
简介
报警的哲学追踪所有收到的报警。如果收到了报警,而人们只是说 “我看了,没有什么问题”,这是一个相当强烈的信号,你需要删除报警规则,或者降级,或者以其他方式收集数据。准确率低于 50% 报警是不能使用的;即使是那些 10% 的假阳性警报,也值得多加考虑是否对齐进行修改。
容器监控与常规监控的差异
Kubernetes监控在小米的落地 为了更方便的管理容器,Kubernetes对Container进行了封装,拥有了Pod、Deployment、Namespace、Service等众多概念。与传统集群相比,Kubernetes集群监控更加复杂:
- 监控维度更多,除了传统物理集群的监控,还包括核心服务监控(apiserver,etcd等)、容器监控、Pod监控、Namespace监控等。
- 监控对象动态可变,在集群中容器的销毁创建十分频繁,无法提前预置。
- 监控指标随着容器规模爆炸式增长,如何处理及展示大量监控数据。
- 随着集群动态增长,监控系统必须具备动态扩缩的能力。
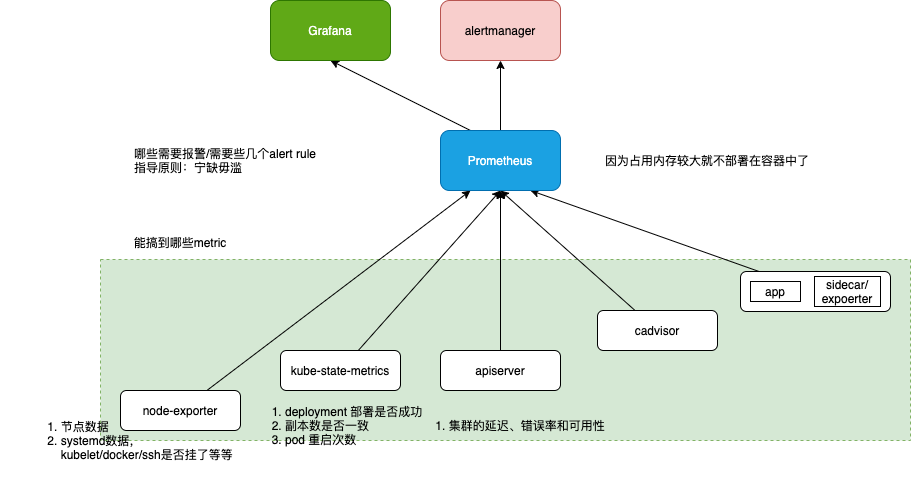
能搞到哪些metric
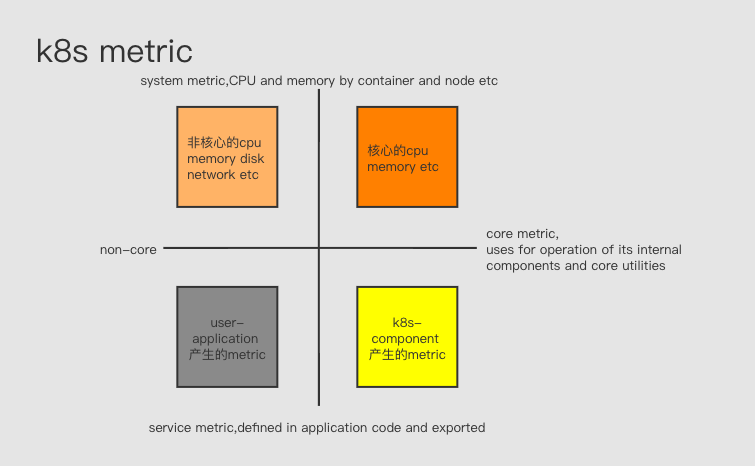
k8s 社区对k8s 监控的表述 Kubernetes monitoring architecture 将metric 分为
- core metrics, which are metrics that Kubernetes understands and uses for operation of its internal components and core utilities. metric 应用于k8s 内部组件,比如调度、扩缩容、dashboard、kubectl top. 由k8s 提供统一规范和支持(即metrics-server)。
- non-core metrics
Metrics Server/cadvisor
Metrics server复用了api-server的库来实现自己的功能,比如鉴权、版本等,为了实现将数据存放在内存中,去掉了默认的etcd存储,引入了内存存储。因为存放在内存中,因此监控数据是没有持久化的,可以通过第三方存储来拓展
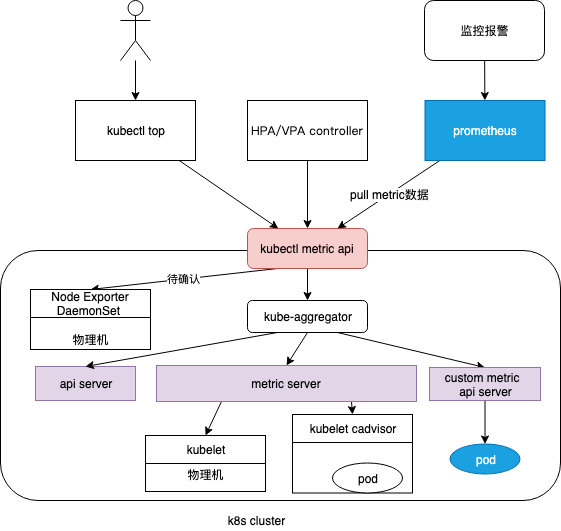
- Metrics API URI 为
/apis/metrics.k8s.io/,在k8s.io/metrics维护 - 必须部署 metrics-server 才能使用该 API,metrics-server 通过调用 Kubelet Summary API 获取数据,Summary API 返回的信息,既包括了 cAdVisor 的监控数据,也包括了 kubelet 本身汇总的信息。Pod 的监控数据是从kubelet 的 Summary API (即
<kubelet_ip>:<kubelet_port>/stats/summary)采集而来的。 - Metrics server以Deployment 形式存在,复用了api-server的库来实现自己的功能,比如鉴权、版本等,为了实现将数据存放在内存中吗,去掉了默认的etcd存储,引入了内存存储。因此监控数据是没有持久化的,可以通过第三方存储来拓展
从cadvisor 视角看
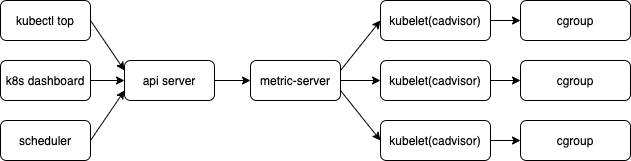
cadvisor 指标分析
cadvisor 是监控容器的,容器像物理机一样为业务提供运算资源,因此按照 USE 对容器的指标进行分析。监控的黄金指标
cadvisor 指标以container_ 为前缀,包括container_cpu_*,container_memory_*, container_fs_*, container_network_* 等,还有 container_spec_* 获取了 container 配置相关的内容。部分指标如下
cpu
- container_cpu_user_seconds_total —“用户”时间的总数(即不在内核中花费的时间)
- container_cpu_system_seconds_total —“系统”时间的总数(即在内核中花费的时间)
- container_cpu_usage_seconds_total—以上总和
- container_cpu_cfs_throttled_seconds_total 当容器超出其CPU限制时,Linux运行时将“限制”该容器并在container_cpu_cfs_throttled_seconds_total指标中记录其被限制的时间
cAdvisor中提供的内存指标是从node_exporter公开的43个内存指标的子集。以下是容器内存指标:
- container_memory_cache-页面缓存的字节数。
- container_memory_rss -RSS的大小(以字节为单位)。
- container_memory_swap-容器交换使用量(以字节为单位)。
- container_memory_usage_bytes-当前内存使用情况(以字节为单位,包括所有内存,无论何时访问。) 包括了文件系统缓存
- container_memory_max_usage_bytes- 以字节为单位记录的最大内存使用量。
- container_memory_working_set_bytes-当前工作集(以字节为单位)。
- container_memory_failcnt-内存使用次数达到限制。
- container_memory_failures_total-内存 分配失败的累积计数。
node-exporter
node-exporter提供了近1000个指标,以node_ 为前缀,包括node_cpu_*,node_memory_*, node_filesystem_*/node_disk_*, node_network_* 等。
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitoring
...
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
hostNetwork: true
hostPID: true
hostIPC: true
securityContext:
runAsUser: 0
利用Kubernetes DaemonSet控制器在集群中的每个节点上自动node-exporter pod。
- 启用systemd收 集器,并指定要监控的特定服务的正则表达式,而不是主机上的所有服务。
- 使用toleration来确保 node-exporter pod也会被调度到Kubernetes主节点,而不仅是工作节点。
- 以用户0或root运行pod(这允许访问systemd),并 且还启用了hostNetwork、hostPID和hostIPC,以指定实例的网络、进程和IPC命名空间在容器中可用。
containers:
- images: prom/node-exporter:latest
name: node-exporter
volumeMounts:
- mountPath: /run/systemd/private
name: systemd-socket
readOnly: true
args:
- "--collector.systemd"
- "--collector.systemd.unit-whitelist=(docker|ssh|rsyslog|kubelet).service"
ports:
- containerPort: 9100
hostPort: 9100
name: scrape
配置一个Prometheus scrape job,结合Kubernetes daemonset, 只需要定义一次,未来所有Kubernetes服务端点都将被自动发现 和监控。
k8s 组件 指标分析
Kubernetes 各组件的 Healthz 和 Metrics API
| Components | Healthz API | Metrics API |
|---|---|---|
| Apiserver | :6443/healthz |
:6443/metrics |
| Controller Manager | :10252/healthz |
:10252/metrics |
| Scheduler | :10251/healthz |
:10251/metrics |
| Kube-proxy | :10249/healthz |
:10249/metrics |
| Kubelet | :10248/healthz |
:10250/metrics |
| ETCD | :2379/healthz |
:2379/metrics |
kube-apiserver 是集群所有请求的入口,指标的分析可以反应集群的健康状态。Apiserver 的指标可以分为以下几大类:
- 请求速率和延迟,
apiserver_request_*/apiserver_response_* - 控制器队列的性能,
apiserver_admission_* - etcd 的性能,
etcd_* - 进程状态:文件系统、内存、CPU
- golang 程序的状态:GC、进程、线程,
go_gc_*/go_info
ETCD 指标分析
Kubernetes使用etcd来存储集群中组件的所有状态,是 Kubernetes数据库,监视etcd的性能和行为应该是整个Kubernetes监控计划的一部分。
etcd服务器指标以 etcd_* 为前缀,分为几个主要类别:
- Leader的存在和Leader变动率,
etcd_server_leader_* - 请求已提交/已应用/正在等待/失败,
etcd_server_proposals_* - 磁盘写入性能 ,
etcd_disk_* - 入站gRPC统计信息,集群内gRPC统计信息,
etcd_grpc_*
业务Pod监控
业务监控 一般由业务直接暴露metric或通过边车模式暴露metric
在Pod 或Service 中定义注解,可以让Prometheus 自动发现当前metric endpoint 并抓取数据
apiVersion: v1
kind: Service
metadata:
name: tornado-db
annotations:
prometheus.io/scrape: 'true' # 告诉Prometheus抓取这个服务
prometheus.io/port: '9104' # 告诉 Prometheus要抓取的端口,将被放入__address__标签中
kube-state-metrics
- kube-state-metrics is a simple service that listens to the Kubernetes API server and generates metrics about the state of the objects. It is not focused on the health of the individual Kubernetes components, but rather on the health of the various objects inside, such as deployments, nodes and pods. 上文关注的是 k8s组件是否健康, kube-state-metrics 关注的Kubernetes 的object 是否健康。
- kube-state-metrics uses client-go to talk with Kubernetes clusters,将Kubernetes的结构化信息转换为metrics,很多metric 都来自 Kubernetes object 的Status 或 Conditions 等字段,
kubectl describe xx一样可以看到。 - k8s custom resource 比如 verticalpodautoscalers 默认不采集, 需要额外配置
- 以Deployment 方式运行,以Service 对外服务
所有metric 以 kube_* 为前缀,每一个k8s resource 对应一批metric Exposed Metrics ,以kube_资源名_* 为前缀,以kube_deployment_*为例
kube_deployment_status_replicas
kube_deployment_status_replicas_available
kube_deployment_spec_replicas
...
以pod为例:
kube_pod_info
kube_pod_owner
kube_pod_status_phase
kube_pod_status_ready
kube_pod_status_scheduled
kube_pod_container_status_waiting
kube_pod_container_status_terminated_reason # 比如OOMKilled
Kube-state-metrics self metrics,描述自身的工作状态,比如
kube_state_metrics_list_total{resource="*v1.Node",result="success"} 1
kube_state_metrics_list_total{resource="*v1.Node",result="error"} 52
kube_state_metrics_watch_total{resource="*v1beta1.Ingress",result="success"} 1
kube-state-metrics 可以采集到的 自定义的k8s label(比如deployment等),基于此经常将kube-state-metrics metric 与其它metric 聚合后 制作报警规则。
需要哪些 alert rule
指导原则:宁缺毋滥。其实有十几个报警就不少了,再多也处理不过来。 可以参照《Prometheus 监控实战》中提到的对Prometheus 的报警规则。
制作哪些dashboard
Grafana 官方有一个 dashboard 市场,可以针对各个组件找到 全面丰富的dashboard
其它
