
前言
分布式计算
spark 用于对 应用进行调度、分发及监控。 这里的应用由多个计算任务组成,运行在多个机器上。具体的说
- 任务调度,启动进程,启动其它主机的进程,来运行任务,并感知它们
- 定义进程的任务:接收、汇报(通用的) + 数据处理
- 数据处理的中间结果,对于单机则一直在内存中,对于分布式则要在主机之间流转
大数据跟迭代的密切关系,大数据一般是大量重复schema的数据。
mesos 提供了基本接口之后,上层可以运行 各种framework,比如marathon。spark 提供了rdd 等基本接口后,根据业务属性的不同,上层可以运行 各种frame work,比如spark stream等
从操作上直观感受 spark
单机模式
- 官网下载spark-2.3.0-bin-hadoop2.7.tgz包,解压
- 启动master,
spark-2.3.0-bin-hadoop2.7/sbin/start-master.sh - 可以在
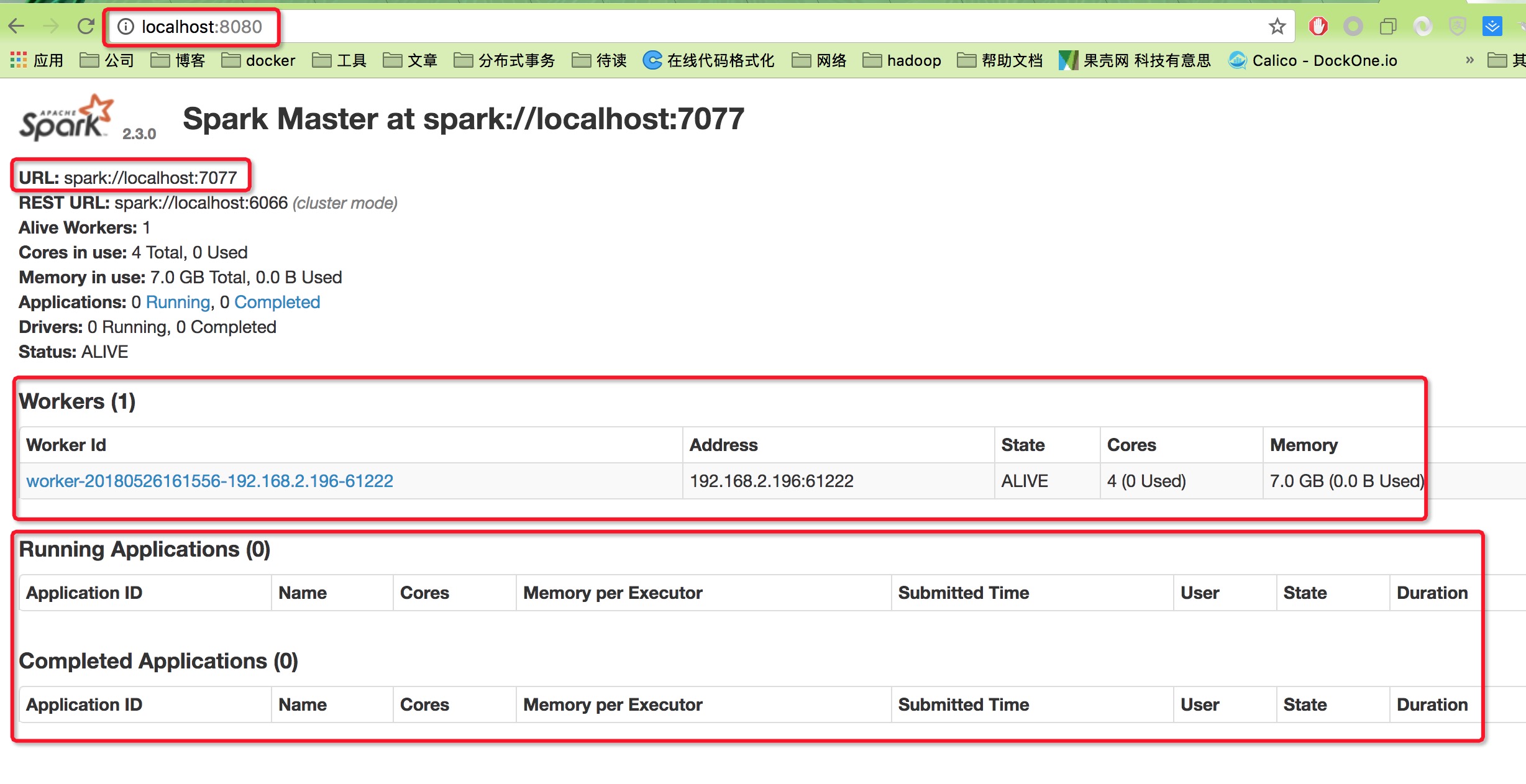
http://localhost:8080下查看 webui - 启动一个slave,
spark-2.3.0-bin-hadoop2.7/sbin/start-slave.sh spark://localhost:7077
从启动过程及web ui 上可以看到
- 跟mesos 很像,mesos 也是start-master,start-slave,mesos master 在5050 端口提供ui。启动一个slave后,worker 列表新增了一行元素,包括了地址、状态、cpu核数及内存。跟mesos 的agent 列表如出一辙
-
与hadoop2.x 类似,spark 也分为资源管理 + 任务调度
master slave yarn ResourceManager NodeManager mesos master salve spark master slave
交互式查询
传统的 通过提交代码与 spark 或 mapreduce 交互
一个mapreduce 任务执行的流程
- 编写代码
- 打成jar 包
- hadoop master 机器上
hadoop jar wordcount.jar input_arg output_arg
对应到 spark 则是
- 编写代码
bin/spark-submit --class xx.xx.wordcount target_jar input_arg out_arg
《Spark快速大数据分析》讲到spark shell时提到:使用其它shell工具,你只能用单机的硬盘和内存来操作数据,而Spark Shell可用来与分布式存储在许多机器的内存或者硬盘上的数据进行交互,并且处理过程的分发由spark自动控制完成(spark 速度快,速度快就意味着我们可以进行 交互式的数据操作)。
scala> val input = sc.textFile("/tmp/inputFile")
spark info...
scala> val words = input.flatMap(line => line.split(" "))
spark info...
scala> val counts = words.map(word => (word,1)).reduceByKey{case (x,y) => x+y}
spark info...
scala> counts.saveAsTextFile("/tmp/output")
spark info...
此处,运行完毕后,/tmp/output 是一个目录,其结构 跟 hdfs 是一样一样的,这跟选用saveAsTextFile方法有关系。
rdd——spark和MR的最大不同
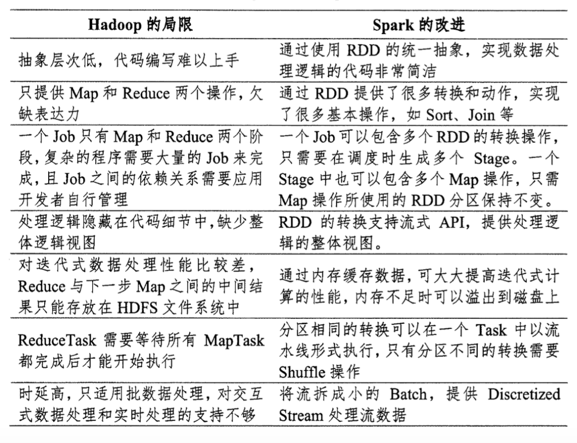
而RDD无需文件来存储中间结果,所以hadoop操作和RDD有所不同,RDD的形式可以更丰富。
- rdd 支持两种操作:转化操作和行动操作
- 惰性求值,在 行动操作开始之前,spark 不会开始 转换操作。
- 转化操作 会返回一个新的rdd,老的rdd 数据不会被改变
- rdd 根据转换操作 形成lineage graph,每当调用一个行动操作,lineage graph 都会从头开始计算
| 存储 | 提供操作 | |
|---|---|---|
| mapreduce | hdfs | map/reduce |
| sparck | RDD | transform,actiion |
- spark 更像是用户事先定义好:rdd从哪里来,到哪里去,数据如何变化。spark会对lineage graph进行类似sql语义的解析,然后融合数据的读取、转换和处理流程。
- 具体的说,数据库对外提供的抽象(或使用方式)是sql,在从物件文件读取数据前,先对sql进行完整的解析,先读哪,再读哪,是否有缓存,是否查索引,最终制定一个执行计划。
- spark对外的抽象是rdd代码,最终转化为rdd lineage graph,读取数据的时候,就可以决定哪一步可以过滤掉。
- 而hadoop因为是过程式的,数据的处理和数据的读写、中转是不相关的。仅从提供的 map和reduce 接口无法控制 数据的读取,哪怕后面的逻辑表明一半数据是废掉的,读取时依然要先全部读到内存。
代码的运行
资源管理器
此处指的是mesos master/salve, spark master/slave
基于mesos 写一个framework时,有明确的Scheduler、Executor sjarvie/mesos_example
class MesosScheduler implements Scheduler {
public static void main(){
FrameworkInfo framework = FrameworkInfo.newBuilder()
.setName("ZillabyteMesosExecutorExample")
.setUser("")
.setRole("*")
.build();
String mesosAddress = args[0];
// 指定Executor 的执行脚本`java -jar xx MesosExecutor.class`
String executorScriptPath = args[1];
System.setProperty("executor_script_path",executorScriptPath);
MesosScheduler scheduler = new MesosScheduler(1);
MesosSchedulerDriver driver = new MesosSchedulerDriver(scheduler, framework, mesosAddress);
driver.run();
}
}
class MesosExecutor implements Executor
public static void main(String[] args) {
MesosExecutor exec = new MesosExecutor();
new MesosExecutorDriver(exec).run();
}
}
Scheduler 作为给独立的进程,通过mesos 地址与 mesos 交互。Scheduler 知道 MesosExecutor 的启动命令,在合适的时机通过mesos 启动 Executor 执行。所以
- spark “Scheduler”,spark “Executor”,mesos master,mesos slave 都是独立的进程
- spark Scheduler 与 mesos master 交互,spark Executor 与mesos slave 交互,spark Scheduler 与 spark Executor 通过mesos 间接交互。
Spark 程序是如何跑起来的?资源管理器完成的任务是:
- 维护每台机器上的剩余资源量,并提供给应用,让应用能运行 Task
- 帮应用启动并运行 Executor 和 Scheduler
- 帮应用可靠地在 Scheduler 和 Executor 之间传递 Task 运行需要的信息,以及 Task 运行过程中的状态更新信息。
这里面含混了几个词:应用和 task。应用是 Scheduler、Executor和task 的总和。向mesos master 提交应用,mesos master 启动Scheduler,Scheduler 通过 mesos master 在node 上启动Executor,Executor 根据指令 运行task。
上层应用
spark 可以使用自己的 master/slave,也可以使用mesos 或 hadoop yarn
spark/mapreduce 作为 yarn/mesos 的上层,有自己的spark “Scheduler”和 spark “Executor”,对于一段spark 代码
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wordCount");
val sc = new SparkContext(conf)
val input = sc.textFile("/Users/nali/tmp/hello")
val words = input.flatMap(line => line.split(" "))
val counts = words.map(word => (word,1)).reduceByKey{case (x,y) => x+y}
counts.saveAsTextFile("/Users/nali/tmp/output")
}
}
它实际 是一个 独立运行的进程么?它和spark master如何交互呢?
Spark 学习: spark 原理简述与 shuffle 过程介绍
要点如下:
- wordcount 会对应一个driver 进程,executor 由 spark 框架提供。driver 和 Executor 就是 wordcount 应用的 “scheduler” 和 “executor”
- Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批Task,然后将这些Task分配到各个Executor进程中执行。
- Task是最小的计算单元(以线程方式执行)。前文提到资源管理器 就是帮你启动Scheduler、Executor,并提供通信服务,Executor 就是启动和监控task。于是,上层是抽象的rdd接口,下层是一个个task, 中间这种抽象层次的弥合 便通过driver (也就是Scheduler )实现。
Job/Stage/Task
上文提到,Executor 只是运行和监控task,spark driver 对业务层 提供了rdd 抽象,这个承上启下如何做到?
- rdd 有三个重要属性:partitions 列表、
compute(Partition):Iterator函数成员、对其它rdd 的依赖列表 - 以 RDD 为节点,依赖关系为边,最后会形成一个 DAG。理想情况下,一个DAG 的一条路径就是 对输入数据依次 执行transform1 ==> transform2 ==> action(一系列transform 加一个action 的结尾),这就是一个task 线程 run 方法的逻辑。比如
rdd.map(f1).filter(f2).count(),此时有几个分区,整个app 便有几个task。 - 一些情况下,transform 需要对数据 Shuffle(洗牌),比如
rdd.map(f1).filter(f2).reduceByKey(f3).count,因此就有了 Stage 的概念。接着上面 reduceByKey 的例子,分为两个 Stage,第一个 Stage 运行 N 个 Task,执行rdd.map(f1).filter(f2),第二个 Stage 执行reduceByKey(f3).count,运行 M(reduceByKey 之后的分区数) 个 Task - 一个stage的所有Task都执行完毕之后(所以叫stage),会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的Task的输入数据就是上一个stage输出的中间结果。
- 一个action(或者说transform1 ==> transform2 ==> action) 是一个job,一个应用会有多个job(比如既计数又求和
rdd.count(); rdd.reduce((x,y) => x + y))。
讲到这里,笔者觉得十分有必要研究下java8 Stream 的实现,因为实在有太多的相似之处,Stream 隐藏了 forkjoin,rdd隐藏了Scheduler、Executor、Task等组件以及job、stage、shuffle等概念,只是一个单机一个分布式罢了。
话说回来,java8 Stream 和 rdd 本质都是 Builder 模式。在build 模式中,调用setxxx 都是铺垫,最后build()(类似于spark rdd的行动操作)才是来真的。但Builder 模式 + 更高维度的抽象,加上函数式编程(setxxx 时可传入方法)的助力,便真让人眼前一亮了。