
前言
类加载——按类名加载
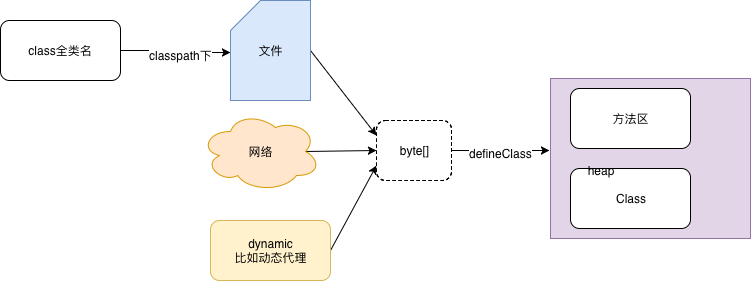
加载的本质,从磁盘上加载,得到的是一个字节数组,然后按照自己的内存模型,把字节数组中对应的数据放到进程内存对应的地方。并对数据进行校验,转化解析和初始化,最终形成可以被虚拟机直接使用的java类型,这就是虚拟机的类加载机制。
JVM类加载器与ClassNotFoundException和NoClassDefFoundError在”加载“阶段,虚拟机需要完成以下三件事:
- 通过一个类的全限定名来获取此类的二进制字节流。类似的 maven的基本概念 中提到
URL construction scheme概念,根据一个jar 的groupId + artifactId + version 即可构造一个http url ,从maven remote Repository 下载jar 文件。 - 将字节流代表的静态存储结构转换为方法区的运行时数据结构
- 在内存中创建一个代表此类的java.lang.Class对象,作为方法区此类的各种数据的访问入口。
类加载器的双亲委派模型
ClassLoader源码注释:The ClassLoader class uses a delegation model to search for classes and resources.

双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都必须有自己的父类加载器,类加载器间的父子关系不会以继承关系实现,而是以组合的方式来复用父类加载的代码。
双亲委派模型的工作过程:当一个类加载器收到类加载请求的时候,它会首先把这个请求委托给父类加载器去执行,因此所有的类加载请求最终都会传送到顶层的启动类加载器中,只有当父类加载器也无法找到时才会交给自己去加载。
双亲委派模型的关键就是定义了类的加载过程,先尝试用父类加载器加载,再使用自定义加载器加载,以确保关键的类不被篡改。
使用场景:
- 热部署
- 代码加密
- 类层次划分
延迟加载
class X{
static{ System.out.println("init class X..."); }
int foo(){ return 1; }
Y bar(){ return new Y(); }
}
The most basic API is ClassLoader.loadClass(String name, boolean resolve)
Class classX = classLoader.loadClass("X", resolve);
If resolve is true, it will also try to load all classes referenced by X. In this case, Y will also be loaded. If resolve is false, Y will not be loaded at this point.
ClassNotFoundException和NoClassDefFoundError
Why am I getting a NoClassDefFoundError in Java?
- ClassNotFoundException This exception indicates that the class was not found on the classpath.
- NoClassDefFoundError, This is caused when there is a class file that your code depends on and it is present at compile time but not found at runtime. Look for differences in your build time and runtime classpaths. 引起的原因比较少见,还未掌握到精髓。
ClassLoader 隔离
笔者曾写过一个框架,用户在代码中通过注解使用。注解参数包括类的全类名(用户自定义的策略类),框架通过注解拿到用户的全类名,加载类,然后调用执行。
但当框架给scala小组使用时,scala小组因使用的play框架的classloader是spring classload的子类。用户自定义策略类是scala实现的,写在用户的项目中。
框架实现主流程,其中的某个环节,load 用户自定义的策略类执行。此时,框架代码Class.forName(class name)去load scala class name就力不从心了。为何呀?
- 当在class A中使用了class B时,JVM默认会用class A的class loader去加载class B。
- 每个class loader 有一个自己的search class 文件的classpath 范围。
- class的 加载不是一次性加载完毕的,而是根据需要延迟加载的(上文提到过)。
- 如果class B 不在class loader的classpath search 范围,则会报ClassNotFoundException
与Spring ioc 隔离的对比 Spring IOC 级联容器原理探究。PS:有意思的是,classloader 和 spring ioc 都称之为容器,都具有隔离功能,这背后是否有一个统一的逻辑在?都是class loader,只是class 来源不同,加载后的组织方式不同
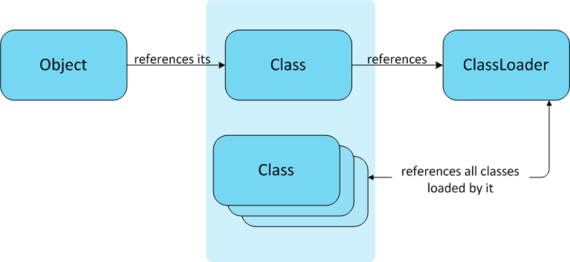
在 Java 虚拟机中,类的唯一性是由类加载器实例以及类的全名一同确定的(即便是同一串字节流,经由不同的类加载器加载,也会得到两个不同的类。猜测一下,如果是一致的,ClassLoader 该如何实现呢?
- ClassLoader
Class<?> defineClass(String name, byte[] b, int off, int len)时,如果发现name 相同, 可以直接返回。但ClassLoader 是可以自定义实现的,很难约束开发必须遵守这个规则。 - defineClass 时直接覆盖,那问题就更严重了,开发就有机会恶意覆盖 一些已有的java 库中的类的实现。
在大型应用中,往往借助这一特性,来运行同一个类的不同版本。tomcat 在类加载方面就有很好的实践 Tomcat源码分析
Java对象在内存中的表示
| 新建对象的方式 | |
|---|---|
| new | 通过构造器来初始化实例字段 |
| 反射 | 通过构造器来初始化实例字段 |
| Object.clone | 直接复制已有的数据,来初始化新建对象的实例字段 |
| 反序列化 | 直接复制已有的数据,来初始化新建对象的实例字段 |
| Unsafe.allocateInstance | 未初始化实例字段 |
java 对象的C++ 类表示——oop-klass model
深入理解多线程(二)—— Java的对象模型HotSpot是基于c++实现,而c++是一门面向对象的语言,本身具备面向对象基本特征,所以Java中的对象表示,最简单的做法是为每个Java类生成一个c++类与之对应。但HotSpot JVM并没有这么做,而是设计了一个OOP-Klass Model。OOP(Ordinary Object Pointer)指的是普通对象指针,而Klass用来描述对象实例的具体类型。为什么HotSpot要设计一套oop-klass model呢?答案是:HotSopt JVM的设计者不想让每个对象中都含有一个vtable(虚函数表)。oop的职能主要在于表示对象的实例数据,所以其中不含有任何虚函数。而klass为了实现虚函数多态,所以提供了虚函数表。
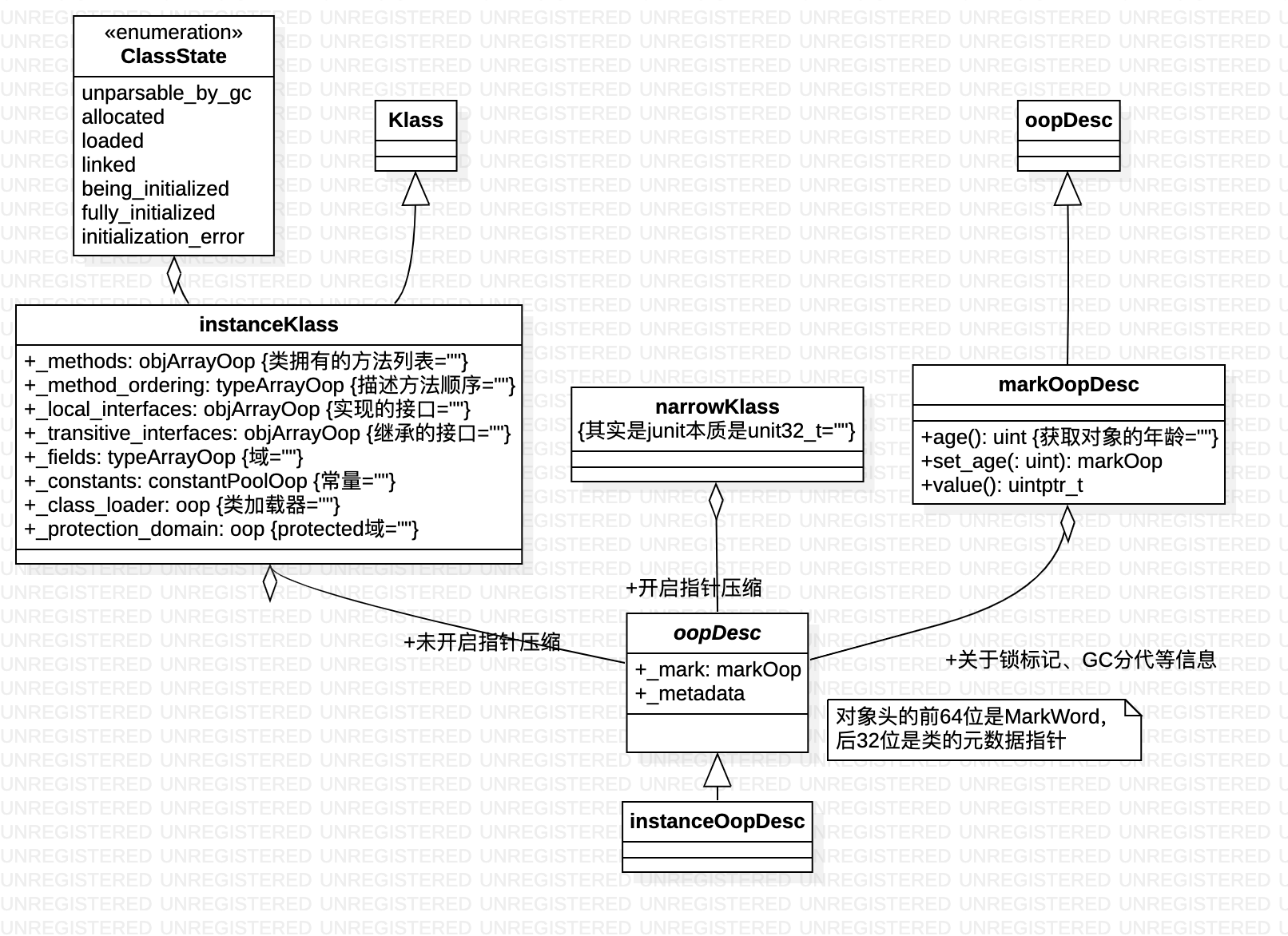
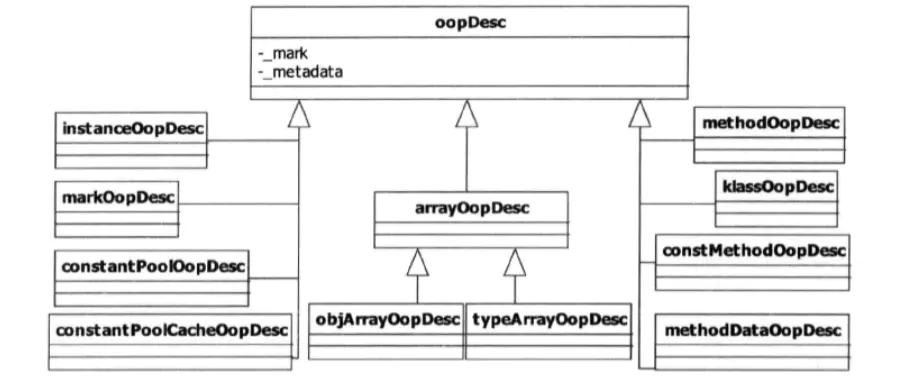
在Java程序运行过程中,每创建一个新的对象,在JVM内部就会相应地创建一个对应类型的OOP对象。在HotSpot中,根据JVM内部使用的对象业务类型,具有多种oopDesc的子类。除了oppDesc类型外,opp体系中还有很多instanceOopDesc、arrayOopDesc 等类型的实例,他们都是oopDesc的子类。
JVM在运行时,需要一种用来标识Java内部类型的机制。在HotSpot中的解决方案是:为每一个已加载的Java类创建一个instanceKlass对象,用来在JVM层表示Java类。
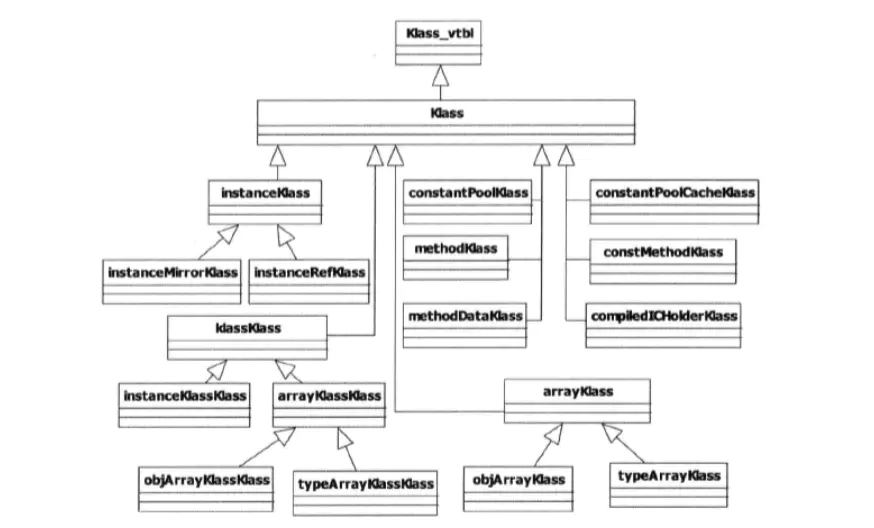
一个Java对象,它的存储是怎样的?
- 一般很多人会回答:对象存储在堆上。
- 稍微好一点的人会回答:对象存储在堆上,对象的引用存储在栈上。
- 一个更加显得牛逼的回答:对象的实例(instantOopDesc)保存在堆上,对象的元数据(instantKlass)保存在方法区,对象的引用保存在栈上。
内存布局
class oopDesc {
private:
volatile markWord _mark;
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
}
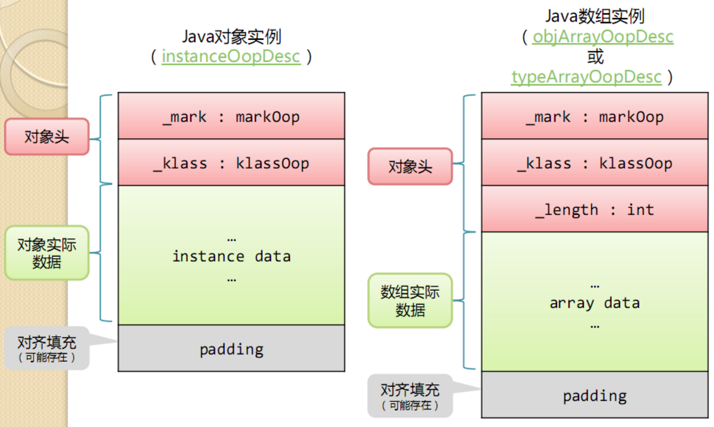
每个 Java 对象都有一个对象头 (object header) ,由标记字段和类型指针构成。java对象头信息是跟对象自身定义的数据结构无关的,这些信息所记录的状态是用于JVM对对象的管理的(比如并发访问与gc)。
- 标记字段用来存储对象的哈希码, GC 信息, 持有的锁信息。
- 类型指针指向该对象的类 Class。
在 64 位操作系统中,标记字段占有 64 位,而类型指针也占 64 位,也就是说一个 Java 对象在什么属性都没有的情况下要占有 16 字节的空间,当前 JVM 中默认开启了压缩指针,这样类型指针可以只占 32 位,所以对象头占 12 字节, 压缩指针可以作用于对象头,以及引用类型的字段。
以 Integer 类为例,它仅有一个 int 类型的私有字段,占 4 个字节。因此,每一个 Integer 对象的额外内存开销至少是 400%。这也是为什么 Java 要引入基本类型的原因之一。
默认情况下,Java 虚拟机堆中对象的起始地址需要对齐至 8的倍数。如果一个对象用不到 8N 个字节,那么剩下的就会被填充。这些浪费掉的空间我们称之为对象间的填充(padding)。
- 对象内存对齐, 这样对象的地址 就可以压缩一下,比如address * 8 得到对象的实际地址。
- 对象字段内存对齐(有六七个对齐规则),让字段只出现在同一 CPU 的缓存行中。如果字段不是对齐的,那么就有可能出现跨缓存行的字段。也就是说,该字段的读取可能需要替换两个缓存行,而该字段的存储也会同时污染两个缓存行。
- Java 虚拟机重新分配字段的先后顺序,以达到内存对齐的目的
java 对象在缓存中的读写
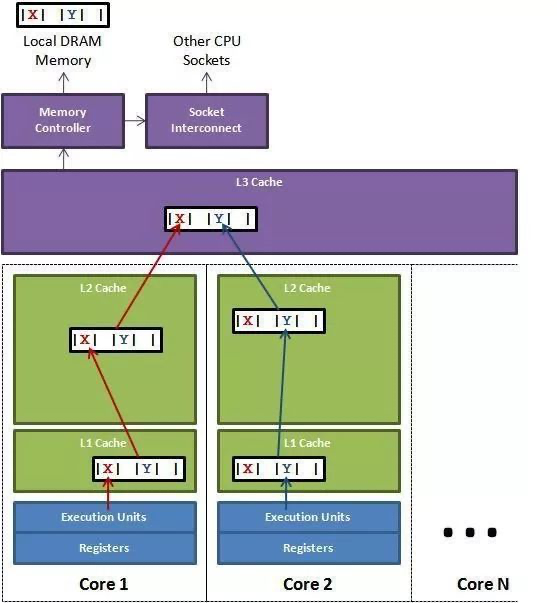
通过内存对齐可以避免一个字段同时存在两个缓存行里的情况,但还是无法完全规避缓存伪共享的问题,也就是一个缓存行中存了多个变量,而这几个变量在多核 CPU 并行的时候,会导致竞争缓存行的写权限,当其中一个 CPU 写入数据后,这个字段对应的缓存行将失效,导致这个缓存行的其他字段也失效。
在 Disruptor 中,通过填充几个无意义的字段,让对象的大小刚好在 64 字节,一个缓存行的大小为64字节,这样这个缓存行就只会给这一个变量使用,从而避免缓存行伪共享,但是在 jdk7 中,由于无效字段被清除导致该方法失效,只能通过继承父类字段来避免填充字段被优化,而 jdk8 提供了注解@Contended 来标示这个变量或对象将独享一个缓存行,使用这个注解必须在 JVM 启动的时候加上 -XX:-RestrictContended 参数,其实也是用空间换取时间。