
简介
- 简介
- 为什么要学习新的语言
- Language Mechanics
- Data Structures
- Decoupling/解耦
- Error Handling
- defer
- Go Test 和 Benchmark
on the last 20 years, we have lived an incredible growth in computer science. Storage spaces have been increased dramatically,RAM has suffered a substantial growth, and cpu’s aare well simply faster. CPU industry has reached a limit. The CPU manufacturers are now shipping more cores on each computers. This situation crashes against the background of many systems programming languages that weren’t designed for multi-processor CPUs or large distributed systems that act as a unique machine.
our programers were bigger,more complex,more difficult to maintain and with a lot of room for bad practices. While our computers had more cores and were faster,we were not faster when developing our code neither our distributed applications. 代码规模规模越来越大,越来越容易出错。
大神的一份学习笔记 https://github.com/hoanhan101/ultimate-go
Golang 官网的FAQ 也经常会有一些“灵魂追问”的解答。
为什么要学习新的语言
通晓多种编程语言的程序员,真香?如果一种语言没有影响到你对编程的思考方式,你就用不着学它了。
我本来是Java方向的,为什么打算换“东家”呢?
- 程序员要多会一点,有人提出一个观点:即使这个语言过时了,学习一下也是很有必要的,因为这让你从另一个角度来观察问题,看到新的方式去解决问题。扩展的了解“什么死的,什么是可以变通的”。
- 多核化和集群化渐渐成为主流,而JAVA是上一个时代单机服务器时的产品,虽然它现在也在努力跟上潮流。
- JAVA语法还是不够简单。熟悉java多线程的人都知道,wait方法的调用必须在synchronized块中。并且,实现线程要继承Thread或者实现Runnable。总之,在java中开发多线程程序细节很多,能力要求也很高,是面试题的重要来源地。在未来的编程事业中,人们越来越关注实现业务本身,而实现业务所需的技术细节将主要由编程语言来实现。比如在Go语言中,实现一个线程将由一个关键字表示,学习的复杂性大大下降。
- 当然,决定语言发展趋势的因素有很多。若只考虑易用性,C语言早该回家抱孩子了。从长远讲,语言要么效率足够高,要么足够简单,处在中间状态的语言会很尴尬!
Language Mechanics
Syntax
Go语言设计有很多硬性规则,这让代码格式化、代码分析、编译、单元测试比较方便。
与常见编程语言的不同之处:
- Go的赋值方式很多,据说在Go后续的优化中会只支持一种赋值方式。PS:“达成一个目的只允许有一种方法”,就是这么直接。
- 赋值可以进行自动类型推断
- 在一个赋值语句中可以对多个变量进行同时赋值
- Go语言不允许隐式类型转换
- 别名和原有类型也不能进行隐式类型转换
- 支持指针类型,但不支持指针运算
- string 是值类型, 其默认初始化值为空字符串,不是nil
- Go语言没有前置++,–
- 支持按位清零运算符
&^ - Go语言循环仅支持关键字 for
- 不需要用break 来明确退出一个case,case 可以多项
- 可以不设定switch 之后的条件表达式, 在此种情况下, 整个switch 结构与多个if else 的逻辑作用等同。
- For break and continue, the additional label lets you specify which loop you would like to refer to. For example, you may want to break/continue the outer loop instead of the one that you nested in.
RowLoop: for y, row := range rows { for x, data := range row { if data == endOfRow { break RowLoop } row[x] = data + bias(x, y) } } - go 关键字对应到 java 就像一个无限容量的 Executor,可以随时随地 submit Runable
Data Structures
| go | java | |
|---|---|---|
| list | slice | ArrayList |
| map | map | HashMap |
| 线程安全map | sync.Map | ConcurrentHashMap |
| 对象池 | 对带缓冲的channel进行封装 | commons-pool中的ObjectPool |
数组
Deep Dive into Pointers, Arrays & SliceGo’s arrays are values rather than memory address.
var myarr = [...]int{1,2,3}
fmt.Println(myarr)
fmt.Println(&myarr)
//output
[1 2 3] // 打印的时候直接把值给打印出来了
&[1 2 3]
在 Go 中,与 C 数组变量隐式作为指针使用不同,Go 数组是值类型,赋值和函数传参操作都会复制整个数组数据。值类型还体现在
- 相同维数且包含相同个数元素的数组才可以比较
- 每个元素都相同的才相等
slice
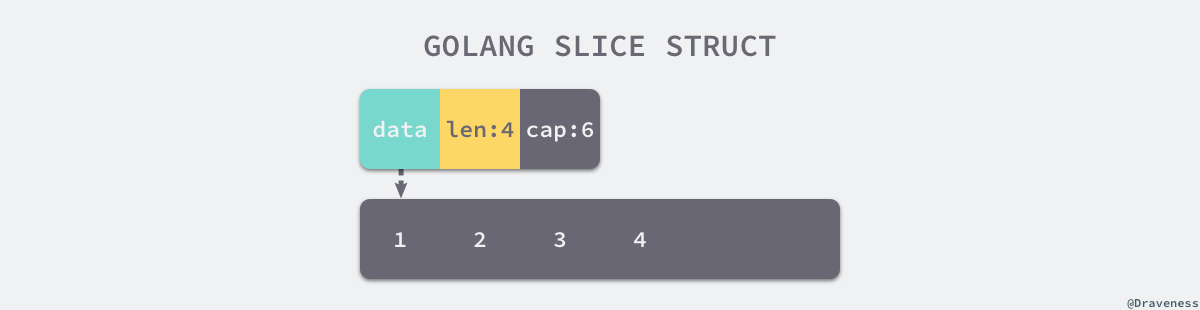
切片与数组的关系非常密切,切片引入了一个抽象层,提供了对数组中部分片段的引用,我们可以在运行区间可以修改它的长度,如果底层的数组长度不足就会触发扩容机制,切片中的数组就会发生变化,不过在上层看来切片是没有变化的,上层只需要与切片打交道不需要关心底层的数组变化。
// $GOROOT/src/runtime/slice.go
type slice struct {
array unsafe.Pointer // 指向底层数组的指针
len int // 可以用下标访问的元素个数
cap int // 底层数组长度
}
func makeslice(et *_type, len, cap int) unsafe.Pointer {...}
func makeslice64(et *_type, len64, cap64 int64) unsafe.Pointer {...}
// growslice handles slice growth during append.It is passed the slice element type, the old slice, and the desired new minimum capacity,and it returns a new slice with at least that capacity, with the old data copied into it.
func growslice(et *_type, old slice, cap int) slice {...}
func slicecopy(to, fm slice, width uintptr) int {...}
func slicestringcopy(to []byte, fm string) int {...}
扩容的本质过程:扩容实际上就是重新分配一块更大的内存,将原先的Slice数据拷贝到新的Slice中,然后返回新Slice,扩容后再将数据追加进去。
与java ArrayList相比,slice 本身不提供类似 Add/Set/Remove方法。只有一个builtin 的append和切片功能,因为不提供crud方法,slice 更多作为一个“受体”,与数组更近,与“ArrayList”更远。
// $GOROOT/src/builtin/builtin.go
// The append built-in function appends elements to the end of a slice. If it has sufficient capacity, the destination is resliced to accommodate the new elements. If it does not, a new underlying array will be allocated. Append returns the updated slice. It is therefore necessary to store the result of append, often in the variable holding the slice itself:
// slice = append(slice, elem1, elem2)
// slice = append(slice, anotherSlice...)
func append(slice []Type, elems ...Type) []Type
对于所有的 range 循环,Go 语言都会在编译期将原切片或者数组(下例中的arr)赋值给一个新的变量 ha,在赋值的过程中就发生了拷贝,所以我们遍历的切片已经不是原始的切片变量(arr)了。
func main() {
arr := []int{1, 2, 3}
for _, v := range arr {
arr = append(arr, v)
}
fmt.Println(arr)
}
$ go run main.go
1 2 3 1 2 3
之前将java 中的代码优化思路用到了 go 上,以为ss := make([]string, 5) 就是一个预分配了长度为5 的list,go 中这行代码 不仅分配了长度为5的空间,元素也赋值好了。
ss := make([]string, 5)
ss = append(ss, "abc")
fmt.Println(len(strs)) // 输出6
map
与常见编程语言的不同之处:
- 在访问的key不存在时,仍会返回零值,不能通过返回nil 来判断元素是否存在。
-
Map的value 可以是一个方法,与Go的Dock type 方式一起, 可以方便的实现单一方法对象的工厂模式。
m := map[int]func(op int) int{} m[1] = func(op int) int { return op } m[2] = func(op int) int { return op * op } m[3] = func(op int) int { return op * op * op } t.Log(m[1](2), m[2](2), m[3](2)) - Go的内置集合中没有Set实现, 可以map[type]bool
对于slice 来说, index, value 可以视为一个kv
for k,v := range map{}
for i,v := range slice{}
string
与常见编程语言的不同之处:
- string 是数据类型, 不是引用或指针类型
- string 是只读的byte slice,len函数 返回的是byte 数
- string的 byte 数组可以存放任何数据
Decoupling/解耦
函数
与常见编程语言的不同之处:
- 可以返回多个值
- 所有的参数传递都是值传递:slice,map,channel 会有传引用的错觉
- 函数是一等公民 ==> 对象之间的复杂关系可以由函数来部分替代
- 函数可以作为变量的值
- 函数可以作为参数和返回值
比如通过函数式编程来实现装饰模式,让一个函数具有计时能力
func timeSpent(inner func(op int) int) func(op int) int {
return func(n int) int {
start := time.Now()
ret := inner(n)
fmt.Println("time spent:", time.Since(start).Seconds())
return ret
}
}
嫌弃这个方法定义太长的话可以
type IntConv func(op int) int
func timeSpent(inner IntConv) IntConv {
return func(n int) int {
start := time.Now()
ret := inner(n)
fmt.Println("time spent:", time.Since(start).Seconds())
return ret
}
}
struct 和interface
go语言设计哲学go 没有像JAVA一样,宗教式的完全面向对象设计;完全面向对象设计就是一刀切的宗教式的设计,但其并不能很好的表述这个世界,这就导致其表现力不足,最后通过设计模式和面向切面等设计技巧来弥补语言方面的缺陷;go是面向工程的实用主义者,其糅合了面向对象的设计,函数式设计和过程式设计的优点;原来通过各种设计模式的设计通过函数、接口、组合等简单方式就搞定了;go有更多胶水的东西比如:全局变量、常量,函数,闭包等等,可以轻松的的把模块衔接和驱动起来; JAVA就好比:手里握着是锤子,看什么都是钉子,什么都是类的对象,这个和现实世界不符,类表示单个事物还可以,一旦表示多个事物及其交互,其表现力也就会遇到各种挑战。
Is Go an object-oriented language?Yes and no. Although Go has types and methods and allows an object-oriented style of programming, there is no type hierarchy. The concept of “interface” in Go provides a different approach that we believe is easy to use and in some ways more general. There are also ways to embed types in other types to provide something analogous—but not identical—to subclassing. Moreover, methods in Go are more general than in C++ or Java: they can be defined for any sort of data, even built-in types such as plain, “unboxed” integers. They are not restricted to structs (classes).
与常见编程语言的不同之处:
- 接口是非侵入性的/鸭子类型, 实现不需要依赖接口定义。Go 语言只会在传递参数、返回参数以及变量赋值时才会对某个类型是否实现接口进行检查。
- 不支持 “继承“,“子类”通过聚合“父类” 可以调用 ”父类“的方法,但无法重载,“子类”也无法直接赋值给 “父类”变量。
-
倾向于使用小的接口定义, 很多接口只包含一个方法。较大的接口定义,可以由多个小接口定义组合而成
type ReadWriter interface{ Reader Writer }
一个语言的类型系统 经常需要 一个“地位超然”的类型,可以表示任何类型,比如void* 或者 Object, 但真正在使用这个 类型的变量时,需要判断其真实类型,在类型转换后才能使用,所以会有类型断言的需求。
func xx(p interface){
if v,ok := p.(string);ok{
xxx
}
switch v:=p.(type){
case int:
case string:
}
}
程序员技术选型:写Go还是Java?Go 不是面向对象编程语言。Go 没有类似 Java 的继承机制,因为它没有通过继承实现传统的多态性。实际上,它没有对象,只有结构体。它可以通过接口和让结构体实现接口来模拟一些面向对象特性。此外,你可以在结构体中嵌入结构体,但内部结构体无法访问外部结构体的数据和方法。Go 使用组合而不是继承将一些行为和数据组合在一起。
Go 是一种命令式语言,Java 是一种声明式语言。Go 没有依赖注入,我们需要显式地将所有东西包装在一起。因此,在使用 Go 时尽量少用“魔法”之类的东西。一切代码对于代码评审人员来说都应该是显而易见的。Go 程序员应该了解 Go 代码如何使用内存、文件系统和其他资源。Java 要求开发人员更多地地关注程序的业务逻辑,知道如何创建、过滤、修改和存储数据。系统底层和数据库方面的东西都是通过配置和注解来完成的(比如通过 Spring Boot 等通用框架)。我们尽可能把枯燥乏味的东西留给框架去做。这样做很方便,但控制也反转了,限制了我们优化整个过程的能力。
Error Handling
与常见编程语言的不同之处:
- 没有异常机制。之前的语言 函数只支持一个返回值, 业务逻辑返回与错误返回会争用这一个“名额”,后来支持抛异常,算是解决了“争用”,但大量的try catch 引入了新的问题(至少Go作者不喜欢)。Go 支持了多返回值,从另一种视角解决了业务逻辑返回与错误返回“争用”问题。
- error 类型实现了error 接口
- 可以通过errors.New 来快速创建错误实例。
可以在代码中预创建一些错误var LessThanTwoError = errors.New("n should be not less than 2"),以便比对和复用。
| panic | os.Exit | |
|---|---|---|
| 指定defer函数 | 执行 | 不执行 |
| 输出当前调用栈信息 | 输出 | 不输出 |
| recover | 可以 兜住panic | 两者没有关系 |
defer
func main() {
startedAt := time.Now()
defer fmt.Println(time.Since(startedAt))
time.Sleep(time.Second)
}
$ go run main.go
0s
// 调用 defer 关键字会立刻对函数中引用的外部参数进行拷贝,所以 time.Since(startedAt) 的结果不是在 main 函数退出之前计算的,而是在 defer 关键字调用时计算的
func main() {
startedAt := time.Now()
defer func() { fmt.Println(time.Since(startedAt)) }()
time.Sleep(time.Second)
}
$ go run main.go
1s
defer 的前世今生未读完
type _defer struct {
siz int32 // 参数和结果的内存大小
started bool
openDefer bool
sp uintptr // 代表栈指针
pc uintptr // 代表调用方的程序计数器
fn *funcval // defer 关键字中传入的函数
_panic *_panic
link *_defer
}
defer 给我们的第一感觉其实是一个编译期特性,为什么 defer 会需要运行时的支持? 未完成
defer 的早期实现其实是非常的粗糙的。每当出现一个 defer 调用,都会在堆上分配 defer 记录,并对参与调用的参数实施一次拷贝操作,然后将其加入到 defer 链表上;当函数返回需要触发 defer 调用时,依次将 defer 从链表中取出,完成调用。当然最初的实现并不需要完美,未来总是可以迭代其性能问题。
在 Go 1.14 中,Dan Scales 作为 Go 团队的新成员,defer 的优化成为了他的第一个项目。他提出开放式编码 defer [Scales, 2019],通过编译器辅助信息和延迟比特在函数末尾处直接获取调用函数及参数,完成了近乎零成本的 defer 调用,在一定条件下让 defer 进化为一个仅编译期特性。
Go Test 和 Benchmark
我们测试一个函数的功能,就必须要运行该函数,而这往往是由main函数开始触发的。在大型项目中,测试一个函数的功能,总是劳驾main函数很不方便,于是我们可以使用go test功能。
假设存在a.go文件(文件中包含Add方法),我们只要在相同目录下创建a_test.go文件,在该目录下运行go test即可。(这将运行该目录下所有”_test”后缀文件中的带有“Test”前缀的方法)
package main
import (
"fmt"
"testing"
)
// 功能测试
func TestAdd(t *testing.T) {
t.Log("hello","world")
re := Add(3,4)
if re != 7{
t.Error("error")
}
assert.Equal(re,7)
}
// 性能测试
func BenchmarkAdd(b *testing.B) {
b.ResetTimer()
...// 测试代码
b.StopTimer()
}
