
简介
Demystifying memory management in modern programming languages是一个系列,建议细读。
一个优秀的通用内存分配器应具有以下特性:
- 额外的空间损耗尽量少
- 分配速度尽可能快
- 尽量避免内存碎片
- 缓存本地化友好。每个线程有自己的栈,每个线程有自己的堆缓存(减少对全局堆内存管理结构的争用)
- 通用性,兼容性,可移植性,易调试
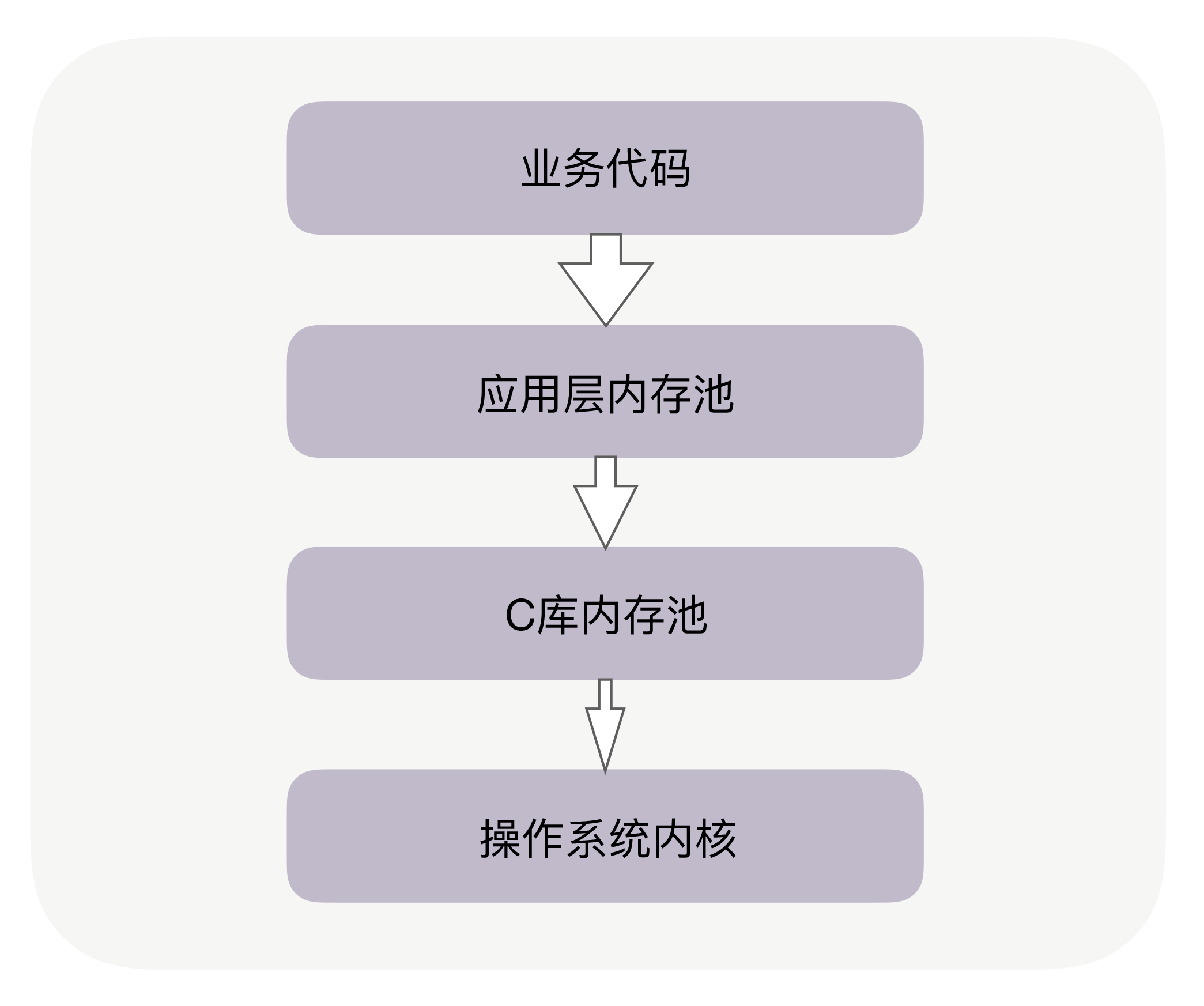
内存管理可以分为三个层次,自底向上分别是:
- 操作系统内核的内存管理
- glibc层使用系统调用维护的内存管理算法。glibc/ptmalloc2,google/tcmalloc,facebook/jemalloc。C 库内存池工作时,会预分配比你申请的字节数更大的空间作为内存池。比如说,当主进程下申请 1 字节的内存时,Ptmalloc2 会预分配 132K 字节的内存(Ptmalloc2 中叫 Main Arena),应用代码再申请内存时,会从这已经申请到的 132KB 中继续分配。当我们释放这 1 字节时,Ptmalloc2 也不会把内存归还给操作系统。
- 应用程序从glibc动态分配内存后,根据应用程序本身的程序特性进行优化, 比如netty的arena
进程/线程与内存:Linux 下的 JVM 编译时默认使用了 Ptmalloc2 内存池,64 位的 Linux 为每个线程的栈分配了 8MB 的内存,还(为每个线程?)预分配了 64MB 的内存作为堆内存池。在多数情况下,这些预分配出来的内存池,可以提升后续内存分配的性能。但也导致创建很多线程时会占用大量内存。
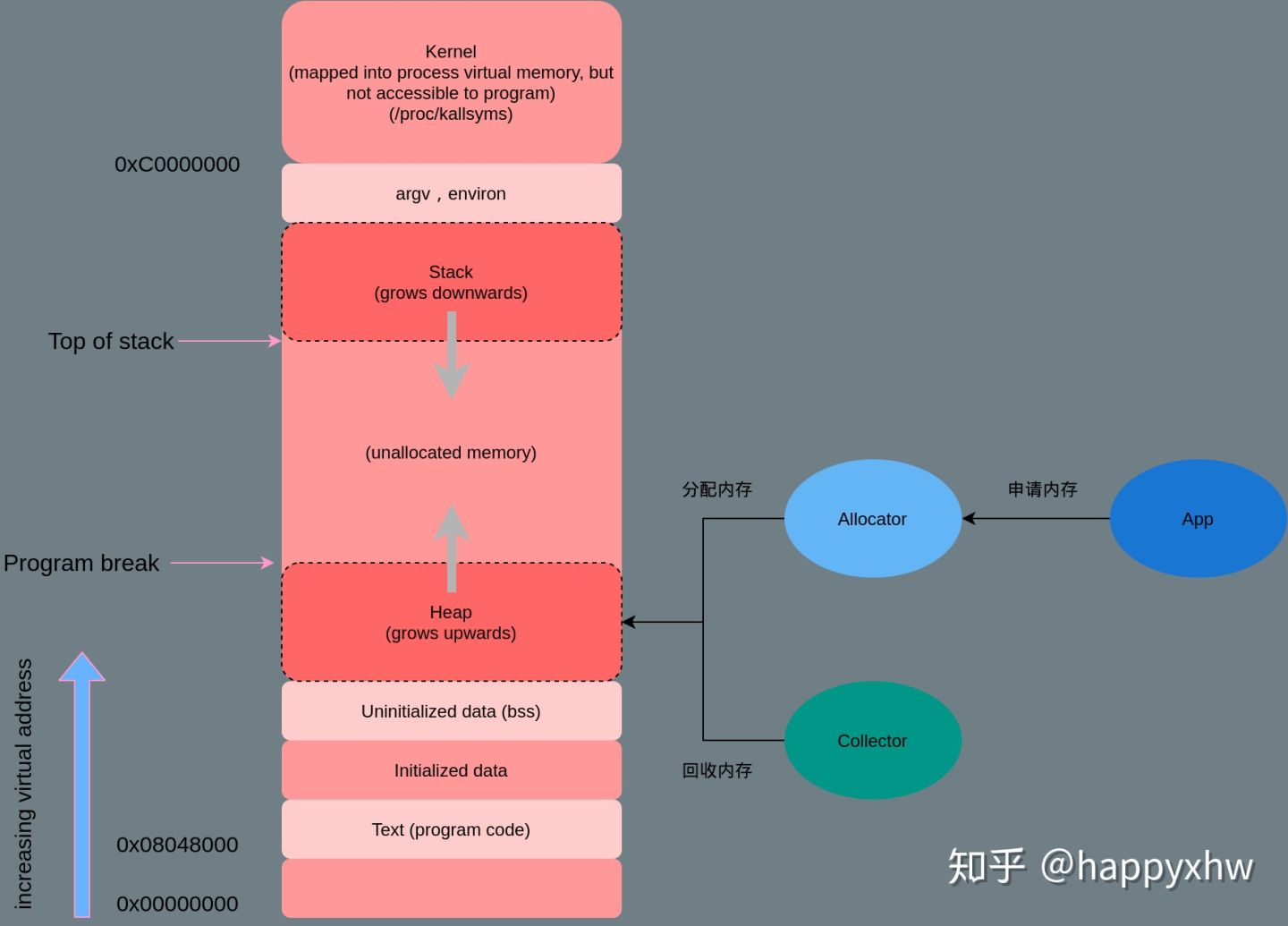
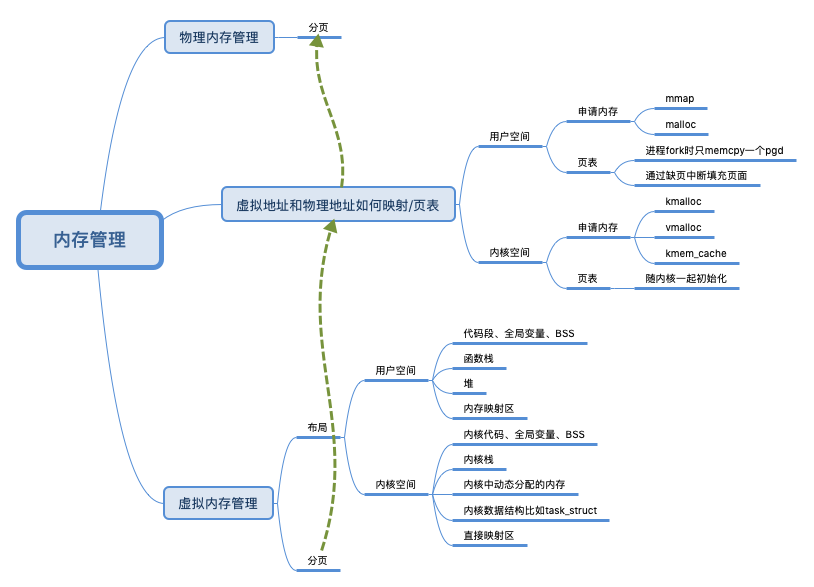
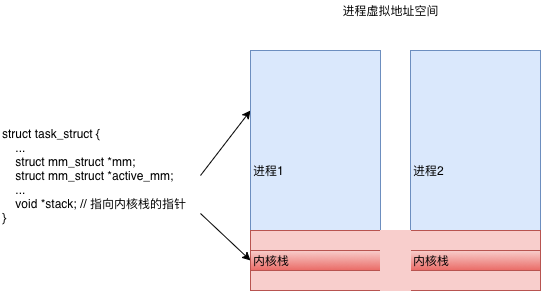
栈空间由编译器 + os管理。如果堆上有足够的空间的满足我们代码的内存申请,内存分配器可以完成内存申请无需内核参与,否则将通过操作系统调用(brk)进行扩展堆,通常是申请一大块内存。(对于 malloc 大默认指的是大于 MMAP_THRESHOLD 个字节 - 128KB)。但是,内存分配器除了更新 brk address 还有其他职责。其中主要的一项就是如何减少 内部(internal)和外部(external)碎片和如何快速分配当前块。我们该如何减少内存碎片化呢 ?答案取决是使用哪种内存分配算法,也就是使用哪个底层库。
操作系统
语言/运行时
进程在推进运行的过程中会调用一些数据,可能中间会产生一些数据保留在堆栈段,栈空间 一般在编译时确定(在编译器和操作系统的配合下,栈里的内存可以实现自动管理), 堆空间 运行时动态管理。对于堆具体的说,由runtime 在启动时 向操作 系统申请 一大块内存,然后根据 自定义策略进行分配与回收(手动、自动,分代不分代等),必要时向操作系统申请内存扩容。
从堆还是栈上分配内存?
如果你使用的是静态类型语言,那么,不使用 new 关键字分配的对象大都是在栈中的,通过 new 或者 malloc 关键字分配的对象则是在堆中的。对于动态类型语言,无论是否使用 new 关键字,内存都是从堆中分配的。
为什么从栈中分配内存会更快?由于每个线程都有独立的栈,所以分配内存时不需要加锁保护,而且栈上对象的size在编译阶段就已经写入可执行文件了,执行效率更高!性能至上的 Golang 语言就是按照这个逻辑设计的,即使你用 new 关键字分配了堆内存,但编译器如果认为在栈中分配不影响功能语义时,会自动改为在栈中分配。
当然,在栈中分配内存也有缺点,它有功能上的限制。
- 栈内存生命周期有限,它会随着函数调用结束后自动释放,在堆中分配的内存,并不随着分配时所在函数调用的结束而释放,它的生命周期足够使用。
- 栈的容量有限,如 CentOS 7 中是 8MB 字节,如果你申请的内存超过限制会造成栈溢出错误(比如,递归函数调用很容易造成这种问题),而堆则没有容量限制。
jvm
JVM1——jvm小结极客时间《深入拆解Java虚拟机》垃圾回收的三种方式(免费的其实是最贵的)
- 清除sweep,将死亡对象占据的内存标记为空闲。
- 压缩,将存活的对象聚在一起
- 复制,将内存两等分, 说白了是一个以空间换时间的思路。
go runtime
Visualizing memory management in Golang 有动图建议细读
中间件
netty arena
代码上的体现 以netty arena 为例 netty内存管理
kafka BufferPool
《Apache Kafka源码分析》——Producer与Consumer
redis
gc
第一开发语言是java 尤其是要注意:gc 以及 mark-and-sweep 不只是jvm 的,是所有mm language 的。
深入浅出垃圾回收(一)简介篇 是一个系列,垃圾回收的很多机制是语言无关的。
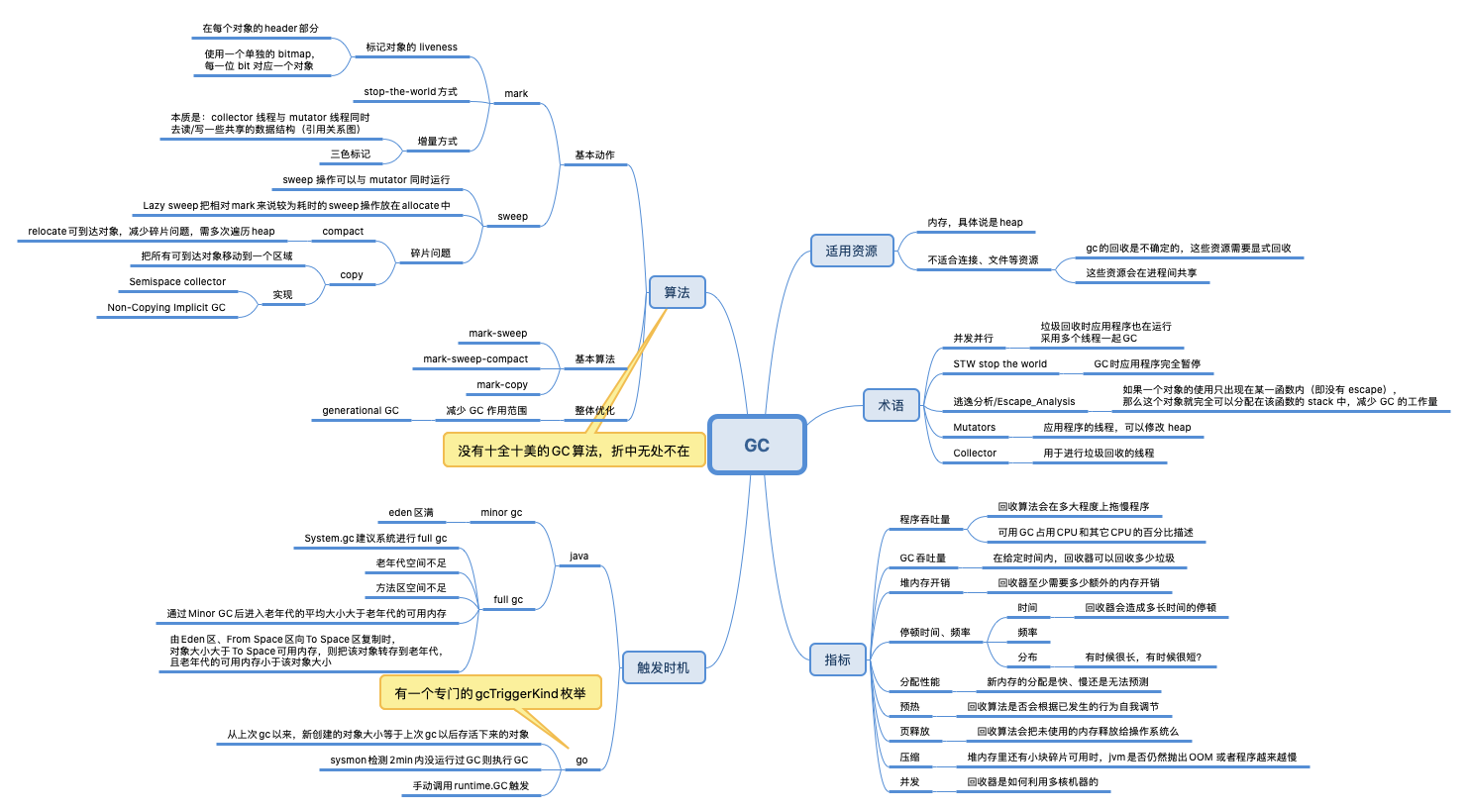
gc 策略
最基本的 mark-and-sweep 算法伪代码
mutator 通过 new 函数来申请内存
new():
ref = allocate()
if ref == null
collect()
ref = allocate()
if ref == null
error "Out of memory"
return ref
collect 分为mark 和 sweep 两个基本步骤
atomic collect(): // 这里 atomic 表明 gc 是原子性的,mutator 需要暂停
markFromRoots()
sweep(heapStart, heapEnd)
从roots 对象开始mark
markFromRoots():
initialize(worklist)
for each reference in Roots // Roots 表示所有根对象,比如全局对象,stack 中的对象
if ref != null && !isMarked(reference)
setMarked(reference)
add(worklist, reference)
mark() // mark 也可以放在循环外面
initialize():
// 对于单线程的collector 来说,可以用队列实现 worklist
worklist = emptyQueue()
//如果 worklist 是队列,那么 mark 采用的是 BFS(广度优先搜索)方式来遍历引用树
mark():
while !isEmpty(worklist):
ref = remove(worklist) // 从 worklist 中取出第一个元素
for each field in Pointers(ref) // Pointers(obj) 返回一个object的所有属性,可能是数据,对象,指向其他对象的指针
child = *field
if child != null && !isMarked(child)
setMarked(child)
add(worklist, child)
sweep逻辑
sweep(start, end):
scan = start
while scan < end
if isMarked(scan)
unsetMarked(scan)
else
free(scan)
scan = nextObject(scan)