
简介
刘超《趣谈linux操作系统》
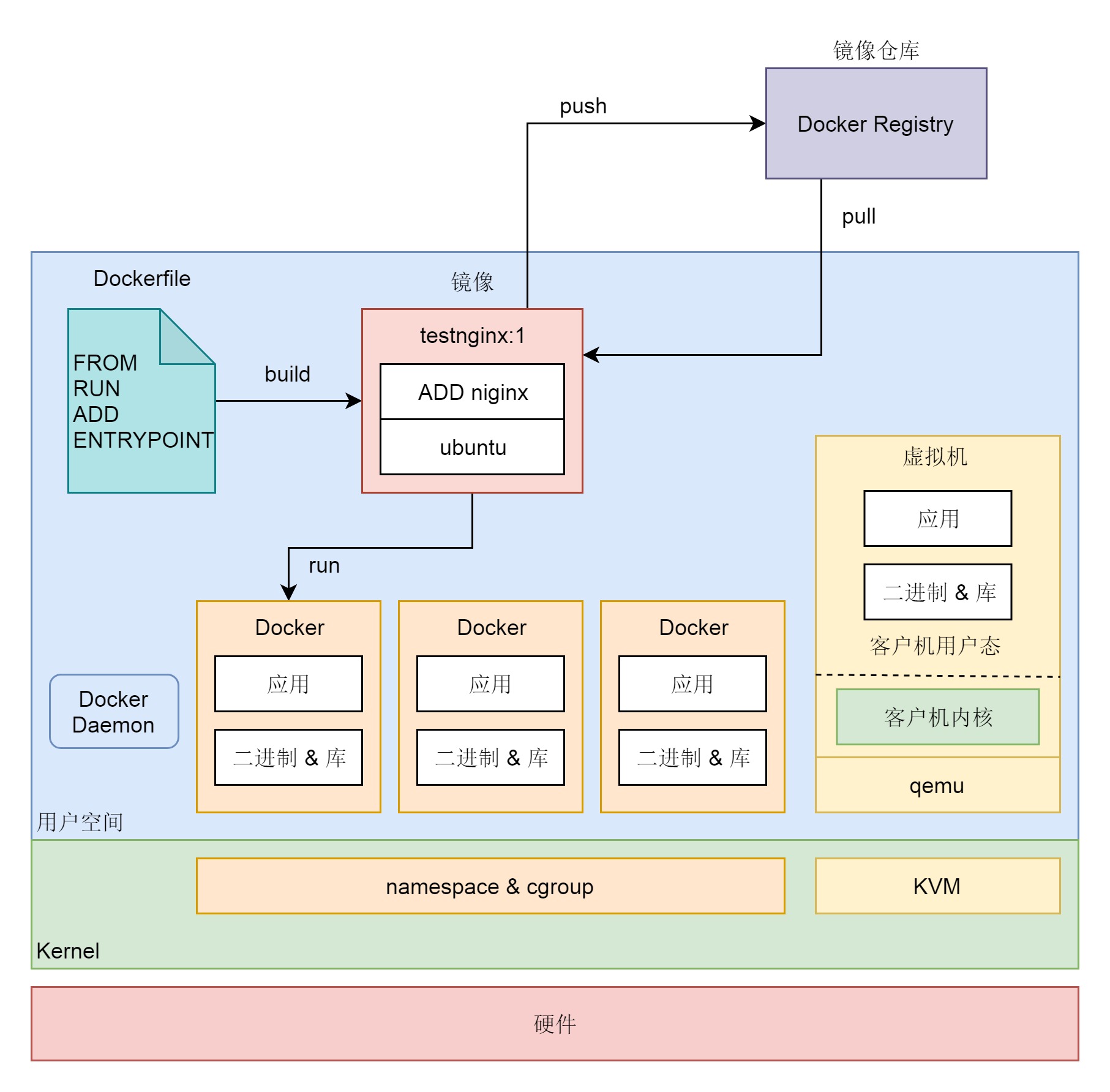
从一台物理机虚拟化出很多的虚拟机这种方式,一定程度上实现了资源创建的灵活性。但虚拟化的方式还是非常复杂的,CPU、内存、网络、硬盘全部需要虚拟化,一个都不能偷懒。有没有一种更加灵活的方式,专门用于某个进程,又不需要费劲周折的虚拟化这么多的硬件呢?毕竟最终我只想跑一个程序,而不是要一整个 Linux 系统。就像在一家大公司搞创新,如果每一个创新项目都要成立一家子公司的话,那简直太麻烦了。一般方式是在公司内部成立一个独立的组织,分配独立的资源和人力,先做一段时间的内部创业。如果真的做成功了,再成立子公司也不迟。
容器的英文叫 Container,Container 的另一个意思是“集装箱”。其实容器就像船上的不同的集装箱装着不同的货物,有一定的隔离,但是隔离性又没有那么好,仅仅做简单的封装。当然封装也带来了好处,一个是打包,二是标准。有了集装箱还不行,大家的高长宽形状不一样也不方便,还要通过镜像将这些集装箱标准化,使其在哪艘船上都能运输,在哪个码头都能装卸(在哪个物理机上都能跑),就好像集装箱在开发、测试、生产这三个码头非常顺利地整体迁移,这样产品的发布和上线速度就加快了。
除了可以如此简单地创建一个操作系统环境,容器还有一个很酷的功能,就是镜像里面带应用。这样的话,应用就可以像集装箱一样,到处迁移,启动即可提供服务。而不用像虚拟机那样,要先有一个操作系统的环境,然后再在里面安装应用。
两个基本点
- 数据结构:namespace 和 cgroups 数据在内核中如何组织
- 算法:内核如何应用namespace 和 cgroups 数据
namespace
《深入剖析kubernetes》:用户运行在容器里的应用进程,跟宿主机上的其他进程一样,都由宿主机操作系统统一管理,只不过这些被隔离的进程拥有额外设置过的Namespace 参数。而docker 在这里扮演的角色,更多的是旁路式的辅助和管理工作。
来源
命名空间最初是用来解决命名唯一性问题的,即解决不同编码人员编写的代码模块在合并时可能出现的重名问题。
传统上,在Linux以及其他衍生的UNIX变体中,许多资源是全局管理的。这意味着进程之间彼此可能相互影响。偏偏有这样一些场景,比如一场“黑客马拉松”的比赛,组织者需要运行参赛者提供的代码,为了防止一些恶意的程序,必然要提供一套隔离的环境,一些提供在线持续集成服务的网站也有类似的需求。
我们不想让进程之间相互影响,就必须将它们隔离起来,最好都不知道对方的存在。而所谓的隔离,便是隔离他们使用的资源(比如),进而资源的管理也不在是全局的了。
namespace 内核数据结构
Namespaces in operation, part 1: namespaces overview 是一个介绍 namespace 的系列文章,要点如下:
- The purpose of each namespace is to wrap a particular global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource. 对global system resource的封装
- there will probably be further extensions to existing namespaces, such as the addition of namespace isolation for the kernel log. 将会有越来越多的namespace
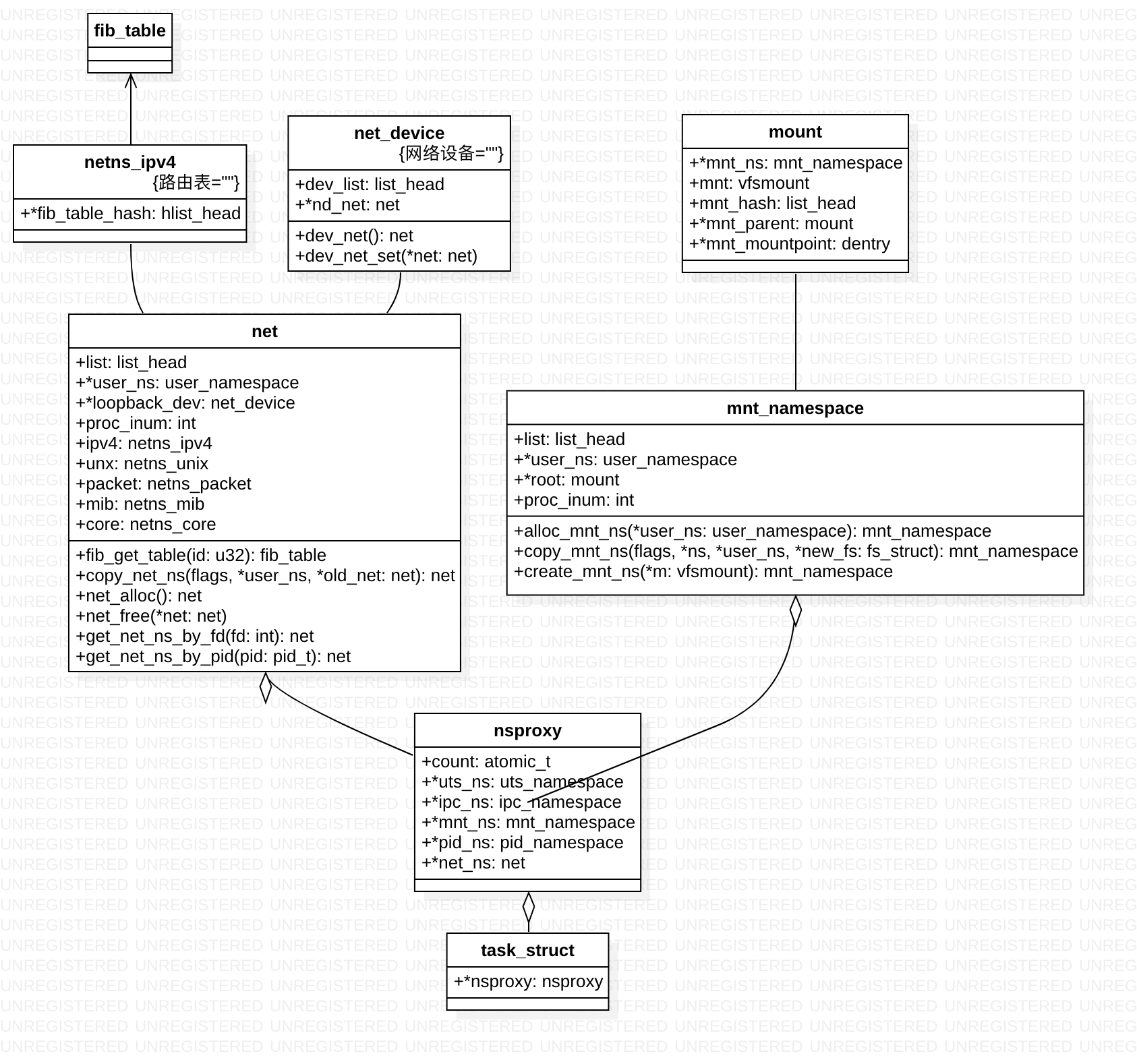
namespace 简单说,就是进程的task_struct 以前都直接 引用资源id(各种资源或者是index,或者 是一个地址),现在是进程 task struct ==> nsproxy ==> 资源表(操作系统就是提供抽象,并将各种抽象封装为数据结构,外界可以引用)
struct task_struct {
……..
/* namespaces */
struct nsproxy *nsproxy;
…….
}
struct nsproxy {
atomic_t count; // nsproxy可以共享使用,count字段是该结构的引用计数
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
};
What is the relation between task_struct and pid_namespace?
Separation Anxiety: A Tutorial for Isolating Your System with Linux Namespaces 该文章 用图的方式,解释了各个namespace 生效的机理,值得一读。其实要理解的比较通透,首先就得对 linux 进程、文件、网络这块了解的比较通透。此外,虽说都是隔离,但他们隔离的方式不一样,比如root namespace是否可见,隔离的资源多少(比如pid只隔离了pid,mnt则隔离了root directory 和 挂载点,network 则隔离网卡、路由表、端口等所有网络资源),隔离后跨namespace如何交互
namespace 生效机制
pid namespace
进程是树结构的,每个namespace 理解的 根不一样,pid root namespace 最终提供完整视图
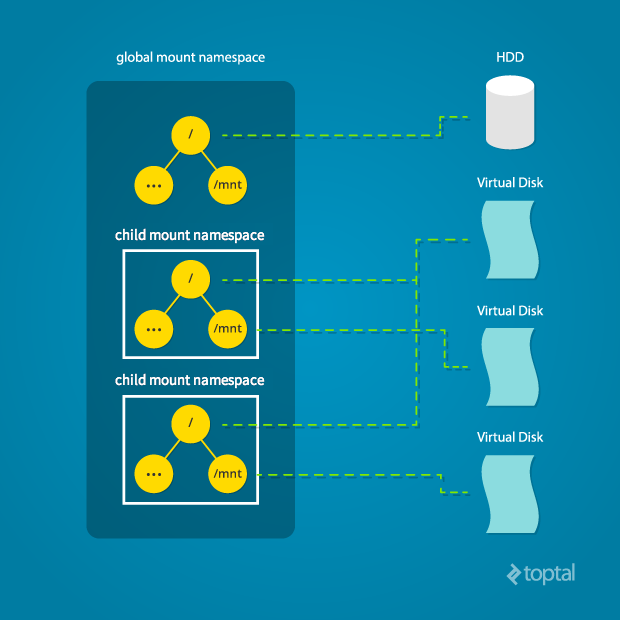
mount namespace
mount 也是有树的,每个namespace 理解的根 不一样, 挂载点目录彼此看不到. task_struct ==> nsproxy 包括 mnt_namespace。
struct mnt_namespace {
atomic_t count;
struct vfsmount * root;///当前namespace下的根文件系统
struct list_head list; ///当前namespace下的文件系统链表(vfsmount list)
wait_queue_head_t poll;
int event;
};
struct vfsmount {
...
struct dentry *mnt_mountpoint; /* dentry of mountpoint,挂载点目录 */
struct dentry *mnt_root; /* root of the mounted tree,文件系统根目录 */
...
}
只是单纯一个隔离的 mnt namespace 环境是不够的,还要”change root”,参见《自己动手写docker》P45
《阿里巴巴云原生实践15讲》chroot 的作用是“重定向进程及其子进程的根目录到一个文件系统 上的新位置”,使得该进程再也看不到也没法接触到这个位置上层的“世界”。所以这 个被隔离出来的新环境就有一个非常形象的名字,叫做 Chroot Jail。
network namespace
network namespace 倒是没有根, 但docker 创建 veth pair,root namespace 一个,child namespace 一个。此外 为 root namespace 额外加 iptables 和 路由规则,为 各个ethxx 提供路由和数据转发,并提供跨network namesapce 通信。
cgroups
对于CPU Cgroup的配置会影响一个进程的task_struct作为调度单元的scheduled_entity,并影响在CPU上的调度。对于内存 Cgroup的配置起作用在进程申请内存的时候,也即当出现缺页,调用handle_pte_fault进而调用do_anonymous_page的时候,会查看是否超过了配置,超过了就分配失败,OOM。
从操作上看:
-
可以创建一个目录(比如叫cgroup-test),
mount -t cgroup -o none cgroup-test ./cgroup-testcgroup-test 便是一个hierarchy了,一个hierarchy 默认自动创建很多文件- cgroup.clone_children - cgroup.procs - notify_on_release - tasks
你为其创建一个子文件cgroup-test/ cgroup-1,则目录变成
- cgroup.clone_children
- cgroup.procs
- notify_on_release
- tasks
- cgroup-1
- cgroup.clone_children
- cgroup.procs
- notify_on_release
- tasks
往task 中写进程号,则标记该进程 属于某个cgroup。
注意,mount时,-o none 为none。 若是 mount -t cgroup -o cpu cgroup-test ./cgroup-test 则表示为cgroup-test hierarchy 挂载 cpu 子系统
- cgroup.event_control
- notify_on_release
- cgroup.procs
- tasks
- cpu.cfs_period_us
- cpu.rt_period_us
- cpu.shares
- cpu.cfs_quota_us
- cpu.rt_runtime_us
- cpu.stat
cpu 开头的都跟cpu 子系统有关。可以一次挂载多个子系统,比如-o cpu,mem
从右向左 ==> 和docker run放在一起看
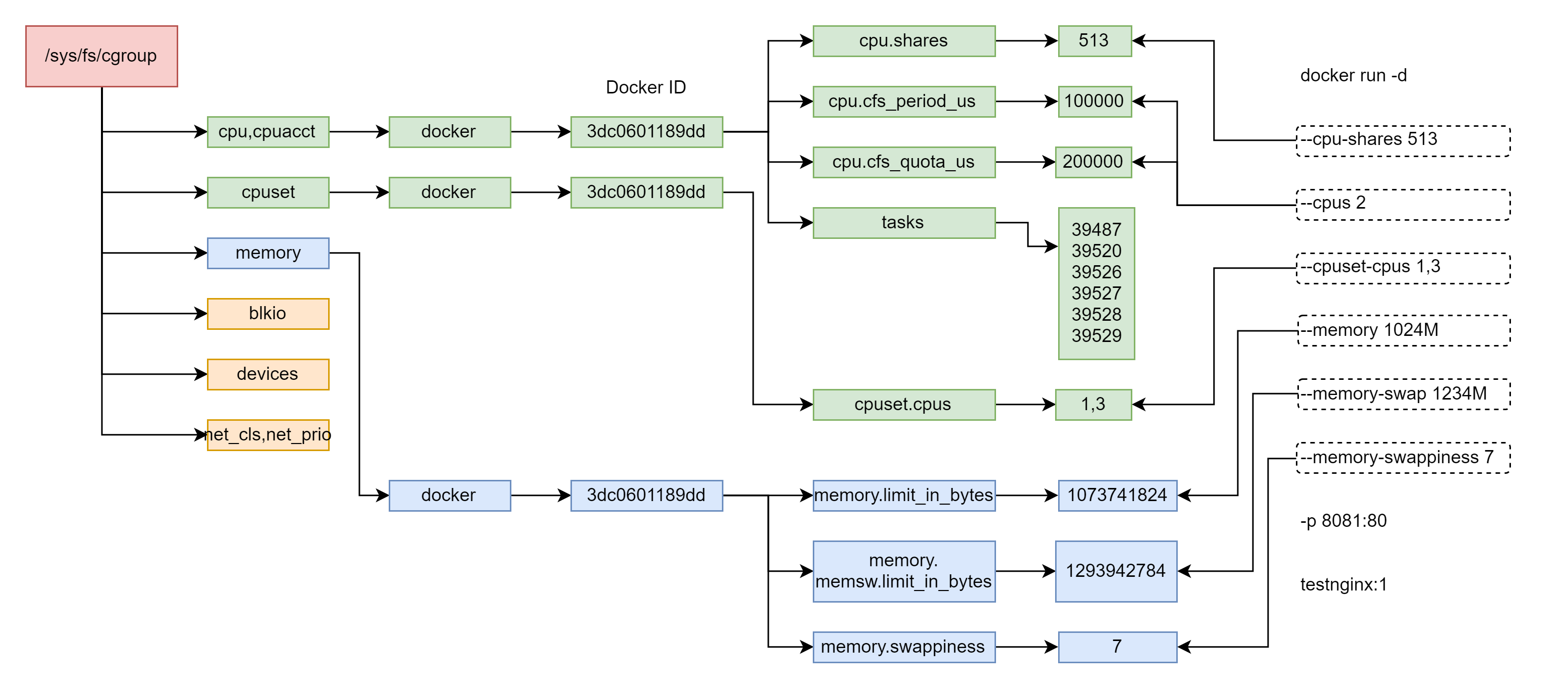
从左向右 ==> 从 task 结构开始找到 cgroup 结构
在图中使用的回环箭头,均表示可以通过该字段找到所有同类结构
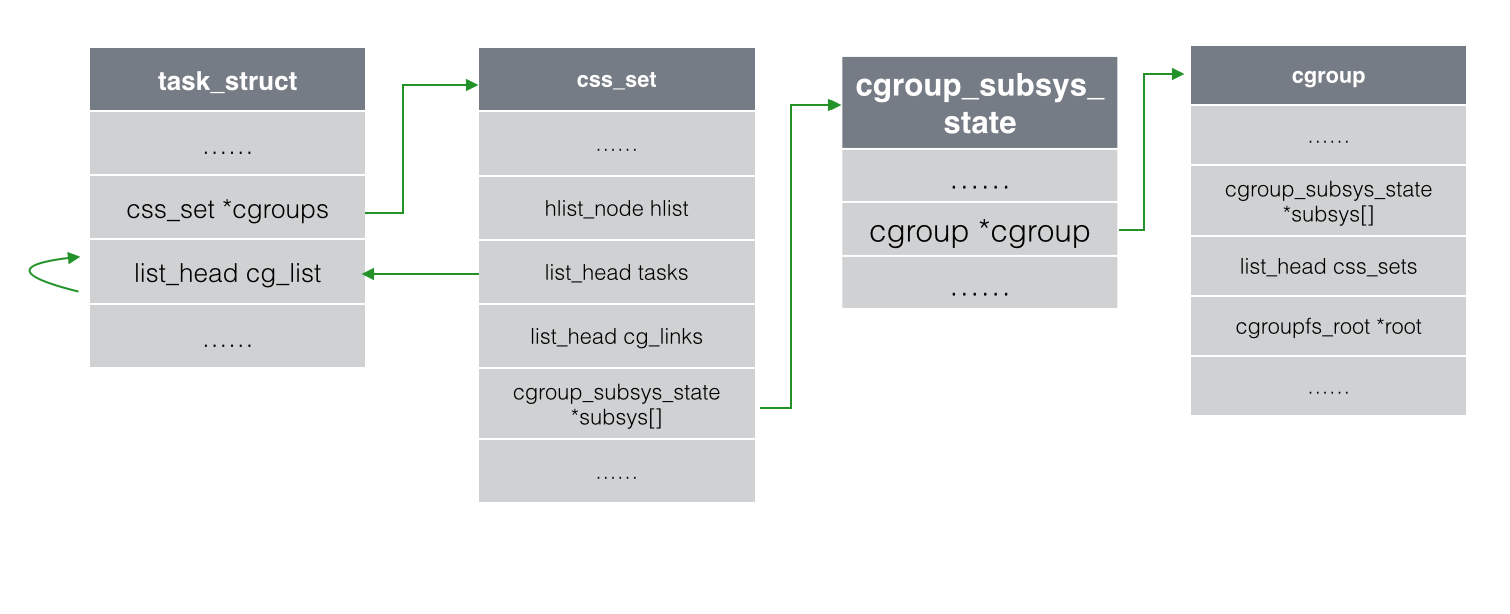
从右向左 ==> 查看一个cgroup 有哪些task
(/public/upload/linux/linux_task_cgroup.png)
为什么要使用cg_cgroup_link结构体呢?因为 task 与 cgroup 之间是多对多的关系。熟悉数据库的读者很容易理解,在数据库中,如果两张表是多对多的关系,那么如果不加入第三张关系表,就必须为一个字段的不同添加许多行记录,导致大量冗余。通过从主表和副表各拿一个主键新建一张关系表,可以提高数据查询的灵活性和效率。
使cgroups 数据生效
我们知道, 任何内存申请都是从缺页中断开始的,handle_pte_fault ==> do_anonymous_page ==> mem_cgroup_newpage_charge(不同linux版本方法名不同) ==> mem_cgroup_charge_common ==> __mem_cgroup_try_charge
static int __mem_cgroup_try_charge(struct mm_struct *mm,
gfp_t gfp_mask,
unsigned int nr_pages,
struct mem_cgroup **ptr,
bool oom){
...
struct mem_cgroup *memcg = NULL;
...
memcg = mem_cgroup_from_task(p);
...
}
mem_cgroup_from_task ==> mem_cgroup_from_css
struct mem_cgroup *mem_cgroup_from_task(struct task_struct *p){
...
return mem_cgroup_from_css(task_subsys_state(p, mem_cgroup_subsys_id));
}
整体
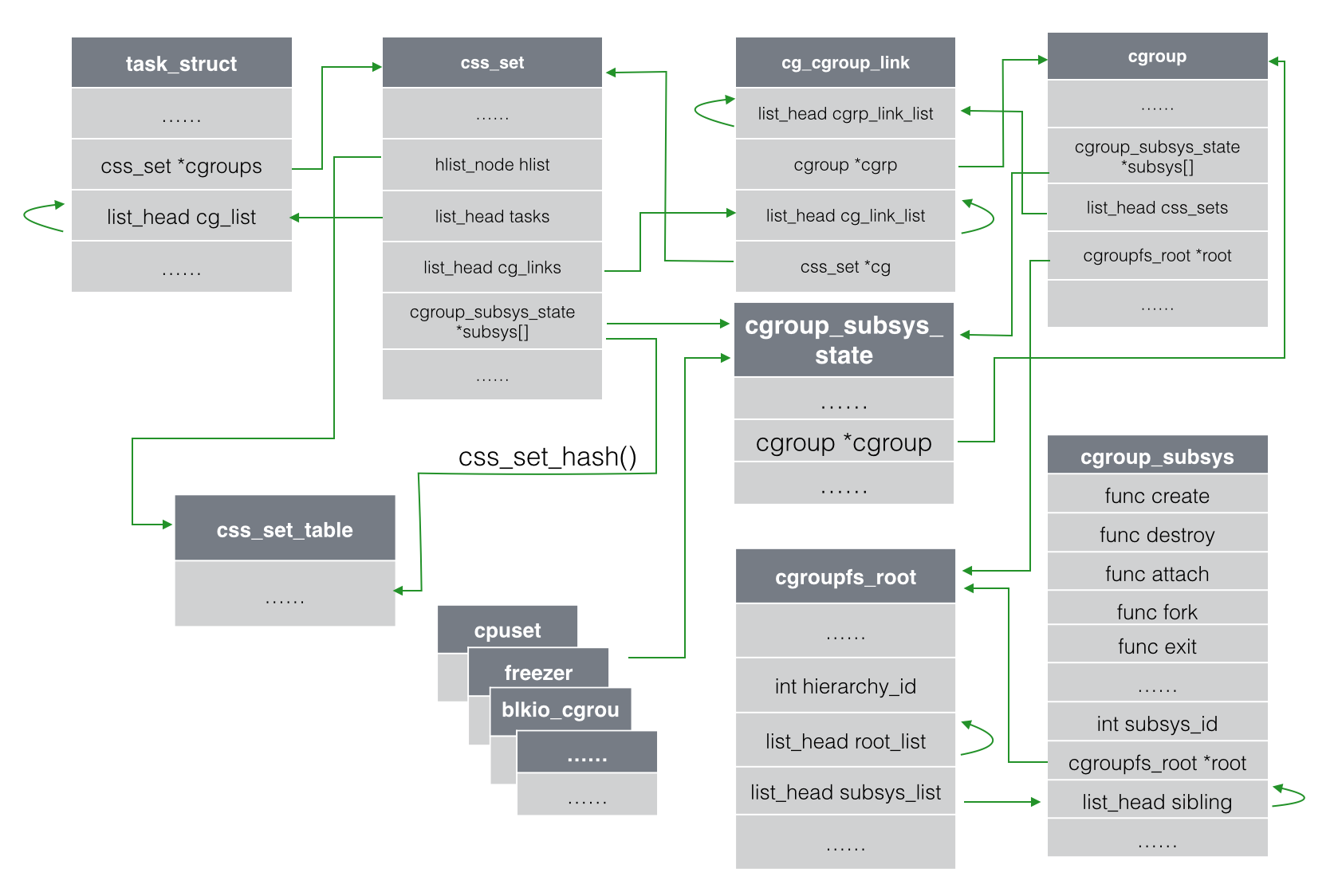
在系统运行之初,内核的主函数就会对root cgroups和css_set进行初始化,每次 task 进行 fork/exit 时,都会附加(attach)/ 分离(detach)对应的css_set。
struct cgroup {
unsigned long flags;
atomic_t count;
struct list_head sibling;
struct list_head children;
struct cgroup *parent;
struct dentry *dentry;
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
struct cgroupfs_root *root;
struct cgroup *top_cgroup;
struct list_head css_sets;
struct list_head release_list;
struct list_head pidlists;
struct mutex pidlist_mutex;
struct rcu_head rcu_head;
struct list_head event_list;
spinlock_t event_list_lock;
};
sibling,children 和 parent 三个嵌入的 list_head 负责将统一层级的 cgroup 连接成一棵 cgroup 树。
为什么是vfs操作而不是命令行?为什么符合vfs 的关系
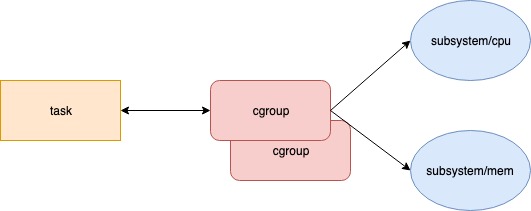
- 对task 进行资源限制,最直觉得做法就是 task 和 subsystem 直接关联
- 因为task 与subsystem 是一对多关系,且想复用 subsystem,因此提取了 cgroup 作为中间层。这样想对10个进程限定 1cpu和2g内存 就不用 创建那么多
<task,subsystem>了 - 如果每种 subsystem 的组合就是一个 cgroup ,则每次 新需求都要创建新的cgroup,可以将共性抽取出来,使得cgroup 具有父子/继承关系
为了让 cgroups 便于用户理解和使用,也为了用精简的内核代码为 cgroup 提供熟悉的权限和命名空间管理,内核开发者们按照 Linux 虚拟文件系统转换器(VFS:Virtual Filesystem Switch)的接口实现了一套名为cgroup的文件系统,非常巧妙地用来表示 cgroups 的 hierarchy 概念,把各个 subsystem 的实现都封装到文件系统的各项操作中。除了 cgroup 文件系统以外,内核没有为 cgroups 的访问和操作添加任何系统调用。
linux网桥
本文所说的网桥,主要指的是linux 虚拟网桥。
A bridge transparently relays traffic between multiple network interfaces. In plain English this means that a bridge connects two or more physical Ethernets together to form one bigger (logical) Ethernet
| network layer | iptables rules | ||
| func | netif_receive_skb/dev_queue_xmit | netif_receive_skb/dev_queue_xmit | |
| data link layer | eth0 | br0 | |
| eth1 | eth2 | ||
| func | rx_handler/hard_start_xmit | rx_handler/hard_start_xmit | rx_handler/hard_start_xmit |
| phsical layer | device driver | device driver | device driver |
通俗的说,网桥屏蔽了eth1和eth2的存在。正常情况下,每一个linux 网卡都有一个device or net_device struct.这个struct有一个rx_handler。
eth0驱动程序收到数据后,会执行rx_handler。rx_handler会把数据包一包,交给network layer。从源码实现就是,接入网桥的eth1,在其绑定br0时,其rx_handler会换成br0的rx_handler。等于是eth1网卡的驱动程序拿到数据后,直接执行br0的rx_handler往下走了。所以,eth1本身的ip和mac,network layer已经不知道了,只知道br0。
br0的rx_handler会决定将收到的报文转发、丢弃或提交到协议栈上层。如果是转发,br0的报文转发在数据链路层,但也会执行一些本来属于network layer的钩子函数。也有一种说法是,网桥处于forwarding状态时,报文必须经过layer3转发。这些细节的确定要通过学习源码来达到,此处先不纠结。
读了上文,应该能明白以下几点。
- 为什么要给网桥配置ip,或者说创建br0 bridge的同时,还会创建一个br0 iface。
- 为什么eth0和eth1在l2,连上br0后,eth1和eth0的连通还要受到iptables rule的控制。
- 网桥首先是为了屏蔽eth0和eth1的,其次是才是连通了eth0和eth1。
2018.12.3 补充:一旦一张虚拟网卡被“插”在网桥上,它就会变成该网桥的“从设备”。从设备会被“剥夺”调用网络协议栈处理数据包的资格,从而“降级”成为网桥上的一个端口。而这个端口唯一的作用,就是接收流入的数据包,然后把这些数据包的“生杀大权”(比如转发或者丢弃),全部交给对应的网桥。