
前言(持续更新)
基本架构
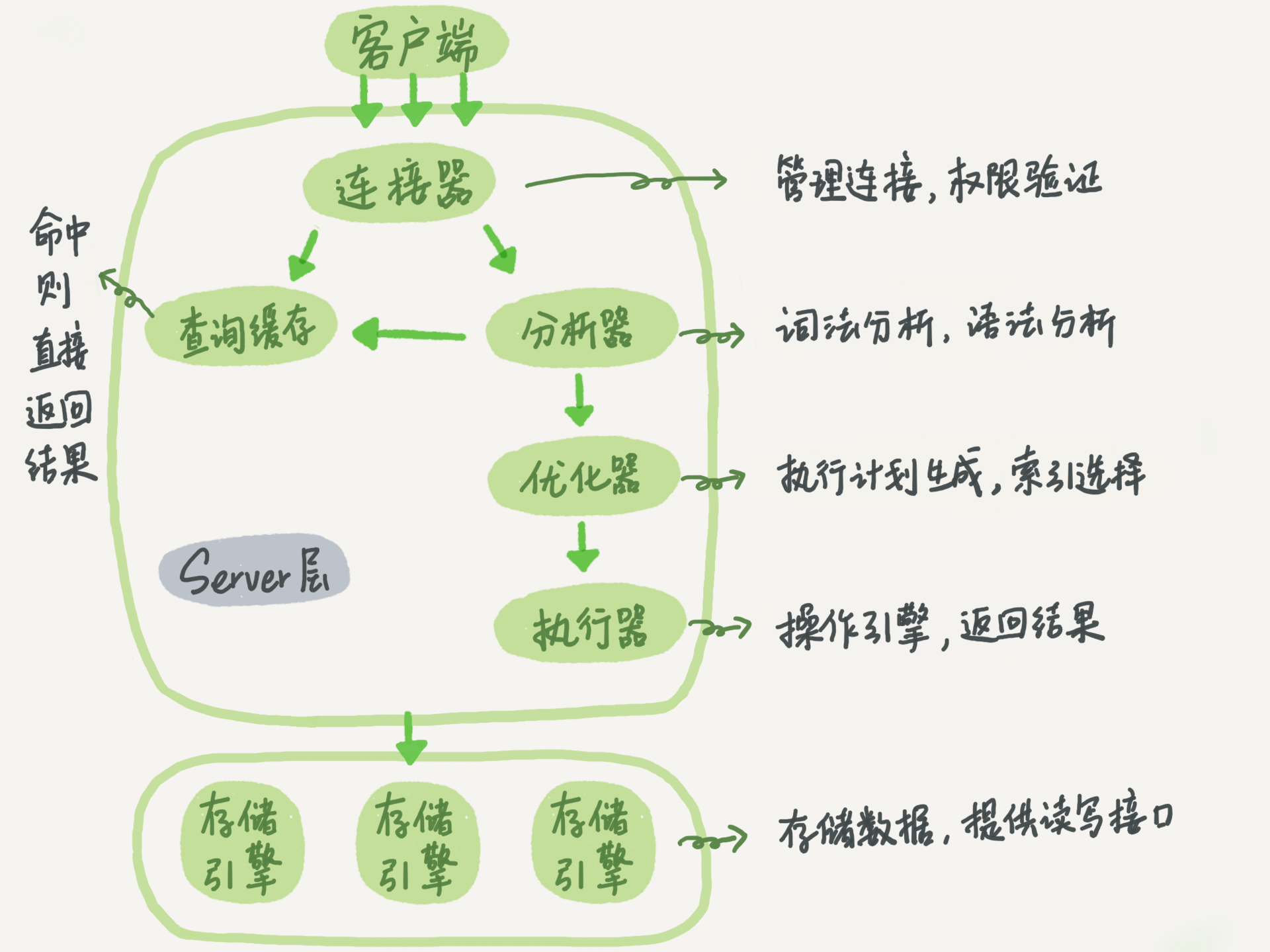
查询缓存:key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。大多数情况下我会建议你不要使用查询缓存,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。MySQL 8.0 版本直接将查询缓存的整块功能删掉了。
crash-safe 能力:保证即使数据库发生异常重启,之前提交的记录都不会丢失。日志系统
- Server层日志/binlog。最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。
- 存储引擎层日志。当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面。redo log 是固定大小的,如果redo log 写满了(write ops-checkpoint),就不能再执行更新操作了,得停下来将内存数据写到磁盘(把checkpoint 推进一下)。
| redo log | binlog | |
|---|---|---|
| 层次 | InnoDB 引擎特有的 | Server 层实现 |
| 内容 | 物理日志 记录的是“在某个数据页上做了什么修改” |
逻辑日志 记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1” |
| 写的方式 | 循环写 空间固定会用完 |
追加写 写到一定大小后会切换到下一个,并不会覆盖以前的日志 |
API
存储引擎 API以Handler类的虚函数的方式存在,可在代码库下的sql/handler.h中查看详细信息
class handler : public Sql_alloc{
...
// 创建、打开和关闭表
int create(const char *name, TABLE *form, HA_CREATE_INFO *info);
int open(const char *name, int mode, int test_if_locked);
int close(void);
virtual int rnd_init (bool scan); //初始化全表扫描
virtual int rnd_next (byte* buf); //从表中读取下一行
virtual int rnd_pos(uchar *buf, uchar *pos); // 读取pos 的数据,一般用于读取字段
// 索引操作
int ha_foo::index_init(uint keynr, bool sorted) //使用索引前调用该方法
int ha_foo::index_end(uint keynr, bool sorted) //使用索引后调用该方法
int ha_index_first(uchar * buf); //读取索引第一条内容
int ha_index_next(uchar * buf); //读取索引下一条内容
int ha_index_prev(uchar * buf); //读取索引前一条内容
int ha_index_last(uchar * buf); //读取索引最后一条内容
int index_read(uchar * buf, const uchar * key, uint key_len,
enum ha_rkey_function find_flag) //给定一个key基于索引读取内容
// 事务操作
int my_handler::start_stmt(THD *thd, thr_lock_type lock_type) //开始一个事务
int (*rollback)(THD *thd, bool all); //回滚一个事务
int (*commit)(THD *thd, bool all); //提交一个事务
// 对表加锁
int ha_example::external_lock(THD *thd, int lock_type) // 当客户端调用LOCK TABLE时,通过external_lock函数加锁:
}
索引
假设你的表中确实有一个唯一字段,比如字符串类型的身份证号,那应该用身份证号做主键,还是用自增字段做主键呢?
- 自增主键的插入数据模式,每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。而身份证号做主键,则往往不容易保证有序插入,这样写数据成本相对较高。
- 每个非主键索引的叶子节点上都是主键的值。如果用身份证号做主键,那么每个二级索引的叶子节点占用约 20 个字节,而如果用整型做主键,则只要 4 个字节。主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
- 典型的 KV 场景适合用业务字段直接做主键:只有一个索引;该索引必须是唯一索引。
基数(优化器选择索引时会参考基数值):一个索引上不同的值越多,这个索引的区分度就越好。而一个索引上不同的值的个数,我们称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好。我们可以使用 show index 方法,看到一个索引的基数。基数是一个估计值,MySQL 使用采样统计的方法得到索引的基数:InnoDB 会选择 N 个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。当变更的数据行数超过 一定数量时,会自动触发重新做一次索引统计。
select count(*) 优化:InnoDB 是索引组织表,主键索引树的叶子节点是数据,而普通索引树的叶子节点是主键值。所以,普通索引树比主键索引树小很多。对于 count(*) 这样的操作,遍历哪个索引树得到的结果逻辑上都是一样的。因此,MySQL 优化器会找到最小的那棵树来遍历。在保证逻辑正确的前提下,尽量减少扫描的数据量,是数据库系统设计的通用法则之一。
唯一索引和普通索引在查询性能上差别不大,在插入/更新性能上,如果相关数据页不在内存中时,还需将相关数据页加载到内存以判断是否违反了唯一性约束。
其它
事务支持是在引擎层实现的。
索引是在存储引擎层实现的。在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。根据叶子节点的内容,索引类型分为主键索引和非主键索引。
change buffer 对更新的加速(尤其是适用于写多读少的业务):当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InnoDB 会将这些更新操作缓存在 change buffer 中,这样就不需要从磁盘中读入这个数据页了(写时不用读磁盘,直到读数据时才读磁盘)。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行 change buffer 中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。将 change buffer 中的操作应用到原数据页,得到最新结果的过程称为 merge。除了访问这个数据页会触发 merge 外,系统有后台线程会定期 merge。在数据库正常关闭(shutdown)的过程中,也会执行 merge 操作。
如果要简单地对比redo log和change buffer 在提升更新性能上的收益的话,redo log 主要节省的是随机写磁盘的 IO 消耗(转成顺序写),而 change buffer 主要节省的则是随机读磁盘的 IO 消耗(避免更新时读取)。PS:redo log主要是为了crash-safe的