
简介
我一直有一个比方,如果把程序员写程序比作史官写历史,那么面向过程就是编年体通史,而面向对象更像是纪传体通史。编年体通史以时间(或一段时间)为中心,而纪传体通史则以人物为中心,譬如《史记》的《高祖本纪》等。类似的,面向过程多认为程序由一个个函数组成(依照顺序先后调用),譬如历史由一件件大事组成。而面向对象倾向于认为程序由一个个对象组成,譬如历史由一个个人的故事组成。
喷一喷面向对象
不要为了面向对象而面向对象
2019.1.2 补充如此理解面向对象编程,有一个需求:代码检查操作系统类型,若是linux 输出:linux很不错;若是windows,输出windows 很差
- 过程化的方案
- 一般面向对象方案(一个os 抽象class,一个具体os 对应一个子class)
- 面向对象进化:不仅弄子类,还弄一map 保存os 和 子类的关系
- 大神 Rob Pike 对此的评论是:根本就不需要什么Object,只需要一张小小的配置表格,里面配置了对应的操作系统和你想输出的文本。这不就完了。所谓的代码进化相当疯狂和愚蠢的,这个完全误导了对编程的认知。
还有的人喜欢用Object来替换所有的if-else语句,他们甚至还喜欢把函数的行数限制在10行以内 programming in the twenty-first century
- 那23个经典的设计模式和OO半毛钱关系没有,只不过人家用OO来实现罢了。设计模式就三个准则:1)中意于组合而不是继承,2)依赖于接口而不是实现,3)高内聚,低耦合。你看,这完全就是Unix的设计准则。
Don’t Distract New Programmers with OOPThe shift from procedural to OO brings with it a shift from thinking about problems and solutions to thinking about architecture. That’s easy to see just by comparing a procedural Python program with an object-oriented one. The latter is almost always longer, full of extra interface and indentation and annotations. The temptation(诱惑) is to start moving trivial bits of code into classes and adding all these little methods and anticipating(预料) methods that aren’t needed yet but might be someday. 封装对象、类、接口等对很多简单代码来说是不必要的。
When you’re trying to help someone learn how to go from a problem statement to working code, the last thing you want is to get them sidetracked(转移话题) by faux(人造的)-engineering busywork(作业、额外工作). Some people are going to run with those scraps(点滴) of OO knowledge and build crazy class hierarchies and end up not as focused on on what they should be learning. Other people are going to lose interest because there’s a layer of extra nonsense(无意义的) that makes programming even more cumbersome(笨重的).
面向对象逼着你除了思考问题本身外,还要思考结构、设计,很多人无此意识或功力不足, 滥用面向对象的特性,整出大量无意义的代码,使得代码复杂度大大超过了问题本身的复杂度。
走偏的controller-service-dao
controller-service-dao说白了,跟面向对象没啥关系,说面向过程也不算错。web 开发其实是在进行数据处理,这估计也是现在在倡导异步处理、反应式处理的初衷,而进行逻辑处理的框架,对代码设计是非常讲究的。习惯了Controller-service-dao这种思维,在关键领域不会用类解决问题,所有的代码都是把字段取出来计算,然后再塞回去。各种不同层面的业务计算混在一起,将来有一点调整,所有的代码都得跟着变,其实就是面向过程的代码。
面向对象几个基本概念:抽象、封装、继承、多态等,现在看,最难的就是抽象,抽象是在说啥?在厘定边界,什么活该什么类干是精确的,变动被局限在一个很小的范围内(比如,我把map 改成guava cache,变动越小越优秀)。理论上,不违背基本设计的变动,修改起来应该是很容易的。没有抽象,写出来的都是方法和方法的组合
一个类,有几个方法,有几个字段,叫啥名,哪些对外可见的,很重要,绝不是随意的,反应了你的设计理念。尤其是在重逻辑,轻数据处理的项目中。Controller-service-dao 给了很不好的恶习。
在一些从结构化编程起步的程序员的视角里,面向对象就是数据加函数。虽然这种理解不算完全错误,但理解的程度远远不够。面向对象是解决更大规模应用开发的一种尝试,它提升了程序员管理程序的尺度。谈到面向对象,你可能会想到面向对象的三个特点:封装、继承和多态。封装,则是面向对象的根基。对象之间就是靠方法调用来通信的。但这个方法调用并不是简单地把对象内部的数据通过方法暴露。因为,封装的重点在于对象提供了哪些行为,而不是有哪些数据。也就是说,即便我们把对象理解成数据加函数,数据和函数也不是对等的地位。函数是接口,而数据是内部的实现,正如我们一直说的那样,接口是稳定的,实现是易变的。“封装”的要点是行为,数据只是实现细节,而很多人习惯性的写法是面向数据的,这也是导致很多人在设计上缺乏扩展性思考的一个重要原因。
理解了这一点,我们来看一个很多人都有的日常编程习惯。他们编写一个类的方法是,把这个类有哪些字段写出来,然后,生成一大堆 getter 和 setter,将这些字段的访问暴露出去。这种做法的错误就在于把数据当成了设计的核心,这一堆的 getter 和 setter,就等于把实现细节暴露了出去。请注意,方法的命名,体现的是你的意图,而不是具体怎么做。所以,getXXX 和 setXXX 绝对不是一个好的命名。不过,在真实的项目中,有时确实需要暴露一些数据,所以,等到你确实需要暴露的时候,再去写 getter 也不迟,你一定要问问自己为什么要加 getter。至于 setter,首先,大概率是你用错了名字,应该用一个表示意图的名字;其次,setter 通常意味着修改,这是我们不鼓励的。
继承 vs 组合
对于继承,子类通过super 可以访问父类的相关方法。对于java8 interface,也是类似。从这个角度看,如果将 this、super 理解为 类成员,继承父类、实现接口,像是组合的一种特殊形态。在c++里面,子类拥有父类的数据拷贝。那么java的内存对象模型和c的内存对象模型,研究一下,做个对比,还是蛮有意思的。以下图为例,UML 在展示PriorityKafkaProducer的继承和聚合关系时,将父类AbstractPriorityKafkaProducer和聚合类/成员KafkaProducer做了平级的处理。

分解是设计的第一步,而且分解的粒度越小越好。当你可以分解出来多个关注点,每一个关注点就应该是一个独立的模块。最终的类是由这些一个一个的小模块组合而成,这种编程的方式就是面向组合编程。它相当于换了一个视角:类是由多个小模块组合而成。
如果用 Ruby,组合的表现形式就会是一个 module;而在 Scala 里,就会成为一个 trait。使用 C++ 的话,表现形式则会是私有继承。学习多种程序设计语言的重要性:Java 只有类这种组织方式,所以,很多有差异的概念只能用类这一个概念表示出来,思维就会受到限制,而不同的语言则提供了不同的表现形式,让概念更加清晰。
许式伟:继承是个过度设计,其实继承实现了代码复用和多态两个东西,揉在一起。在 Go 里面,组合实现代码复用,接口实现多态,彼此完全独立,非常清晰。
面向对象和基于对象——多态
大部分人写出的java 代码,可能只是基于对象。
基于对象,通常指的是对数据的封装,以及提供一组方法对封装过的数据操作。比如 C 的 IO 库中的 FILE * 就可以看成是基于对象的。
面向对象的程序设计语言必须有描述对象及其相互之间关系的语言成分。这些程序设计语言可以归纳为以下几类:
- 系统中一切事物皆为对象;
- 对象是属性及其操作的封装体;
- 对象可按其性质划分为类,
- 对象成为类的实例;
- 实例关系和继承关系是对象之间的静态关系;
- 消息传递是对象之间动态联系的唯一形式,也是计算的唯一形式;
- 方法是消息的序列。
《软件设计之美》只使用封装和继承的编程方式,我们称之为基于对象(Object Based)编程,而只有把多态加进来,才能称之为面向对象(Object Oriented)编程。也就是说,多态是一个分水岭,将基于对象与面向对象区分开来。软件设计是一门关注长期变化的学问,只有当你开始理解了多态,你才真正踏入应对长期变化的大门。
既然多态这么好,为什么很多程序员不能在自己的代码中很好地运用多态呢?因为多态需要构建出一个抽象。构建抽象,需要找出不同事物的共同点,而这是最有挑战的部分。而遮住程序员们双眼的,往往就是他们眼里的不同之处。在他们眼中,鸡就是鸡,鸭就是鸭。寻找共同点这件事,地基还是在分离关注点上。只有你能看出来,鸡和鸭都有羽毛,都养在家里,你才有机会识别出一个叫做“家禽”的概念。在构建抽象上,接口扮演着重要的角色。首先,接口将变的部分和不变的部分隔离开来。不变的部分就是接口的约定,而变的部分就是子类各自的实现。在软件开发中,对系统影响最大的就是变化。有时候需求一来,你的代码就要跟着改,一个可能的原因就是各种代码混在了一起。比如,一个通信协议的调整需要你改业务逻辑,这明显就是不合理的。对程序员来说,识别出变与不变,是一种很重要的能力。
很多程序员在接口中添加方法显得很随意,因为在他们心目中,并不存在实现者和使用者之间的角色差异。这也就造成了边界意识的欠缺,没有一个清晰的边界,其结果就是模块定义的随意,彼此之间互相影响也就在所难免。要想理解多态,首先要理解接口的价值,而理解接口,最关键的就是在于谨慎地选择接口中的方法。相对于封装和继承而言,多态对程序员的要求更高,需要你有长远的眼光,看到未来的变化,而理解好多态,也是程序员进阶的必经之路。
只要能够遵循相同的接口,就可以表现出来多态,所以,多态并不一定要依赖于继承。比如,在动态语言中,有一个常见的说法,叫 Duck Typing,就是说,如果走起来像鸭子,叫起来像鸭子,那它就是鸭子。“多态依赖于继承”只是某些程序设计语言自身的特点。你也看出来了,在面向对象本身的体系之中,封装和多态才是重中之重,而继承则处于一个很尴尬的位置。
以 Linux 文件系统接口为例
struct file_operations {
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
...
}
假设你写一个 HelloFS,那你可以这样给它赋值:
const struct file_operations hellofs_file_operations = {
.read = hellofs_read,
.write = hellofs_write,
};
只要给这个结构体赋上不同的值,就可以实现不同的文件系统。但是,这种做法有一个非常不安全的地方。既然是一个结构体的字段,那就有可能改写了它,像下面这样:
void silly_operation(struct file_operations* operations) {
operations.read = sillyfs_read;
}
如此一来,本来应该在 hellofs_read 运行的代码,就跑到了 sillyfs_read 里,程序很容易就崩溃了。对于 C 这种非常灵活的语言来说,你根本禁止不了这种操作,只能靠人为的规定和代码检查。到了面向对象程序设计语言这里,这种做法由一种编程结构变成了一种语法。给函数指针赋值的操作下沉到了运行时去实现。
面向对象的渊源——限定修改影响的范围
面向对象的编程产生的历史原因:由于面向过程编程在构造系统时,无法解决重用,维护,扩展的问题,而且逻辑过于复杂,代码晦涩难懂。PS:笔者第一次看到这句话时没有感觉,后来忘记了,看《左耳听风》时自己总结了这句,再看到这句早就看到的话时,知己二字不能形容。
《面向对象分析与设计》读书笔记 (1)- 关键的思想 要点如下
-
复杂性是面向对象主要解决的问题,复杂系统的5个属性
-
层次结构,复杂性常常以层次结构的形式存在,层次结构的形式
- 组成(”part of“)层次结构
- 是一种“(“is a”)层次结构
- 相对本原,这里是指构建系统的最小单位。你不需要担心基础组件是如何实现的,只要利用其外部行为即可。举个例子,你要盖一个房子,你需要砖,水泥等,这些都是一些基础组件,但是你不要自己去生产砖,水泥。
- 分离关注,组件内的联系通常比组件间的联系更强。这一事实实际上将组件中高频率的动作(涉及组件的内部结构)和低频率的动作(涉及组件间的相互作用)区分开来
- 共同模式,复杂系统具有共同的模式。比如小组件的复用,比如常用方案提炼为设计模式等
- 稳定的中间形式(注意不是中间件),复杂系统是在演变中诞生的,不要一开始就期望能够构建出一个复杂的系统。要从简单系统逐步迭代到复杂的系统。
-
-
思考分解的方式
- 系统中每个模块代表了某个总体过程的一个主要步骤。邮寄快递时,我们先将物品准备好,找到快递员,填写快递信息,进行邮寄。在这个过程中,我们分成了4个步骤,我们更注重的是事件的顺序,而非主要关注参与者。
- 根据问题域中的关键抽象概念对系统进行分解。针对上面的快递邮寄的例子,采用面向对象分解时,我们分解成4个对象:物品,快递单,快递员,我。我拥有物品,然后向快递员发出请求,快递员给我快递单让我填写快递信息。然后快递员进行邮递。
-
编程风格,Bobrow将编程风格定义为“一种组织程序的方式,基于某种编程概念模型和一种适合的语言,其目的是使得用这种风格编写的程序很清晰”
-
对象模型的4个主要要素:抽象;封装;模块化;层次结构;3个次要要素:类型、持久、并发
- Shaw对于抽象的定义:”对一个系统的一种简单的描述或指称,强调系统的某些细节或属性同时抑制另一些细节或属性。好的抽象强调了对读者或者用户重要的细节,抑制了那些至少是暂时的非本质细节或枝节” (我以前的思维漏洞 就是不知道 抑制非本质细节)
- 封装的意义,复杂系统的每一部分,都不应该依赖于其他部分的内部细节。要让抽象能工作,必须将实现封装起来
- 模块化的意义
- 层次结构的意义
其它
左耳听风
来自陈皓《左耳听风》付费课程,建议先看下java 语言的动态性
在面向对象编程里,计算机程序会被设计成彼此相关的对象,独立而又相互调用。传统程序主张将程序看做一系列指令,或一系列函数。面向对象设计中的每一个对象 都应该能够接受数据、处理数据并将数据传递给其它对象。
面向对象的缺点:通过对象来达到抽象效果, 把代码分散在不同的类里面。那要让它们执行起来,就需要将这些类粘合起来。设计模式以及ioc 等虽然精巧,但不得不怀疑点歪了科技树。一段代码的执行路径 obj1.func1 ==> obj2.func2 ==> obj3.func3 在函数式编程中 func1(func2(func3)) 就解决了。
换个角度想一下,架构设计从单体演化到微服务架构,固然一部分是单机无法负载,另一个原因就是单体 在维护和运维上的困难,比如一个小改动导致整个项目的重启。也就是说,架构设计之初,就越来越考虑可维护性和扩展性。架构设计不只考虑实现功能,可维护性和扩展性影响了架构设计,对应的,可维护性和扩展性影响了代码结构。指令序列或函数序列被解构,分散在各个对象中,以减少修改对整体的影响。但从上图可以看到,面向对象的优点 也直接导致了其缺点。
宏观上的系统设计与类设计
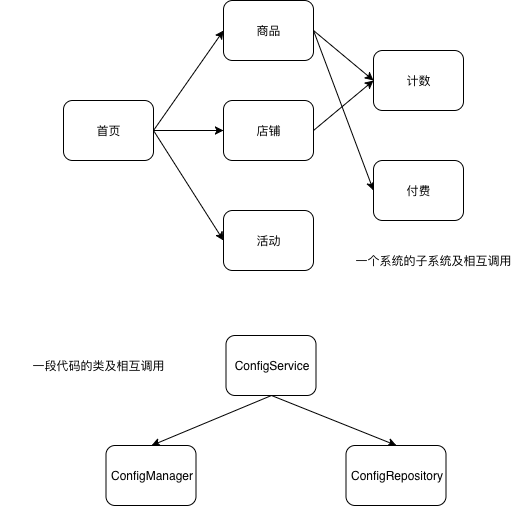
可以认为,db 就是controller-service-dao 这些类的状态。
微观上的类实现与系统模块实现
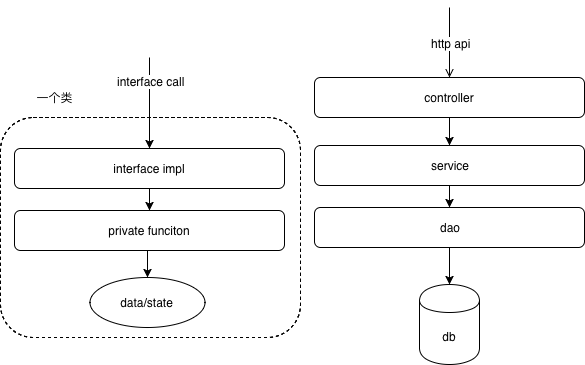
你设计一个controller-service-dao 项目 制定http api 时,肯定会想业务层面会有哪些调用,绝不会一个http api 干了一半的活儿 然后让调用方自己 访问两个 http api 自己聚合数据。对应的,我们在设计类时,根据类持有的数据/状态,一个对象可以访问数据库、可以内部操作线程,但其对外提供的interface function 应该是自洽的(对外隐藏掉不必要的细节)。类似的概念可以看 ddd(一)——领域驱动理念入门
多线程与对象的 关系
我以前的认知,线程只是一个 驱动者,驱动代码执行,对象跟线程没啥关系。一个典型的代码是
class XXThread extends Thread{
private Business business;
public XXThread(Business business){
this.business = business;
}
public void run(){
business code
}
}
在apollo client 中,RemoteRepository 内部聚合线程 完成配置的周期性拉取,线程就是一个更新数据的手段,只是周期性执行下而已。
class Business{
private Data data;
public Business(){
Executors.newSingleThread().execute(new Runnable(){
public void run(){
acquireDataTimely();
}
});
}
public void acquireDataTimely(){}
public void useData(){}
public void transferData(){}
}
从两段代码 看,线程与对象的 主从关系 完全相反。程序的本质复杂性和元语言抽象指出:程序=control + logic。 同步/异步 等 本质就是一个control,只是拉取数据的手段。因此,在我们理解程序时,同步异步不应成为本质的存在。
小结
本文着重从面向对象渊源的角度来说明:面向过程编程在构造系统时,无法解决重用,维护,扩展的问题,进而说明面向对象将 重用、维护、扩展加入了设计理念中,进而体现在语言的方方面面。