINTERRUPTIBLE | TASK_STOPPED/TASK_TRACED、TASK_DEAD/EXIT_ZOMBIE | |
| java | RUNNABLE | BLOCKED、WAITING、TIMED_WAITING | TERMINATED |
操作系统提供的手段:
| 可以保护的内容 | 临界区描述 | 执行体竞争失败的后果 | |
|---|---|---|---|
| 硬件 | 一个内存的值 | 某时间只可以执行一条指令 | 没什么后果,继续执行 |
| os-自旋 | 变量/代码 | 多用于修改变量(毕竟lock指令太贵了) | 自旋 |
| os-信号量 | 变量/代码 | 代码段不可以同时执行 | 挂起(修改状态位) |
一个复杂项目由n行代码实现,一行代码由n多系统调用实现,一个系统调用由n多指令实现。那么从线程安全的角度看:锁住系统总线,某个时间只有一条指令执行 ==> 安全的修改一个变量 ==> 提供一个临界区。通过向上封装,临界区的粒度不断地扩大。
反过来说,无锁的代码仅仅是不需要显式的Mutex来完成,但是存在数据竞争(Data Races)的情况下也会涉及到同步(Synchronization)的问题。从某种意义上来讲,所谓的无锁,仅仅只是颗粒度特别小的“锁”罢了,从代码层面上逐渐降低级别到CPU的指令级别而已,总会在某个层级上付出等待的代价,除非逻辑上彼此完全无关
一个博客系列的整理
并发的核心:
- 一个是有序性,可见性,原子性. 从底层角度, 指令重排和内存屏障,CPU的内存模型的理解.
- 另一个是线程的管理, 阻塞, 唤醒, 相关的线程队列管理(内核空间或用户空间)
并发相关的知识栈
- 硬件只是、cpu cache等
- 指令重排序、内存屏障,cpu 内存模型等
- x86_64 相关的指令:lock、cas等
- linux 进程/线程的实现,提供的快速同步/互斥机制 futex(fast userspace muTeXes)
- 并发基础原语 pthread_mutex/pthread_cond 在 glibc 的实现。这是C++ 的实现基础
- java 内存模型,java 并发基础原语 在 jvm hotspot 上的实现
- java.util.concurrent
从中可以看到
- 内存模型,有cpu 层次的,java 层次的
- 并发原语,有cpu 层次的,linux 层次的,glibc/c++ 层次的,java 层次的。 首先cpu 层次根本没有 并发的概念,限定的是cpu 核心。glibc 限定的是pthread,java 限定的是Thread
所有这一切,讲的都是共享内存模式的并发。 所以 go 的协程让程序猿 少学多少东西。